Volume 14, No. 3, Art. 5 – September 2013
Archivierungsstrategien für qualitative Daten
Andrea Smioski
Zusammenfassung: Durch die Ausweitung qualitativer Forschung gerät die Frage nach dem Umgang mit qualitativen Forschungsdaten immer mehr in den Fokus der Aufmerksamkeit. Große Archive verfügen mittlerweile über spezialisierte Einrichtungen für die Archivierung qualitativer Daten. Diese erfordern jedoch andere Archivierungsstrategien als quantitative Daten: Datendokumentation spielt eine größere Rolle für die Sekundärauswertung, Vertraulichkeitsfragen und datenschutzrechtliche Aspekte müssen stärker berücksichtigt werden etc. Ausgehend von verschiedenen Archivierungsstrategien für qualitative Daten wird in diesem Artikel aufgezeigt, wie eng Archivierungsprozesse mit Forschungsprozessen verknüpft sind und was das für den Lebenszyklus von Daten bedeutet. Als in diesem Zusammenhang wichtige Option wird das Konzept der living archives eingeführt: Durch Weiternutzung archivierter Daten können Bestände wachsen und langfristig an Wert gewinnen. Schließlich wird diskutiert, wie Datenarchivierung zur Güte qualitativer Forschung beitragen kann und welche Bedeutung Archiven in diesem Zusammenhang zukommt.
Keywords: qualitative Datenarchivierung; Qualitätssicherung; Gütekriterien; qualitative Daten; Anonymisierung; Datenarchiv; Datendokumentation; Digitalisierung; Metadaten; living archive; Österreich
Inhaltsverzeichnis
1. Kontext und Einführung
1.1 Archivierung qualitativer Daten in den Sozialwissenschaften
1.2 Situation in Österreich
2. Archivierungsstrategien
2.1 Akquiseprozess
2.2 Datendokumentation
2.3 Datenmanagement
2.4 Digitalisierung
2.6 Metadatenbeschreibung
2.7 Freigabe und Nutzung
2.8 Das Konzept des living archive
3. Wie Datenarchivierung zur Güte qualitativer Forschung beitragen kann
4. Resümee
1.1 Archivierung qualitativer Daten in den Sozialwissenschaften
Die Archivierung und Sekundäranalyse quantitativer Daten sind fest in den Sozialwissenschaften verankert. Das UK Data Archive (UKDA), 1967 gegründet, feierte 2007 sein 40-jähriges Jubiläum und CESSDA, das Council of European Social Science Data Archives, besteht seit den 1970er Jahren. Auch die Re-Analyse nationaler und internationaler Umfrageprogramme ist aus der Forschung nicht wegzudenken. Über statistische Ämter ist es möglich, auf nationale Umfragedaten zuzugreifen. In Österreich kann man über die Statistik Austria bspw. den EU-SILC1) oder auch den Mikrozensus2) kostenlos beziehen. Teils werden Umfragedaten auch eigens für die weitere Nutzung durch Dritte erhoben, so beispielsweise der European Social Survey3) oder der European Quality of Life Survey4). So stellt sich die Situation in der quantitativen Forschung dar, wie aber verhält es sich in der qualitativen Forschung? [1]
Die Debatte um die Archivierung und Bereitstellung qualitativer Daten ist wesentlich jünger und hat erst Mitte der 1990er Jahre begonnen. Die Gründung des britischen Archivs ESDS Qualidata im Jahr 1994, als integraler Bestandteil des UK Data Archives, stellt in dieser Agenda einen wichtigen Meilenstein dar. Als erstes Archiv für qualitative Daten wurde hier von Anfang an eine Vorreiterrolle eingenommen: Standards und Werkzeuge für die Aufbereitung, Archivierung und Weitergabe von Daten wurden vorgeschlagen und Initiativen zur Einrichtung qualitativer Archive in anderen Ländern gefördert und unterstützt. Anfangs lag das Augenmerk auf der Archivierung klassischer Studien, die für eine weitere Nutzung bewahrt werden sollten (CORTI & AHMAD 2000). Die Archivierung neuerer Studien wurde jedoch wichtiger, als das Economic and Social Research Council (ESRC) im Jahr 2000 eine Datenpolitik verlautbarte, die eine Archivierung von Forschungsdaten nach Projektende vorschreibt (ESRC 2000, 2010). Seither hat man sich bei Qualidata intensiv mit den Rahmenbedingungen der Archivierung qualitativer Daten auseinandergesetzt. Eigene Dokumentationsstandards wurden entwickelt, die sich von den bis dahin verwendeten Verfahren für die Beschreibung quantitativer Daten unterscheiden und die Besonderheiten qualitativer Daten berücksichtigen (KUULA 2000). Technische Möglichkeiten der Datenerfassung und Datenspeicherung wurden ebenso erörtert (MUHR 2000; PLAß & SCHETSCHE 2000) wie forschungsethische und datenschutzrechtliche Aspekte (CORTI, DAY & BACKHOUSE 2000; LEH, 2000). In ganz Europa führte diese Initiative zu einem Anschub der Diskussion und in Folge nach und nach zur Einrichtung qualitativer Archive auf nationaler Ebene und deren Vernetzung in einem europäischen Kontext. Machbarkeitsstudien wurden veranlasst, um auszuloten, wie es um den Verbleib vorhandener Daten bestellt ist und inwieweit ForscherInnen als DatengeberInnen und SekundärnutzerInnen infrage kommen (vgl. CORTI 2000; MEDJEDOVIC 2007; OPITZ & MAUER 2005; OPITZ & WITZEL 2005; SMIOSKI, MÜLLER, CASADO ASENSIO & KRITZINGER 2008). Mit dem Ziel, eine Kultur der Wiederverwendung zu verankern, wurden verschiedene Archivkonzepte umgesetzt und Bedingungen für die Datenabgabe und Datennutzung mit Stakeholdern aus der Wissenschaftslandschaft ausgehandelt. Über unterschiedliche Strategien der Datenbeschaffung wurde versucht, archivierte Datenbestände anzureichern und attraktive Möglichkeiten für eine Nachnutzung der Forschungsdaten zu schaffen. Nicht zuletzt wurde daran gearbeitet, eine Methodologie für die Wiederverwendung qualitativer Daten zu erarbeiten und zur Diskussion zu stellen (HEATON 2004; MEDJEDOVIC & WITZEL 2010). [2]
Trotz der Intensivierung der Diskussion und ihrer von Großbritannien ausgehenden Ausweitung auf viele andere europäische Länder5) fielen viele Bemühungen, am etablierten Umgang mit Forschungsdaten zu rütteln, auf dürren Boden. Forschungsdaten bleiben zumeist im Besitz der PrimärforscherInnen und sind daher nicht verfügbar für extensivere weitere Nutzung, für Vergleichsstudien oder als Ausgangsbasis für Folgeprojekte. Eine Ursache dafür ist sicher die schlechte finanzielle Grundausstattung der meisten kleineren Archive, die nur wenig Handlungsspielraum ermöglicht. Die Archivierung qualitativer Daten ist ein sehr zeit- und mitunter kostenaufwendiges Unterfangen. Ohne die entsprechenden Ressourcen können Fortschritte nur langsam erzielt werden, womit automatisch die Wahrnehmung der Archive durch eine interessierte wissenschaftliche Öffentlichkeit abnimmt. Datenpolitiken wie jene des ESRC sind selten, was sich zunehmend erschwerend auf Akquisebemühungen auswirkt. Auch fehlt aufseiten der ForscherInnen sehr häufig eine gute wissenschaftliche Praxis bei der Dokumentation und beim Management von Forschungsdaten, was eine Archivierung im Nachhinein stark behindert. Konkurrenz- und Zeitdruck sowie der fortwährende Zwang zur Einwerbung von Drittmitteln sind ihrerseits nicht förderlich dafür, Aufmerksamkeit für die Bewahrung von Daten aus abgeschlossenen Projekten oder die Nachnutzung archivierter Daten im Rahmen von neuen Forschungen zu schaffen. [3]
In den letzten Jahren und vor dem Hintergrund der zunehmenden Ausweitung qualitativer Forschung in vielen Disziplinen sowie der Ausdifferenzierung und Neuentwicklung von Verfahren der Datenerhebung gewinnt die Frage nach den Daten aber wieder an Bedeutung. Auch die Open-Access-Bewegung hat durch die Forderung nach frei zugänglichen wissenschaftlichen Forschungsdaten dazu beigetragen, der Diskussion um die Archivierung und Wiederverwendung qualitativer Daten ein neues Momentum zu geben. Es gibt erste Monografien, die sich mit dem Thema auseinandersetzen (u.a. HEATON 2004; MEDJEDOVIC & WITZEL 2010) sowie Schwerpunktausgaben bekannter Journals, die sich den Feldern Datenarchivierung und Sekundärnutzung widmen (u.a. BARBOUR & ELEY 2007; BERGMANN & EBERLE 2005; CORTI, WITZEL & BISHOP 2005; CORTI, KLUGE, MRUCK & OPITZ 2000; NEALE & BISHOP 2011; VALLES, CORTI, TAMBOUKOU & BAER 2011). Auch auf Konferenzen finden sich vermehrt Beiträge6) und es steht zur Diskussion, in Zeitschriftenbeiträgen auf archivierte Daten zu verlinken. Weitere Schritte sind nötig und können ihrerseits ein Stück weit dazu beitragen, dem Thema zu einem neuen Stellenwert zu verhelfen und Weiterentwicklungen zu ermöglichen. [4]
Die Dokumentation und Archivierung sozialwissenschaftlicher Forschungsdaten in Österreich hatte ihren Anfang in den 1980er Jahren. WISDOM, das Wiener Institut für sozialwissenschaftliche Dokumentation und Methodik, wurde im Jahr 1985 gegründet. In den Anfangstagen lag der Fokus des Instituts auf der Archivierung sozialwissenschaftlicher Umfragedaten. Dies gestaltete sich damals im Vergleich zu heute in vielerlei Hinsicht einfacher, da Datenschutzrichtlinien noch weniger weit entwickelt und auch administrativ-bürokratische Hindernisse geringer waren. Seit der Gründung hat WISDOM mehr als 1.000 quantitative Datensätze akquiriert, an die 600 davon sind für NutzerInnen digital erhältlich und für wissenschaftliche Zwecke frei zugänglich. [5]
Anfang 1990 trat WISDOM dem Rat der europäischen Datenarchive bei und fungiert seither als Schnittstelle für die Dokumentation und Archivierung sozialwissenschaftlicher Daten in Österreich. [6]
Sozialwissenschaftliche Daten umfassen jedoch nicht nur quantitatives Material. Vor dem Hintergrund der wachsenden Bedeutung qualitativer Forschung begann WISDOM im Jahr 2007 mit dem Aufbau eines qualitativen Datenarchivs. Zusätzlich zu den quantitativen Daten sollten auch qualitative Studien archiviert werden. Eine Machbarkeitsstudie (SMIOSKI et al. 2008), die der Gründung des qualitativen Archivs vorausging, ließ erwarten, dass sowohl in Bezug auf die Datenabgabe als auch auf die Datennutzung mit einer großen Unterstützung seitens der sozialwissenschaftlichen Community zu rechnen wäre (siehe Abbildung 1).7)
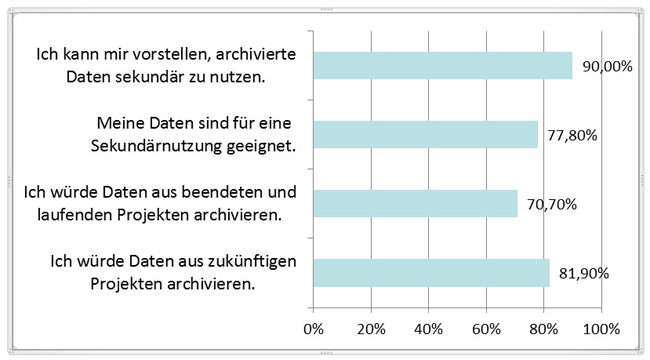
Abbildung 1: Unterstützung eines qualitativen Datenarchivs in Form von Datenabgaben und Datennutzungen durch österreichische
ForscherInnen [7]
Anfang 2008 wurde begonnen, bestehende und etablierte Standards für die Dokumentation und Aufbereitung quantitativer Daten auf ihre Tauglichkeit für die Archivierung qualitativer Daten hin zu überprüfen. Anhand erster Beispielstudien (u.a. KNOLL 2006; RICHTER 2007) wurden Archivierungsverfahren erprobt, adaptiert, weiter- und neu entwickelt. Besonders die Themen Datenschutz, Vertraulichkeit und Zugänglichkeit mussten grundlegend erarbeitet werden. Nachdem die infrastrukturellen Voraussetzungen für die Bearbeitung qualitativer Daten soweit geschaffen waren, stellte sich der Schritt in die Praxis eher enttäuschend dar. Dort, wo man anfänglich auf Zustimmung und Unterstützung seitens der ForscherInnen gestoßen war, wurde diese plötzlich relativiert und zurückgezogen. Ein ähnliches Phänomen beschreibt NELSON in seinem Artikel "Empty Archives": "Most researchers happily embrace the idea of sharing (...) [B]ut in practice those advantages often fail to outweigh researchers' concerns" (2009, S.160). In Österreich konnte sich bislang keine Kultur des data sharing etablieren. Beispiele für die Wiederverwendung, d.h. die Sekundäranalyse vorhandener Daten lassen sich bis dato in der qualitativen Forschung bis auf wenige Ausnahmen (LARCHER 2009) kaum finden, und Datenarchivierung wurde aufgrund fehlender Datenpolitiken seitens der Forschungsfördereinrichtungen lange nicht diskutiert. Erst mit der neuen und wichtigen Datenpolitik des Fonds für Wissenschaft und Forschung (FWF) zu Beginn des Jahres 2010 und durch die rasche Verbreitung der Open-Access-Bewegung beginnen sich sehr langsam auch im Hinblick auf die Offenlegung und das Weitergeben wissenschaftlicher Forschungsdaten Einstellungen zu verändern und Widerstände brüchig zu werden. WISDOM hat die Zeit seither intensiv genutzt, um genauere Richtlinien für die Dokumentation und das Management empirischer Forschungsdaten zu entwickeln. Hier gibt es langjährig tradierte Defizite, was dazu führt, dass selbst dort, wo Daten archiviert werden, viel Arbeitsaufwand für die Archivierung anfällt. Datenschutzrechtliche Fragen wurden adressiert und in Zusammenarbeit mit Forschungsteams erörtert. In diesem Bereich war es sehr wichtig für die Arbeit des Archivs, auf Bedenken und Widerstände seitens der ForscherInnen einzugehen und gemeinsam und fallspezifisch Lösungen zu erarbeiten. Seit der Gründung des qualitativen Datenarchivs 2007 konnten durch diese Arbeiten eine Reihe drittmittelgeförderter Projekte, Dissertationsprojekte und älterer Studien archiviert werden. [8]
Das Jahr 2010 stellte sich nicht nur durch die Datenpolitik des FWF als ein wichtiger Meilenstein für die Datenarchivierung in Österreich heraus. Darüber hinaus sicherten die Ministerien für Wissenschaft und Forschung und für Arbeit, Soziales und Konsumentenschutz WISDOM eine langfristige Förderung und Unterstützung zu.8) Dieses Übereinkommen gewährleistet, dass die notwendigen Mittel für den Erhalt der Infrastruktur zur Verfügung gestellt werden und die langfristige Bewahrung von Forschungsdaten garantiert werden kann. [9]
Im Folgenden sollen Archivierungsstrategien – verschiedene Schritte des Archivierungsprozesses – für qualitative Daten dargestellt werden: der Akquiseprozess (Abschnitt 2.1), in dessen Verlauf verschiedene Kriterien an einen Datensatz angelegt werden, um über die Tauglichkeit für eine Archivierung zu entscheiden; die Datendokumentation (Abschnitt 2.2), die sicherstellen soll, dass die Daten auch zu einem späteren Zeitpunkt verstanden und genutzt werden können und die eine Brücke zwischen Primär- und SekundärforscherInnen herstellen soll; das Datenmanagement (Abschnitt 2.3), das sich der Verwaltung, Organisation und Verarbeitung von Daten widmet; die Digitalisierung (Abschnitt 2.4), im Zuge derer ältere Datenbestände digital erfasst und damit vor endgültigem Verlust bewahrt und für Nachnutzungen gesichert werden; die Anonymisierung (Abschnitt 2.5), bei der zum Schutz der ForschungsteilnehmerInnen Daten verfremdet werden, um Rückschlüsse auf tatsächliche Personen und Ort zu verhindern; die Metadatenbeschreibung (Abschnitt 2.6), die standardisierte Daten (Metadaten) über eine Studie erfasst und NutzerInnen als Kataloginformation zugänglich macht und die Freigabe und Nutzung archivierter Daten (Abschnitt 2.7), bei der es um Zugriffsregelungen und Nutzungsmöglichkeiten archivierter Daten geht. Diese Ausführungen sollen veranschaulichen, wie eng Forschungs- und Archivierungsprozesse miteinander verknüpft sind und führen zum Schluss zum Vorschlag eines neuen Archivkonzepts, dem Konzept des living archive (Abschnitt 2.8). Dieses Konzept umfasst nicht nur die Koppelung von Forschungs- und Archivierungsprozessen, sondern auch jene von Primär- und Sekundärforschung. Datenbestände werden somit im Laufe der Zeit angereichert und können an Qualität gewinnen. Daran anknüpfend widmet sich ein letztes Kapitel der Frage, wie Datenarchivierung zur Güte qualitativer Forschung beitragen kann und welche Rolle Archive als Instanzen für die Qualitätssicherung in der qualitativen Forschung spielen können (Abschnitt 3). [10]
Unter Archivierungsstrategien sind in Zusammenhang mit sozialwissenschaftlichen Daten nicht ausschließlich Arbeiten zu verstehen, die nach dem Transfer der Daten an ein Archiv beginnen. Vielmehr müssen wichtige Arbeitsschritte und Entscheidungen bereits in der Projektplanung und im Zuge der Datenerhebung berücksichtigt und realisiert werden (ICPSR 2009, S.5).9) Datengenerierung und Datenarchivierung sind stark miteinander verzahnt und Letztere in hohem Maße davon abhängig, inwieweit eine spätere Archivierung bereits im Forschungsprozess mitgedacht wurde. In Übereinstimmung mit HUMPHREY et al. (2000, §11) lässt sich sagen: "[f]rom an archiving perspective, the whole orientation of the researcher requires an assessment of the future of the data products". In einer späteren Arbeit zusammen mit James JACOB geht Charles HUMPHREY einen Schritt weiter und beschreibt Datenarchivierung als einen Prozess, der den gesamten Lebenszyklus eines Datensatzes begleiten sollte und damit zu einem Teil der Forschungsmethode wird.
"Data archiving is a process, not an end state where data is simply turned over to a repository at the conclusion of a study. Rather, data archiving should begin early in a project and incorporate a schedule for depositing products over the course of a project’s life cycle and the creation and preservation of accurate metadata, ensuring the usability of the research data itself. Such practices would incorporate archiving as part of the research method" (JACOBS & HUMPHREY 2004, S.28). [11]
Nur wenn die aus der Dependenz des Archivierungsprozesses vom Forschungsprozess entstehenden Notwendigkeiten für die Organisation, Dokumentation und Aufbereitung der Daten im Verlauf des Forschungsprozesses angemessen berücksichtigt werden, können nach Abschluss des Projektes eine rasche Übergabe an und Aufbereitung der Daten durch das Archiv ermöglicht und Bestände qualitativ hochwertiger Forschungsdaten für Weiternutzungen zugänglich gemacht werden. Aus diesem Grund richtet sich der vorliegende Artikel nicht nur an ArchivarInnen, sondern auch an empirisch arbeitende ForscherInnen. [12]
Der Datenarchivierungsprozess beginnt mit der Datenakquise. In Österreich liegt eine große Erschwernis bei der Datenakquise in der Tatsache begründet, dass es derzeit kaum Datenpolitiken seitens der Forschungsförderungseinrichtungen gibt, die eindeutig regeln, was nach Ende der Projekte mit den erhobenen Daten passieren soll.10) Open Access auch für Forschungsdaten gewinnt zwar an Bedeutung, aber dort wo es Richtlinien gibt, wird deren Einhaltung entweder nicht überprüft oder aber die Richtlinien sind sehr allgemein gehalten. Eine Zusammenarbeit mit spezialisierten Archiven gibt es derzeit nicht. Die Akquise von Daten gestaltet sich daher für WISDOM sehr schwierig und zeitaufwendig und muss fast ausschließlich vom Archiv initiiert werden. [13]
Wenn Daten für eine Archivierung akquiriert werden können oder ForscherInnen Daten im Archiv deponieren wollen, wird eine Reihe von Kriterien an das Datenmaterial angelegt, um zu entscheiden, ob ein Datensatz für eine Archivierung geeignet ist oder nicht.11) Im Allgemeinen taugen Daten für eine Archivierung, wenn folgende Bedingungen erfüllt sind:
Der Datensatz sollte möglichst vollständig archivierbar sein, d.h. im Idealfall sollten alle Daten aus einem Projekt vollständig vorhanden sein. Bei einer Interviewstudie werden bspw. nicht nur die Gesprächstranskripte archiviert, sondern auch die entsprechenden Tonträger, Interviewprotokolle und Forschungsnotizen. Auch Codes und Memos, die im Verlauf der Auswertung von den ForscherInnen erstellt wurden, können archiviert werden und für SekundärnutzerInnen wichtige Metainformationen bereitstellen oder Übersichten ermöglichen.
Der Datensatz muss technisch und physisch für eine Archivierung geeignet sein. Dieser Punkt bezieht sich in erster Linie auf den Zustand von Daten wie bspw. die Qualität einer Tonaufnahme oder die Lesbarkeit von Forschungsnotizen. Bei älteren Daten kann es hier aber auch um Datenformate gehen. Nicht alle Daten sind digital gespeichert. Oft gibt es von Transkripten nur vergilbte hard copies oder von Tonaufnahmen nur alte Kassetten, deren Lebensdauer längst überschritten ist.
Ein sehr wichtiger Punkt betrifft die Dokumentation des Datensatzes. Diese muss ausreichend sein, um eine Archivierung und Sekundärnutzung zu ermöglichen (vgl. FINK 2000, §53). Gerade im Falle kleinerer Projekte mit nur wenigen MitarbeiterInnen wird viel projektspezifisches Wissen nicht dokumentiert, weil es ohnehin jederzeit abrufbar ist. Für die Archivierung der Daten muss aus den Kontextdokumentationen klar ersichtlich sein, wie das Projekt entstanden ist, Daten gesammelt, aufbereitet und analysiert wurden und in welchem institutionellen und wissenschaftstheoretischen Kontext das Projekt angesiedelt war.
Ein weiterer grundlegender Punkt, der vor einer Archivierung unbedingt geklärt sein muss, betrifft Copyrightfragen und datenschutzrechtliche Angelegenheiten. Das bedeutet in erster Linie, dass ForschungsteilnehmerInnen über die weitere Verwendung der Daten (u.a. Archivierung und Wiederverwendung) informiert sind und dieser schriftlich zugestimmt haben. Aber auch darüber hinausgehende rechtliche Fragen sind zu klären (z.B. rechtliche Ansprüche der AuftraggeberInnen einer Studie). So darf der ursprüngliche Verwendungszweck der Daten die Archivierung nicht behindern. Für wirtschaftlich oder politisch motivierte Auftragsstudien wird in der Regel bereits vonseiten der GeldgeberInnen, die oft auch RechteinhaberInnen sind, eine Weiterverwendung der Daten untersagt.
Ein letzter und nicht unwesentlicher Punkt bezieht sich auf die Qualität der Daten. Der Grundsatz für eine Archivierungsentscheidung lautet, dass die Daten nach den Regeln einer guten wissenschaftlichen Praxis erhoben und dokumentiert wurden. An dieser Stelle ist jedoch anzumerken, dass das Archiv bisher nur zu einem sehr geringen Maße tatsächlich die wissenschaftliche Qualität einer Erhebung beurteilt. Einerseits ist es so, dass DatengeberInnen, die Daten am Archiv deponieren, ermutigt und nicht abgewiesen werden sollen; dies vor allem, da die Idee der Archivierung und Weiternutzung von Forschungsdaten in Österreich noch so wenig etabliert ist. Andererseits verfügt WISDOM derzeit nicht über die notwendigen Ressourcen, um eine Instanz für die aktive Qualitätssicherung einzurichten. Dies würde meines Erachtens, wenn es nachhaltig erfolgen und in der wissenschaftlichen Community akzeptiert werden soll, ähnlich wie bei wissenschaftlichen Fachzeitschriften die Einführung gesonderter Review-Verfahren erfordern. Dies würde wiederum eine intensivierte Zusammenarbeit zwischen Archiv, sozialwissenschaftlich orientierten Fördereinrichtungen und ForscherInnen voraussetzen, außerdem die zielgerichtete Unterstützung der Archivierungsbestrebungen seitens der Fördereinrichtungen nicht nur in finanzieller Hinsicht, sondern auch im Sinne konkreter Kooperationen. Es müssten klare Regelungen zu Archivierungsverpflichtungen der ForscherInnen und Datenmanagementstandards getroffen und Maßnahmen zur Überprüfung dieser Vorgaben entwickelt werden. Nur durch eine derartige Zusammenarbeit kann eine Kultur für data sharing Fuß fassen und nachhaltig an Momentum gewinnen. Aktive Qualitätssicherung stellt einen wichtigen Verantwortungsschwerpunkt und Ausbaubereich der Archive in der Zukunft dar. Dazu gehört aber auch, Voraussetzungen und insbesondere Kompetenzen für erstklassiges Datenmanagement und hochwertige Datendokumentation zu schaffen. Es ist unerlässlich, dass Archive in diesen Bereichen mehr, aktiv und nutzerInnenfreundlich Expertise zur Verfügung stellen. [14]
Die umfassende Dokumentation eines Datensatzes ist eine der wichtigsten Voraussetzungen für die Archivierung bei WISDOM. Datendokumentation ist notwendig, um sicherzustellen, dass Daten auch zu einem späteren Zeitpunkt sinnvoll genutzt werden können (vgl. CORTI 2005b, §16; HOX & BEOIJE 2005, S.598; NIU 2009, S.5). Sie stellt die Brücke zwischen PrimärforscherInnen und SekundärnutzerInnen her, indem Letzteren Kontextinformationen zur Verfügung gestellt werden, die unerlässlich sind, um den institutionellen, theoretischen und methodischen Zugang der Studie, den Prozess der Datenerhebung, Entscheidungen im Verlauf des Forschungsprozesses oder Reflexionen der PrimärforscherInnen nachzuvollziehen. Die Machbarkeit einer Sekundäranalyse hängt maßgeblich von der Qualität der zur Verfügung gestellten Dokumentation ab (VAN DEN BERG 2005, §47), aber auch jenseits von Sekundärnutzungen sollte eine sorgfältige Datendokumentation grundsätzlich jeden Forschungsprozess begleiten (s.a. STEINKE 2000, S.324f.): So kann es auch innerhalb von Projektteams wichtig werden, auf Dokumentationen zurückgreifen zu können, die dabei helfen, Forschungssettings zu rekonstruieren, einmal geäußerte Wünsche von ForschungsteilnehmerInnen zu berücksichtigen, Interpretationsideen einzuarbeiten oder vereinbarte Projektentscheidungen umzusetzen. "From a methodological point of view", so Dominique JOYE, "documentation is a crucial element to ensure the quality of the data gathered" (2005, §6). [15]
Datendokumentation gestaltet sich am einfachsten, wenn sie von Anfang an im Forschungsprozess integriert ist. Schon bei der Planung einer Forschung sollte festgehalten werden, welche Kontextinformationen für das Projekt oder für SekundärnutzerInnen von Interesse sein können und in welcher Form sie erfasst werden sollen. Auch Kontextinformationen, die erst im Projektverlauf zutage treten oder relevant werden, müssen in die Dokumentation miteinbezogen werden. Es ist erforderlich, ProjektmitarbeiterInnen auf Dokumentationsstandards hinzuweisen und gegebenenfalls zu schulen, um die Dokumentation für den gesamten Projektverlauf konsistent zu gewährleisten. [16]
Eine gute Datendokumentation sollte in jedem Fall folgende Punkte beinhalten:
Kontextinformationen zum Projekt und zu den Daten: Projekthintergrund und Entstehung; Ziele und Verwertungszusammenhang des Projekts bzw. der Projektergebnisse; Hypothesen und forschungsleitende Fragestellungen; wichtige Publikationen, auf denen das Projekt aufbaut sowie Publikationen, die auf Basis der Daten aus dem Projekt entstanden sind;
Beschreibung der Methoden und des Prozesses der Datenerhebung/Datenaufbereitung: verwendete Methoden; Erhebungsinstrumente (Interviewleitfaden, Beobachtungsanleitung, Fragebogen usw.); Stichprobe; Datenerhebungsprozess (Feldarbeit, Interviewanleitungen, Interviewsettings); zeitliche und räumliche Abdeckung; Datenaufbereitung (Transkriptionssystem, Anonymisierung); verwendete Sekundärdaten und andere Quellen; Datenbereinigung und Fehlerkontrolle; Qualitätskontrolle;
Informationen zur Datenstruktur: Umfang des Datensatzes; Dateistruktur und Datenformate; Beziehungen zwischen den Dateien; Verzeichnisse und Fallübersichten;
Vertraulichkeit, Zugangsregelungen und Nutzungsbedingungen: Anonymisierungstechniken; Einverständniserklärungen; Zugangsbeschränkungen; Klärung rechtlicher Fragen. [17]
Über diese grundlegende Datendokumentation hinaus sind in der qualitativen Forschung insbesondere solche Informationen wichtig, die den SekundärforscherInnen helfen, Settings, Abläufe und Hintergründe einer Studie nachzuvollziehen. Solche Informationen sind oft implizit und werden nicht dokumentiert, können aber für spezifische Auswertungsverfahren in der qualitativen Tradition oder bestimmte Fragestellungen unerlässlich für den Verstehens- und Interpretationsprozess sein. Hinter dieser Herangehensweise steht die theoretische Grundannahme, dass Erkenntnis aus der reflexiven, interpretativen Praxis der Forschenden resultiert (MOORE 2007, §31). In den Worten von Janet HEATON: "In qualitative research, the interpretation of data is generally perceived to be dependent on the primary researcher's direct knowledge of the context of data collection and analysis obtained through their own personal involvement in the research" (2004, S.30). [18]
Aus diesem Grund hat die Dokumentation von Kontextinformationen in der qualitativen Forschungstradition eine gesteigerte Bedeutung, denn nur eine umfangreiche und ausführliche Dokumentation ermöglicht SekundärnutzerInnen, die Perspektive der PrimärforscherInnen nachzuvollziehen. WISDOM hält DatengeberInnen daher dazu an, über die oben skizzierte grundlegende Datendokumentation hinaus folgende weitere Informationen festzuhalten:
Begründung des Forschungsinteresses und Informationen zum Zustandekommen des Forschungsprojekts (persönliche Zugänge der AntragstellerInnen, wirtschaftliche oder politische Interessen und Hintergründe);
Informationen zur und Begründung der Methodenwahl sowie Beschreibung der Methode, des methodischen Herangehens und der methodologischen und theoretischen Grundannahmen;
Informationen zum Feldzugang und zur Auswahl der ForschungsteilnehmerInnen (Rekrutierung über persönliche Kontakte, Schneeballsystem, Gatekeeper) sowie etwaige Zugangsschwierigkeiten zum Feld;
Informationen zu den Settings, in denen Forschung stattfindet sowie Auffälligkeiten und Beobachtungen im Feld, die nicht Bestandteil von Interview- oder Beobachtungsprotokollen sind;
Informationen zur Beziehung zwischen ForscherInnen und ForschungsteilnehmerInnen (einmaliger oder wiederholter Kontakt, Vereinbarungen abseits dokumentierter Einverständniserklärungen) und insbesondere Hinweise auf sensible Inhalte in den Daten und wie mit diesen Daten umzugehen ist;
Informationen über Auffälligkeiten, Abweichungen, unerwartete Ereignisse, Planänderungen, Probleme (und wie mit diesen umgegangen wurde) sowie Dokumentation und Begründung von (strategischen) Entscheidungen im Forschungsprozess. [19]
Bei vielen Daten, die von WISDOM akquiriert werden, gestaltet sich die Aufbereitung für die Archivierung sehr aufwendig. Viel – für die PrimärforscherInnen aus dem Forschungszusammenhang abrufbares und daher selbstverständliches – Kontextwissen wird nicht dokumentiert. Daraus folgt, dass Daten- und Projektbeschreibungen oft mangelhaft sind und in einigen Fällen sogar die Rekonstruktion des Forschungsprozesses und damit natürlich auch die weitere Nutzung der Daten behindern, wenn nicht gar verunmöglichen (s.a. VAN DEN BERG 2005). [20]
Für WISDOM bedeutet die derzeitige Ausgangssituation häufig, dass eine Dokumentation der Daten retrospektiv erstellt werden muss, was teils, aber nicht immer durch die ForscherInnen unterstützt wird. Da viele Projekte schon abgeschlossen sind, gibt es seitens der ForscherInnen oft keine Ressourcen für eine nachträgliche Aufbereitung der Daten zur Archivierung, und bisweilen sind die durchführenden Personen auch nicht mehr verfügbar. In solchen Fällen versucht das Archiv, fehlende Informationen aus vorhandenen Projektunterlagen (Berichte, Publikationen, Anträge) zu rekonstruieren und die Daten auf diese Weise entsprechend zu dokumentieren. Das ist ein zeitintensives Unterfangen, das viele Ressourcen beansprucht und dazu führt, dass im qualitativen Archiv die Neuerfassung von Studien nur sehr langsam voranschreitet. Und natürlich ist klar, dass so viele, für Nachnutzungen wichtige Informationen nicht dokumentiert werden können. [21]
Gutes Datenmanagement ist eine weitere wichtige Voraussetzung für die Archivierung von Datensammlungen am WISDOM. Doch oft ist ForscherInnen unklar, was in Bezug auf ihre eigenen Projekte unter dem Begriff Datenmanagement genau zu verstehen ist. Datenmanagement in der Forschung umfasst alle Aspekte, die mit der Verwaltung, Organisation und Verarbeitung von Daten zusammenhängen. Datenmanagement erleichtert und verbessert den wissenschaftlichen Forschungsprozess, stellt eine hohe Datenqualität sicher und erhöht die Lebensdauer der Daten und damit die Möglichkeiten einer Wiederverwendung maßgeblich. Wichtige Bereiche umfassen:
Verwaltung der Daten: Im Zuge der Beantragung eines Forschungsprojektes sollte auch ein Datenmanagementplan erstellt werden, der genau festlegt, wo und wie die zu erhebenden Daten abgespeichert werden, wie einzelne Dateien zu benennen sind, was zusätzlich zu den erhobenen Daten an Kontext dokumentiert werden soll und in welcher Form, wer zuständig ist, für die Erfüllung des Datenmanagementplans zu sorgen, etc.12)
Ordnerstruktur, Datenformate und Software: Für eine übersichtliche elektronische Verwaltung von Projektdaten ist es sinnvoll, vor Projektbeginn eine klare Ordnerstruktur zu definieren, die es auch einer projektfremden Person ermöglicht, sich rasch einen Überblick darüber zu verschaffen, welche Daten wo abgespeichert sind. Auch sollten vorab einheitliche Formate bestimmt werden, die bei der Speicherung der Daten verwendet werden (z.B. txt, rtf, doc oder docx bei textbasierten Daten). Die Entscheidung für bestimmte Formate ist u.a. abhängig von der Software, die im Projekt verwendet wird. Analyseprogramme für qualitative Daten können bspw. oft nur rtf-Dokumente einlesen.
Datenspeicherung, Datensicherung und Backups: Gerade wenn mehrere MitarbeiterInnen an einem Projekt arbeiten, müssen Daten auch zentral abgespeichert werden. Der gesamte Datensatz sollte regelmäßig, d.h. im besten Fall einmal am Tag gesichert werden, sodass mindestens eine Sicherheitskopie des Datensatzes auf einem weiteren, an einem anderen Ort gelagerten Datenträger existiert. Außerdem sollte es von jeder Datei eine Masterversion geben, das ist eine (Original-) Version der Datei, die nicht verändert wird.
Archivierung und Langzeitsicherung der Daten: Der Datenmanagementplan sollte auch Überlegungen beinhalten, was nach Projektende mit dem Datensatz geschehen soll und wie die Daten langfristig gesichert werden können. Eine Archivierung der Daten ist empfehlenswert, da Archive neben der Verwaltung der Daten auch ihre Nachnutzung administrieren können.
Weitergabe und Veröffentlichung der Daten: Wenn die Daten einer Nachnutzung zur Verfügung gestellt werden, so müssen bestimmte Vorkehrungen getroffen werden. Schon im Zuge der Datenerhebung sollten bspw. InterviewpartnerInnen über die weitere Verwendung der Daten aufgeklärt und schriftliche Einverständniserklärungen verwendet werden. Die Daten sollten außerdem anonymisiert werden (siehe Abschnitt 2.5). Des Weiteren ist es sinnvoll, Verzeichnisse zu erstellen, die einen Überblick über die vorhandenen Daten (z.B. Interviews) geben. Schließlich gilt es auch zu überlegen, für welche Zwecke die Daten freigegeben werden sollen (siehe Abschnitt 2.7).
Sicherheit vertraulicher Daten: Werden in einem Projekt vertrauliche Daten erhoben, so muss geregelt werden, wie mit diesen Daten im Projektverlauf bzw. nach Projektende zu verfahren ist (z.B. klare Richtlinien auch für das Projektteam, wie und wo die Daten gespeichert werden dürfen, Entfernen einzelner Abschnitte aus Interviews etc.).
Rechteverwaltung: In Zusammenarbeit mit den AuftraggeberInnen der Forschung sollte geklärt werden, wer die Rechte an den Daten hat (FördergeberIn, ProjektleiterIn, durchführendes Institut). Auch gegenüber den ForschungsteilnehmerInnen müssen grundsätzlich die Rechte an den Daten geklärt werden (zum Urheberrecht am gesprochenen Wort siehe SMIOSKI 2011c, S.227). Dies kann im Zuge der schriftlichen Einverständniserklärung erfolgen.
Kompatibilität und Datensynchronisation: Die Technik und Software, mit der wir arbeiten, verändert sich heutzutage sehr schnell. Das führt dazu, dass mitunter ältere Daten gar nicht mehr gelesen werden können (bspw. Audiokassetten, Disketten, ältere Datenformate etc.). Eine wichtige Aufgabe von Archiven ist daher, Daten regelmäßig auf ihre Kompatibilität mit aktuellen Programmen zu prüfen und sie im Fall des Falles in kompatible Formate zu konvertieren (siehe auch Abschnitt 2.4). [22]
Gutes Datenmanagement ist nicht nur einer etwaigen Archivierung und Wiederverwendung von Daten zuträglich, sondern sollte die Grundlage für jede Forschung sein, da es die Qualität eines Datensatzes und damit auch der Ergebnisse bedeutend anheben kann: Wenn Daten adäquat verwaltet, aufbewahrt und dokumentiert sowie ihre Vollständigkeit und Integrität laufend geprüft werden, sind die besten Voraussetzungen geschaffen, um hochwertige Forschungsdaten und empirisch nachvollziehbare Ergebnisse zu produzieren. Auch PrimärforscherInnen profitieren von gutem Datenmanagement, sei es hinsichtlich einer effizienteren Zusammenarbeit in (großen) Teams mit vielen Daten, sei es mit Blick auf die Auffindbarkeit und damit das Einbeziehen von Informationen im aktuellen Projektverlauf oder auch hinsichtlich etwaiger Re-Analysen der eigenen Daten zu einem späteren Zeitpunkt. [23]
Dennoch gilt für das Datenmanagement Ähnliches wie für die Datendokumentation: In der Forschungspraxis wird oftmals darauf verzichtet. Das liegt meines Erachtens vorwiegend daran, dass es bei Fragen des Datenmanagements in erster Linie um logistische und (verwaltungs-) technische Aufgaben geht, die vom genuin wissenschaftlichen Arbeitsprozess in der Praxis weitgehend ausgeklammert werden. Viele Tätigkeiten, so die Datensicherung, die Datensynchronisation oder die Zugriffsverwaltung, erfordern ein gewisses Ausmaß an technischem Know-how. Derartige Kompetenzen fehlen aber oft bei wissenschaftlichem Personal und werden in der universitären Ausbildung auch selten vermittelt. Andere Tätigkeiten, vor allem die Verwaltung der Daten im Hinblick auf die Kontrolle von Masterversionen oder das Erstellen von Ordnerstrukturen und Übersichten, erfordern kontinuierliche Aufmerksamkeit und Berücksichtigung und gehen im Erhebungs- und Auswertungsprozess oft unter. [24]
Das macht eine Archivierung in der Praxis oftmals schwer und in den meisten Fällen zeitaufwendig. Vielfach fehlen bei der Übergabe der Daten einzelne Datenbestände, die bei mittlerweile anderweitig beschäftigten ProjektmitarbeiterInnen lokal gespeichert sind und nicht zentral verwaltet werden. Bei großen und eventuell internationalen Projektteams kann es schwer bis unmöglich sein, im Nachhinein alle Daten zusammenzutragen, insbesondere wenn die Daten bereits vernichtet wurden. Oft gibt es von einer Datei mehrere Versionen, weil verschiedene ForscherInnen damit gearbeitet und immer wieder neue Versionen der Datei abgespeichert haben. Die endgültige Datei lässt sich oft nicht rekonstruieren und unveränderbare Masterversionen werden selten erstellt. Wenn mehrere TranskribentInnen oder ProtokollantInnen in einem Projekt tätig waren, wurden Dateien wie bspw. Interviewtranskripte möglicherweise in verschiedenen Formaten und Formatierungen und mit unterschiedlichen Benennungskonventionen abgespeichert. Zum Teil wird innerhalb eines Projekts mit unterschiedlichen Transkriptionssystemen transkribiert, zu denen aber keine Informationen vermerkt werden. In vielen Fällen fehlen Kontextdokumentationen zur Datenerhebung völlig, weil es keine Datenmanagementpläne gibt, die für alle ProjektmitarbeiterInnen einheitliche Standards für die Datenerhebung und Aufbereitung festlegen. Nach Projektende gibt es meist niemanden mehr, der für eine Archivierung verantwortlich ist und als Ansprechperson für das Archiv über alle notwendigen Metainformationen zu dem Projekt verfügt. [25]
Um diese Situation in Zukunft zu verbessern, ist WISDOM bemüht, aktiv Wissensvermittlung in den Bereichen Datendokumentation und Datenmanagement zu betreiben. Dies erfolgt einerseits über die umfangreiche und übersichtliche WISDOM Datenarchiv-Homepage, auf der wesentliche Informationen für ForscherInnen abrufbar sind, aber auch über persönliche Beratungsgespräche mit EinzelforscherInnen und Projektteams sowie über regelmäßig stattfindende ExpertInnen-Workshops zu den Themen Datendokumentation, Datenmanagement und Sekundärnutzung. WISDOM möchte ForscherInnen dazu animieren, beim Management ihrer Daten in Zukunft bereits im Projektverlauf bestimmte Standards einzuhalten. Dadurch minimiert sich der Extra-Aufwand bei der Archivierung der Daten erheblich. [26]
Neben neueren Studien werden am WISDOM auch ältere qualitative Studien erfasst. Die Archivierung erfolgt in diesen Fällen unter dem Gesichtspunkt, die Datenbestände vor endgültigem Verlust zu bewahren und für Nachnutzungen zu sichern. Ein Großteil der Datenbestände – vorwiegend Interviewstudien – stammt aus den 1980er Jahren und wurde im ursprünglichen Projektkontext nicht digital abgespeichert. Interviewaufnahmen liegen auf Audiokassetten und in späteren Jahren auf Mikro-Kassetten und Mini-Discs vor. Interviewtranskripte wurden mit Schreibmaschine geschrieben und sind im Papierformat in unterschiedlichster Qualität verfügbar. Teils wurden bereits digitale Dokumente angefertigt, diese müssen aber erst von Floppy Disks und alten Festplatten gesichert und in neue Formate migriert werden, bevor sie für eine Archivierung weiter bearbeitet werden können. In einigen Fällen liegen auch handschriftliche Forschungsnotizen und Protokolle vor, und auch altes Bildmaterial ist stellenweise vorhanden. [27]
Die Digitalisierung dieser Bestände nimmt am WISDOM einen hohen Stellenwert ein, da viele alte Datenformate eine sehr kurze Lebensdauer haben und die Daten nur durch eine Digitalisierung langfristig gesichert werden können. Audioformate werden digital eingespielt und nachbearbeitet, um Rauschen und Nebengeräusche auf ein Minimum zu reduzieren und die Aufnahmen für Nachnutzungen zu optimieren. Textdokumente werden gescannt und mit einer OCR13)-Texterkennung überarbeitet. Dadurch wird der eingescannte Text maschinenlesbar, was den Vorteil hat, dass die Daten auch von Analysesoftware und Auswertungsprogrammen für qualitative Daten gelesen werden können. Allerdings liefert die Texterkennung mitunter sehr fehlerhafte Schriftstücke, da einzelne Zeichen nicht erkannt oder falsch übersetzt werden. Dadurch fallen bei der Digitalisierung von Textdaten weitere Aufbereitungsarbeiten an, im Zuge derer Fehler korrigiert, Formatierungen erstellt und Anonymisierungen vorgenommen werden. Bildmaterial und handschriftliche Notizen werden gescannt und stehen NutzerInnen im PDF-Format digital zur Verfügung. [28]
2.5 Anonymisierung
Im Mittelpunkt sozialwissenschaftlicher Untersuchungen stehen Menschen, und gerade qualitative Daten beinhalten in vielen Fällen sensible Informationen über befragte Personen, aber auch über deren persönliches Umfeld (CORTI, DAY et al. 2000, §12). SozialwissenschaftlerInnen verpflichten sich, die Vertraulichkeit der Personen, die sie im Zuge ihrer Untersuchungen befragen zu gewährleisten, so der Code of Ethics, den die International Sociological Association herausgegeben hat (ISA Code of Ethics, 2.3.). Das betrifft in den meisten Fällen Befragte, die sich zu einem Interview bereit erklären, aber auch Gruppen, Organisationen und andere Einheiten, zu denen Informationen in administrativen Zusammenhängen oder anderen Kontexten aufgezeichnet werden. Schon für PrimärforscherInnen ergeben sich oftmals Probleme, wie mit der Vertraulichkeit, die den Befragten zugesichert wurde, am besten umzugehen ist. Die Situation verkompliziert sich, wenn es darum geht, das Datenmaterial projektfremden ForscherInnen weiterzugeben (vgl. HOPF 2005, S.597). Da die Einbindung in den Forschungsprozess nicht gegeben ist, fehlt SekundärforscherInnen das Wissen um sensible Inhalte in den Daten und demnach auch die Möglichkeit, im Umgang mit Forschungsergebnissen etwaige Risiken für ForschungsteilnehmerInnen abschätzen zu können. Besonders brisant sind in diesem Zusammenhang qualitative Daten, die z.B. zu Grenzbereichen der Legalität erhoben werden (OPITZ & MAUER 2005, §15). Hinzu kommt, dass in der qualitativen Forschung Forschende insofern eine besondere Bedeutung haben, als sie selbst zum "Instrument der Erhebung" werden (vgl. MEDJEDOVIC 2007, S.205). Das Ausmaß der Vertrauensbeziehung, das im Verlauf des Forschungsprozesses zu den befragten Personen aufgebaut wird, bestimmt sehr wesentlich die Qualität der erhobenen Daten. Vor dem Hintergrund der daraus entstehenden Verantwortlichkeit fürchten ForscherInnen in Hinblick auf eine Sekundärnutzung ihrer Forschungsdaten Vertraulichkeitsverletzungen gegenüber den Befragten sowie den Missbrauch ihrer Daten (MEDJEDOVIC 2007; SMIOSKI et al. 2008, S.52, 124). [29]
Erschwerend ist in diesem Zusammenhang, dass es in Österreich nicht immer üblich ist, ForschungsteilnehmerInnen Einverständniserklärungen zur Nutzung der Daten im Projektkontext bzw. darüber hinaus zur Archivierung und Weiterverwendung von Forschungsdaten auszuhändigen (SMIOSKI, RICHTER & BENDL 2009, S.38). Bei Daten, die zur Archivierung angeboten werden, kann also nicht immer vorausgesetzt werden, dass die befragten Personen über die etwaige Nutzung ihrer Daten durch andere ForscherInnen und daraus entstehende Risiken aufgeklärt sind. Auch die rechtliche Grundlage ist in Österreich in Bezug auf wissenschaftliche Forschungsdaten, deren Archivierung und wissenschaftliche Wiederverwendung nicht sehr weit gediehen. Allein das Datenschutzgesetz (DSG) 2000 bietet einige Anhaltspunkte, aber keine rechtlich eindeutigen Aussagen. So dürfen in Österreich jene Daten für wissenschaftliche Zwecke verwendet werden, "die (1) öffentlich zugänglich sind oder (2) der Auftraggeber für andere Untersuchungen oder auch andere Zwecke zulässigerweise ermittelt hat oder (3) für den Auftraggeber nur indirekt personenbezogen sind" (§46, Abs.1). Ansonsten gilt, dass Daten nur "(1) gemäß besonderen gesetzlichen Vorschriften oder (2) mit Zustimmung des Betroffenen oder (3) mit Genehmigung der Datenschutzkommission" verwendet werden dürfen (§46, Abs.2). [30]
Liegen keine Einverständniserklärungen von ForschungsteilnehmerInnen vor, werden die Daten von WISDOM daher nur anonymisiert zur Weiternutzung angeboten. MEDJEDOVIC und WITZEL unterscheiden zwischen formaler, faktischer und absoluter Anonymisierung (2010, S.75). Bei der formalen Anonymisierung werden direkte Identifikatoren wie Personen- und Firmennamen oder Adressen entfernt. Die faktische Anonymisierung geht einen Schritt weiter: Hier werden auch Angaben verändert oder reduziert, die indirekt oder in Kombination mit anderen Informationen aus dem Interview Rückschlüsse auf die befragte Person ermöglichen würden. Das Bundesdatenschutzgesetz (BDSG) für Deutschland spricht dort von Anonymität, wo eine Re-Identifizierung der Person "nur mit einem unverhältnismäßig hohen Aufwand an Zeit, Kosten und Arbeitskraft" (§3, Abs.6) zu bewerkstelligen ist. Das österreichische Datenschutzgesetz beinhaltet keine derartige Definition. Absolute Anonymität schließlich ist nur dann gegeben, wenn jeder Rückschluss auf eine Person ausgeschlossen werden kann. Gerade wenn Befragte aus eng begrenzten Populationen stammen, wo eine Re-Identifizierung auch mit wenig Zusatzwissen möglich wäre, ist dies oft die einzige Option auf Anonymisierung, beinhaltet aber das Entfernen wesentlicher Informationen. [31]
Grundsätzlich bedeutet jede Anonymisierung von Daten, die Daten zu verändern, und dadurch verändern sich auch der Status und die Qualität der Daten. Eine Folge von Anonymisierungsmaßnahmen kann sein, dass die Daten für die Sekundärnutzung an Wert verlieren. So argumentieren CORTI und ihre Ko-AutorInnen: "[E]ven basic removal of identifiers can lessen the value of data" (CORTI, DAY et al. 2000, §30). Schärfer noch formuliert Janet HEATON: "[E]fforts to disguise the identity of informants may also spoil and distort the data" (2004, S.83). Oft sind es gerade die Details, die für eine Analyse bedeutend sind, und WissenschaftlerInnen legen als SekundärnutzerInnen Wert auf hochsensible Originaldaten und umfangreiche Kontextinformationen (MEDJEDOVIC 2007). Je nach Forschungsprojekt können daher forschungsethische Fragen nicht direkt und allgemeingültig beantwortet werden. Es gilt, eine Balance zu finden zwischen datenschutzrechtlich und forschungsethisch begründeten Ansprüchen an eine Anonymisierung der Daten auf der einen und – aus Perspektive der SekundärforscherInnen – notwendigen und zu erhaltenden Kontextinformationen auf der anderen Seite. Mit THOMSON, BZDEL, GOLDEN-BIDDLE, REAY und ESTABROOKS lässt sich festhalten: "[I]n secondary use, we need to find a balance between honoring commitments of confidentiality made to participants at the time the data was originally gathered, while still retaining the usefulness of the data in the development of further knowledge" (2005, §1). Von Projekt zu Projekt sollte daher individuell entschieden werden, welcher Grad der Anonymisierung sinnvoll und notwendig ist. [32]
Wenn Projekte bereits abgeschlossen wurden oder keine Ressourcen für eine Datenaufbereitung vorhanden sind, bietet WISDOM DatengeberInnen die formale Anonymisierung textbasierter Daten an. Das beinhaltet die Durchsicht der zur Verfügung gestellten Daten, das Ersetzen direkter Identifikatoren durch sinngleiche Pseudonyme und teilweise auch das Löschen identifizierender Textpassagen, wenn die Verwendung von Pseudonymen nicht zielführend ist. Auch Identifikatoren dritter Personen werden entfernt und ersetzt. Eine faktische Anonymisierung kann in den meisten Fällen jedoch nur mit projektspezifischem Hintergrundwissen durchgeführt und daher nur von den PrimärforscherInnen selbst erstellt werden. Da WISDOM die Weitergabe der Daten zusätzlich zur Anonymisierung an die Einhaltung von vertraglich festgelegten Nutzungsbedingungen knüpft (s. Abschnitt 2.7) und die Wiederverwendung archivierter Daten außerdem auf wissenschaftliche Forschungs- und Lehrtätigkeiten beschränkt, ist davon auszugehen, dass mit diesen Maßnahmen die befragten Personen ausreichend geschützt sind. Außerdem ist WISDOM der Idee eines wissenschaftlichen Ethos verbunden, der miteinschließt, dass sich auch projektfremde KollegInnen einem ethischen Umgang mit Forschungsdaten verpflichten (s.a. THOMSON et al. 2005, §13). Bei besonders sensiblen Projekten können gegebenenfalls strengere Zugangsbeschränkungen getroffen oder weitreichendere Anonymisierungstechniken vorgenommen werden. [33]
Schwieriger als bei Textdokumenten gestaltet sich die Anonymisierung bei Audio-, Video- und Bilddateien. Audioaufnahmen zum Beispiel lassen sich akustisch durch Tonhöhenveränderung oder das Verringern bzw. Steigern der Abspielgeschwindigkeit verfremden (PÄTZOLD 2005). Eine Konsequenz dieser Veränderungen sind Qualitätseinbußen, die eine Sekundäranalyse stark behindern können. Insbesondere Betonungen und nonverbale Laute gehen im Zuge der Veränderungen oft verloren, und auch die Gesamtqualität der Aufnahme leidet unter einer Bearbeitung (§9). Bilddateien werden in der Regel durch das Unkenntlichmachen von Gesichtern durch Verpixelung oder Balkenüberlagerung verfremdet. Für Analysen, die an Gesichtsausdruck oder Blickrichtung interessiert sind, ist die Bildquelle damit zerstört. Bei Videoaufnahmen ergibt sich die Notwendigkeit, sowohl laufendes Bild als auch Ton zu verfremden. Der technische Aufwand steigt hier in einem Ausmaß, welches eine Anonymisierung der Daten für eine Weiternutzung nicht mehr rechtfertigt. Auch die Anonymisierung von Audio- und Bilddateien kann am WISDOM mit der derzeitigen Ressourcenausstattung nicht bewältigt werden und erscheint unter Berücksichtigung der Qualitätseinbußen derzeit auch nicht als sinnvoll. Audio-, Video- und Bilddateien werden von WISDOM daher vorerst nur nach Rücksprache mit den DatengeberInnen weitergegeben, die von Fall zu Fall entscheiden, ob und unter welchen Bedingungen die Daten verwendet werden dürfen. Da visuelle Verfahren bzw. auch die Nutzung nicht-textlichen Materials immer bedeutender werden, ist anzunehmen, dass hier – wie im Falle der alten Interviewbestände davor – große Datenmengen für eine Nachnutzung verloren gehen. [34]
Ein sehr zentraler Schritt im Zuge des Archivierungsprozesses und sicherlich der Schritt, der gemeinhin am ehesten mit Archivierungsarbeiten assoziiert wird, ist die Erstellung eines Datenkatalogeintrags. Für jede Studie wird von WISDOM – ähnlich der Erfassung von Werken in Bibliotheken – ein Katalogeintrag erstellt, in dem die wichtigsten Eckdaten der Studie vermerkt werden. Der Gesamtkatalog ist online abrufbar und kann von NutzerInnen mittels verschiedener Suchfunktionen nach passenden Studien durchforstet werden. Anhand der erfassten Informationen können NutzerInnen rasch beurteilen, ob ein Datensatz für ihr Forschungsinteresse relevant ist oder nicht. Die Möglichkeit, Daten online zu recherchieren, erhöht die Sichtbarkeit und damit die Wahrscheinlichkeit einer Weiternutzung von Datensätzen ungemein und ist eine Voraussetzung für national wie international vernetzte, moderne Archive. [35]
WISDOM verwendet für die Darstellung des Onlinekatalogs die Software Nesstar (Networked Social Science Tools and Ressources), die als CESSDA-Projekt von der Universität Essex und dem norwegischen Social Science Data Service (NSD) entwickelt wurde. Über den Nesstar-Datenkatalog werden konkrete Informationen über die vorhandenen Datensätze in Form von sogenannten Metadaten, Daten über Daten, angezeigt. Metadaten werden in erster Linie für die Quellensuche genutzt, da sie indizierte Informationen bereitstellen, die NutzerInnen die Recherche nach Datensätzen ermöglichen. Außerdem enthalten sie bibliografische Informationen, die bei der Weiterverwendung des Datensatzes durch SekundärforscherInnen für die Zitation des Datensatzes verwendet werden und gewährleisten, dass die UrheberInnen der Daten entsprechend gewürdigt werden. Am WISDOM werden Metadaten, wie bei den meisten anderen CESSDA-Archiven, mit dem Standard der Data Documentation Initiative (DDI14)) dokumentiert, einem international etablierten Standard für die Beschreibung sozialwissenschaftlicher Forschungsdaten (CORTI & GREGORY 2011,§17), der das Ziel hat, größtmögliche Interoperabilität, Übertragbarkeit und Sichtbarkeit der Metadaten zu ermöglichen (CORTI 2000, §35). So erlaubt der auf XML15) basierende DDI-Metadatenstandard bspw. den Austausch von Metadaten mit anderen (CESSDA-) Archiven in der Form von archivübergreifenden Datenkatalogen. [36]
Der DDI-Metadatenstandard stellt ein umfangreiches Set an Beschreibungselementen zur Verfügung, um sozialwissenschaftliche Datensätze möglichst vollständig und gründlich zu dokumentieren und dadurch eine informationsbasierte und effiziente Nutzung von Datensammlungen zu ermöglichen. Grundlegende Beschreibungselemente sind beispielsweise Titel, AutorIn, DatenproduzentIn, Urheberrecht, DatengeberIn, Zitation, Schlüsselwörter, Klassifizierung, Abstract, Zeitraum der Erhebung, Charakteristika der Datenerhebung etc. Das DDI-Metadatenmodell wurde ursprünglich für die Dokumentation quantitativer Daten geplant und entwickelt, wird aber zunehmend auch für die Beschreibung qualitativer Erhebungen verwendet (SMIOSKI 2011a, S.229). Eine ausführlichere Auseinandersetzung dazu findet sich bei KUULA (2000), die beschreibt, wie einzelne DDI-Elemente den Besonderheiten qualitativer Daten angepasst werden können. WISDOM stellt über die Katalogeinträge für qualitative Daten möglichst umfassende Informationen zur Studie, zur Datenerhebung und zum Projektkontext zur Verfügung. Beschreibungselemente, wie sampling procedure, characteristics of the data collection situation, type of research instrument oder mode of data collection bieten sich wegen ihrer freien Eingabemöglichkeit an, um derartige Kontextinformationen zu erfassen. Außerdem gibt es unter other materials die Möglichkeit, dem Katalogeintrag Dokumente wie Leitfäden, Fallübersichten, Forschungsdesigns, Endberichte oder Methodenkapitel beizufügen, die von NutzerInnen online eingesehen werden können und weiterreichende Informationen zur Studie beinhalten. Andere Eingabefelder, wie kind of data, geographic coverage, time dimensions oder universe sind enger gefasst und erlauben keine gänzlich freie Eingabe von Text. Teilweise wird hier mit sogenanntem "kontrolliertem Vokabular" gearbeitet, das von allen CESSDA-Archiven für diese Eingabefelder verwendet wird. Im Feld time dimensions bspw. gibt es cross-sectional, follow-up to cross sectional, repeated cross-sectional, longitudinal/panel/cohort und time series als vorgegebene, standardisierte Eingabeoptionen. Auch bei den Feldern keywords und topic classifications wird auf standardisierte Instrumente zur Datenbeschreibung zurückgegriffen. Für die keywords wird ELSST (European Language Social Science Thesaurus), ein multilingualer Thesaurus für die Sozialwissenschaften, verwendet, der im Laufe der Jahre von den CESSDA-Mitgliedern entwickelt wurde und der den Zugang zu Datenressourcen in ganz Europa – unabhängig von Lokalität, Sprache oder Vokabular – erleichtern soll. Für die topic classifications wird einerseits auf die ÖFOS16) Klassifizierung der Statistik Austria zurückgegriffen, andererseits auch ein Klassifikationssystem der CESSDA-Archive angewendet. Beide ordnen Datensätze verschiedenen Wissenschaftszweigen (ÖFOS) bzw. thematischen Kategorien und Sub-Kategorien (CESSDA) zu, was die Suche nach Datensätzen erheblich vereinfacht, da NutzerInnen direkt in den thematischen Sammlungen recherchieren können. [37]
Bevor der Datenkatalogeintrag veröffentlicht wird, ist gemeinsam mit den DatengeberInnen zu klären, welche Zugangsklasse für den Datensatz relevant wird. Die Zugriffsklassen regeln die Verfügbarkeit der Daten für NutzerInnen und die an eine Nutzung gekoppelten Bedingungen. WISDOM setzt sich grundsätzlich für einen möglichst freien Zugang zu den Daten ein, dennoch gibt es Fälle, in denen Einschränkungen der Zugänglichkeit, etwa aufgrund der Sensibilität des Datenmaterials, erforderlich sind. ForscherInnen können sich für folgende Optionen entscheiden:
Zugriffsklasse A: Das Material unterliegt keinen Beschränkungen und ist von DatengeberInnen ohne Einschränkungen für die wissenschaftliche Forschung und die akademische Lehre freigegeben.
Zugriffsklasse B: Vor Weitergabe der Daten an NutzerInnen ist die ausdrückliche, schriftliche Genehmigung der DatengeberInnen erforderlich. Bei der Wahl dieser Zugriffsklasse können DatengeberInnen von Fall zu Fall gezielt über die Nutzung der von ihnen archivierten Daten bestimmen. Diese Option ermöglicht einerseits mehr Kontrolle über die Weiternutzung der Daten, wird aber andererseits auch dann verwendet, wenn DatengeberInnen daran interessiert sind, mit potenziellen NutzerInnen zusammenzuarbeiten und sich auszutauschen.
Zugriffsklasse C: Die DatengeberInnen legen eine zeitliche Sperrfrist fest, innerhalb derer die Daten nicht weitergegeben werden dürfen. Nach Ablauf dieser Frist wird der Datensatz automatisch als Kategorie A klassifiziert. Diese Option wird von DatengeberInnen präferiert, die aufgrund des geringen Aufwands ihre Daten sofort nach Projektende an das Archiv übermitteln, diese aber erst nach dem Erscheinen einer Publikation veröffentlichen wollen.
Zugriffsklasse D: Die DatengeberInnen legen eine zeitliche Sperrfrist fest, innerhalb derer die Daten nicht weitergegeben werden dürfen. Nach Ablauf dieser Frist wird der Datensatz automatisch als Kategorie B klassifiziert und bedarf einer schriftlichen Genehmigung zur Weitergabe. DatengeberInnen können so das Erscheinen von Publikationen abwarten und auch nach Freigabe der Daten die Kontrolle über deren Weitergabe behalten.
Zugriffsklasse E: Die DatengeberInnen überlassen WISDOM sämtliche Daten und Dokumente nur zur Archivierung, und der Zugang zu diesen ist für NutzerInnen gesperrt. WISDOM publiziert ausschließlich die Basisdokumentation im Katalog. Die Sperre kann nur mit dem Einverständnis der DatengeberInnen gelockert werden. Diese Kategorie wird nur in seltenen Fällen vom Archiv zugelassen, da WISDOM grundsätzlich den freien Zugang zu Daten für die wissenschaftliche Forschung unterstützt und auch den Bearbeitungsaufwand rechtfertigen muss. Bei ganz besonders sensiblen Daten ist es, um einem Verlust vorzubeugen, möglich, die Daten ausschließlich am WISDOM zu archivieren. [38]
Mit jeder Einschränkung der Zugangsmöglichkeiten erhöht sich der administrative Mehraufwand bei der Bearbeitung der Anfragen, und in Bezug auf die Datenverfügbarkeit entstehen längere Wartezeiten. Dennoch sind Zugangsbeschränkungen oftmals sinnvoll, sei es, weil DatengeberInnen als ExpertInnen für ihr Untersuchungsfeld am besten entscheiden können, in welchen Zusammenhängen die Daten genutzt werden können oder sei es, weil dadurch Austausch und Kooperationen möglich werden. Zusätzlich zu den verschiedenen Formen der Zugangsbeschränkung ist es für NutzerInnen aber auch und in jedem Fall erforderlich, sich auszuweisen und den Verwendungszweck bekannt zu geben, für den ein Datensatz genutzt werden soll. Nach Freigabe der Daten durch die DatengeberInnen oder das Archiv ist der WISDOM-Benutzungsordnung sowie der WISDOM-Nutzungsvereinbarung in schriftlicher Form zuzustimmen. Diese Dokumente regeln die Verpflichtungen der NutzerInnen im Umgang mit den Daten, u.a. die Beschränkung auf den angegebenen Verwendungszweck, die ordentliche Zitation der DatengeberInnen, die Wahrung der Anonymität der Befragten oder die Gewährleistung der Datensicherheit. [39]
2.8 Das Konzept des living archive
Nach Abschluss der bisher skizzierten Arbeitsschritte sind alle Voraussetzungen für die Weiternutzung der Daten durch andere WissenschaftlerInnen geschaffen. Das klassisch-traditionelle Archivkonzept umfasst natürlich noch weitere Arbeitsschwerpunkte. Dazu gehören insbesondere die Langzeitarchivierung und die Konservierung/Erhaltung, also die technische Sicherung von Daten (getrennte Aufbewahrung von Archiv- und Benutzungskopien), die fachgerechte Behandlung und Lagerung der Daten sowie die laufende Kontrolle der Bestände und deren Überprüfung auf Formatkompatibilität. Das sind wichtige Tätigkeiten, durch die sichergestellt wird, dass Daten auch in Zukunft nutzbar bleiben. [40]
Ich möchte zuletzt ein Konzept einführen, das sich von einem klassisch-traditionellen Archivkonzept, das die Archivierung von Daten gewissermaßen als einen letzten Schritt im Lebenszyklus der Daten versteht, immer mehr verabschiedet. Laut Duden ist unter einem Archiv eine "Einrichtung zur systematischen Erfassung, Erhaltung und Betreuung von Schriftstücken, Dokumenten, Urkunden, Akten, insbesondere soweit sie historisch, rechtlich oder politisch von Belang sind" zu verstehen (DUDEN Online). Diese Definition impliziert, dass es sich bei Archivgut um "nicht mehr aktuelle" Bestände handelt, die es abseits ihres ursprünglichen Entstehungszusammenhangs für eine weitere Nutzung zu erhalten gilt. Vor dem Hintergrund der oben beschriebenen Verzahnung von Forschungs- und Archivierungsprozess hoffe ich, dass auch der nächste Gedankenschritt logisch nachvollziehbar ist: Es werden in immer kürzerer Zeit immer mehr Daten produziert. Die Bezüge zwischen Daten werden dadurch immer komplexer und es wird schwieriger, "Anfang" und "Ende" des Datenlebenszyklus zu bestimmen. Das heißt, Daten haben oft einen längeren Lebenszyklus als die Projekte, in deren Zusammenhang sie erhoben wurden. Das Potenzial, archivierte Daten bei der Erhebung neuer Daten zu nutzen, Daten zu verknüpfen und aus bestehenden Daten neue Daten zu generieren, wird mehr und mehr erkannt. ForscherInnen arbeiten auch nach Projektende mit Projektdaten weiter, Folgeprojekte verwenden die Daten oder tragen zu ihrer weiteren Anreicherung und Ergänzung bei. Und auch SekundärforscherInnen produzieren durch ihre Arbeit mit den Daten einen Mehrwert (bspw. ergänzende Erhebungen, das Erstellen neuer Kategoriensysteme oder detaillierterer Transkriptionen, die grafische Darstellung der Daten u.a.). Moderne Archive richten daher das Augenmerk vermehrt auf einen Datenlebenszyklus, der weniger als abgeschlossener, sondern überwiegend als zyklischer Prozess gedacht wird (siehe Abbildung 2).
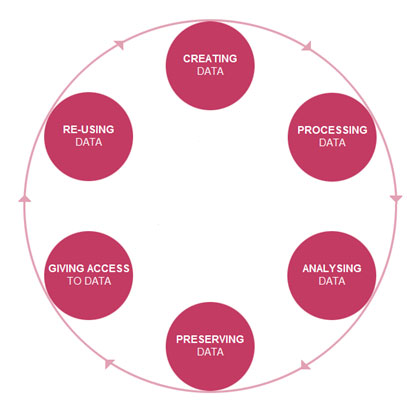
Abbildung 2: Research Data Lifecycle [Zugriff: 26.7.2013] [41]
Daran anknüpfend möchte ich daher vorschlagen, Archive nicht mehr als Repositorien im Sinne von Aufbewahrungsstätten zu verstehen. Stattdessen scheint mir das Konzept eines living archive sinnvoll. Das Ineinandergreifen von Forschungs- und Archivierungsprozessen bezieht sich dabei nicht nur auf den Kontext der Primärdatenerhebung, sondern auch auf Sekundärnutzungen, die auf Basis archivierter Daten durchgeführt werden. Aus dieser Perspektive ist das Stigma, SekundärnutzerInnen würden die Arbeit ihrer KollegInnen nutzen, um auf eigene Datenerhebungen verzichten zu können, obsolet. Wir müssen uns vom Idealtypus des/der Forschenden verabschieden, der/die als PrimärforscherIn im Feld eigene Daten erhebt (SMIOSKI 2011b, S.138). Stattdessen werden auch die SekundärforscherInnen als aktiv Forschende in die Gestaltung des Lebensprozesses der Daten mit eingebunden.17) Material, das aus der Wiederverwendung archivierter Daten resultiert, wird an das Archiv gegeben, welches auch die neuen Daten sammelt und aufbereitet, um existierende Bestände anzureichern, aber darüber hinaus auch als Schnittstelle zwischen PrimärforscherInnen und SekundärnutzerInnen fungiert und dadurch Synergien ermöglicht. Datenbestände können so wachsen und im Laufe ihres Lebenszyklus an Qualität gewinnen. Neben den zahlreichen Benefits, die sich aus dem Rückgriff auf und durch die Verwendung von archivierten qualitativen Daten ergeben können, entsteht durch den Archivierungsprozess im Rahmen dieses Modells auch ein Qualitätsgewinn des Datenmaterials selbst. Entwicklungen in dieser Richtung haben die Chance, empirisches Arbeiten gravierend zu verändern und um neue Möglichkeiten im Umgang mit und in der Verwendung von Daten anzureichern. [42]
3. Wie Datenarchivierung zur Güte qualitativer Forschung beitragen kann
Die bisherigen Überlegungen münden in eine allgemeinere Diskussion rund um die Qualität qualitativer Daten und Gütekriterien für die qualitative Forschung, eine Diskussion, in der bis heute keine Einigung auf einheitliche Standards stattgefunden hat (vgl. HELFFERICH 2005; LAMNEK 2005; PRZYBORSKI & WOHLRAB-SAAR 2010; u.a.). [43]
Aus konstruktivistischer Sicht ist wissenschaftliche Erkenntnis das Resultat von Konstruktionsleistungen und damit genauso abhängig von spezifischen Erhebungskontexten wie von der Person des/der Forschenden (s. u.a. GILLIES & EDWARDS 2005, §23). Die Einbeziehung der ForscherInnen und die Kommunikation mit den Beforschten sind konstitutive Elemente des Erkenntnisprozesses in der qualitativen Sozialforschung (KARDORFF 1995, S.4). Ergebnisse werden als kontextspezifisch erzeugt verstanden, was die Versionenhaftigkeit der produzierten Daten (HELFFERICH 2005, S.155) zur Folge hat. Diese theoretische Hintergrundfolie impliziert aber gewissermaßen per se den Verzicht auf die Replizierbarkeit wissenschaftlicher Untersuchungen und damit die Idee der Verifizierung wissenschaftlicher Forschungsergebnisse, wie man sie aus der quantitativ orientierten Forschung kennt. In der quantitativen Forschung geht man davon aus, dass Daten unabhängig von der Person des/der Forschenden existieren. Subjektive Konstruktionsleistungen sollen durch Standardisierung weitgehend eliminiert werden. Äußerungen von Befragten werden aus spezifischen Verweisungszusammenhängen herausgelöst und damit in ihrem Bedeutungsgehalt standardisiert (PRZYBORSKI & WOHLRAB-SAAR 2010, S.30). Ein Stimulus soll dadurch von allen Befragten in gleicher Weise verstanden werden. Das Ziel ist die Prüfung von Hypothesen, deren Gegenstandsbereich bereits operationalisiert ist. Standardisierung ist die Grundlage für intersubjektive Überprüfbarkeit, und einheitliche Testverfahren erlauben die Prüfung auf Gültigkeit (Validität) und Zuverlässigkeit (Reliabilität) der Daten bzw. der Forschungsergebnisse. [44]
Standardmäßig verwendete Verfahren zur Qualitätssicherung in der quantitativen Forschung lassen sich auf qualitative Forschung nicht eins zu eins übertragen und werden hier in der Regel stark von Gegenstand und Methode abhängig gemacht. Es brauche, so Cornelia HELFFERICH, eigene, dem spezifischen Forschungsgegenstand "Sinn" und dem Auftrag "Verstehen" angemessene Gütekriterien: "Die Unmöglichkeit von Objektivität ist ja nicht ein Mangel, sondern Ausgangspunkt qualitativer Forschung, daher kann es nicht um anzustrebende Objektivität gehen, sondern um einen anzustrebenden angemessenen Umgang mit Subjektivität" (2005, S.138). Die Versionenhaftigkeit der Daten beruhe nicht auf Beliebigkeit, sondern weise auf die spezifische Produktion qualitativer Daten hin (a.a.O.) und stelle daher kein wissenschaftslogisches Problem dar. [45]
Bislang hat man sich in der qualitativen Forschung nicht auf einheitliche Gütekriterien einigen können. LAMNEK konstatiert 2005 sogar, dass man sich – von wenigen Ausnahmen abgesehen – nicht sehr intensiv mit der Entwicklung von Gütekriterien für die qualitative Forschung auseinandergesetzt habe (S.145).18) Ausgehend von bestimmten wissenschaftstheoretischen und methodologischen Positionen wurden von einigen AutorInnen teilweise sehr unterschiedliche Kriterien vorgeschlagen, um die Qualität der Erkenntnisgewinnung in der qualitativen Forschung zu bestimmen (siehe z.B. BERGMANN & COXON 2005; HELFFERICH 2005; LAMNEK 2005; PRZYBORSKI & WOHLRAB-SAAR 2010; SEALE 2000), es liegt aber kein Konzept vor, das generell Anerkennung finden könnte (FLICK 2008, S.110). Allein die Angemessenheit von Theorien, Methoden und Begriffen für eine spezifische empirische Realität und für das Erkenntnisziel (FLICK 2007, S.512-518; LAMNEK 2005, S.144f.) und auch die reflektierte Subjektivität im Sinne einer kontinuierlichen Selbstbeobachtung und Selbstreflexion des/der Forschenden (STEINKE 2000, S.330) dürften als übergeordnete Gütekriterien über wissenschaftstheoretische Positionen hinweg anerkannt werden. [46]
Ich möchte vor diesem Hintergrund ein weiteres Kriterium zur Diskussion stellen, anhand dessen meines Erachtens unabhängig von wissenschaftstheoretischen oder methodologischen Positionen die Qualität qualitativer Daten maßgeblich festgemacht werden kann und welches in der Praxis auch leichter bestimmbar ist als die weitgehend abstrakte Forderung nach Angemessenheit oder das von einer Außenperspektive schwer auslotbare Ausmaß notwendiger Reflexivität der ForscherInnen. Das Kriterium, auf das ich hinaus möchte, ist jenes der Verfahrensdokumentation, wie es auch MAYRING (2002, S.144f.) anführt. Allerdings greift sein Verständnis der Verfahrensdokumentation als "Explikation des Vorverständnisses, Zusammenstellung des Analyseinstrumentariums, Durchführung und Auswertung der Datenerhebung" (a.a.O.) bei Weitem zu kurz bzw. bleibt viel zu unspezifisch. Ines STEINKE (2000, S.324f.) kommt in ihrer Beschreibung der Dokumentation des Forschungsprozesses meinem Verständnis von Verfahrensdokumentation deutlich näher. Sie betont auch deren Bedeutung für die intersubjektive Nachvollziehbarkeit, auf deren Basis eine Bewertung der Ergebnisse überhaupt erst möglich werde und die der Dynamik zwischen Gegenstand, Fragestellung und methodischem Konzept Rechnung trage. LeserInnen wird erst durch eine umfassende Dokumentation – so STEINKE – möglich, die Qualität einer Studie im Licht eigener Kriterien zu beurteilen: Die Dokumentation des Vorverständnisses der ForscherInnen gebe Aufschluss darüber, ob eine Studie neue Ergebnisse zutage bringt. Informationen zu Interviewkontexten würden eine Einschätzung der Glaubwürdigkeit von Interviewäußerungen erlauben. Die Dokumentation der Daten und Informationsquellen sowie der Auswertungsmethoden sei Voraussetzung, um einschätzen zu können, ob Instrumente richtig eingesetzt und Verfahrensrichtlinien eingehalten wurden und gestatte eine Bewertung der Interpretation. SEALE fasst dies zusammen wie folgt:
"[I]f readers can see the entire corpus of data (...) this is like inviting the reader participate in an inter-rater reliability exercise (...) since it would enable (...) the research process to be fully exposed to the readers' critical gaze" (2000, S.156). [47]
STEINKE und SEALE schließen in eine Dokumentation also auch die Daten selbst – den "Datenkorpus" bzw. die "Informationsquellen" – mit ein, was der Idee der Offenlegung von Daten entspricht. Beide enthalten den LeserInnen aber gänzlich, wie sich die Zugänglichkeit zu den Dokumentationen gestalten könnte und welche Darstellungsmöglichkeiten es dafür gibt. [48]
Es liegt auf der Hand, dass im Rahmen üblicher Publikationsmedien kein Raum für eine derart umfassende Dokumentation bereitsteht. In Bezug auf die Legitimierung wissenschaftlicher Erkenntnisse auf der Basis von Daten und der Dokumentation des Forschungsprozesses scheint also bisher – zumindest in den Sozialwissenschaften und insbesondere in der qualitativen Forschung – stillschweigend ein Vertrauensvorschuss hinsichtlich einer korrekten wissenschaftlichen Vorgehensweise (bspw. methodisch saubere Anwendung der Methoden, Explizieren von Auswertungsprinzipien, Dokumentation des Forschungsprozesses etc.) der KollegInnen geleistet zu werden. Dass dies nicht immer gerechtfertigt ist, habe ich in Abschnitt 2.2 herauszuarbeiten versucht: Viel zu viele Projekte und deren Ergebnisse werden unzureichend dokumentiert. Instanzen für die Qualitätssicherung sind also nicht nur wünschenswert, sondern sogar notwendig, wenn sich an der aktuell schlechten Situation langfristig etwas ändern soll. [49]
Datenarchive sind als professionelle Infrastruktureinrichtungen hierauf spezialisiert: Es gehört zu ihren zentralen Arbeitsfeldern, Daten zu evaluieren, Dokumentationen auf ihre Qualität und Vollständigkeit zu überprüfen bzw. sie zu erstellen und Daten für eine Weiternutzung entsprechend aufzubereiten. Insofern können Archive einerseits die fehlenden Kompetenzen zur Verfügung stellen und Wissen in den Bereichen Datendokumentation und Datenmanagement vermitteln. Sie können aber andererseits auch als Instanzen für die Qualitätssicherung von Daten und Dokumentationen fungieren, indem sie Best-Practice-Kriterien für Datendokumentation und Datenmanagement vorgeben und deren Einhaltung überprüfen. Schon in der Zusammenarbeit mit ForscherInnen, die eine Archivierung ihrer Daten nach Projektende anstreben, zeigt sich aus den bisherigen Erfahrungen am WISDOM, dass hier eine wesentliche, qualitative Verbesserung der Dokumentations- und Datenmanagementstrategien zu beobachten ist. Aus Eigeninitiative motivierte Datendeponierungen sind aber, wie ich zu zeigen versucht habe, nach wie vor äußerst selten. Eine weitaus größere Wirksamkeit solcher Maßnahmen ließe sich meines Erachtens durch konkrete Zusammenarbeit zwischen Archiven und Fördereinrichtungen erreichen. Wenn bereits vonseiten der GeldgeberInnen ein offener Zugang zu den Daten in Kooperationsarchiven vorgegeben wird, können ForscherInnen vom Archiv gezielter und effizienter bei einer hochwertigen Dokumentation und Aufbereitung ihrer Daten unterstützt werden, was eine erhebliche Verbesserung der Qualität von Datendokumentation und Datenmanagement zur Folge haben würde. Und diese wiederum ist, wie auch von STEINKE und SEALE betont wird, ein entscheidendes Kriterium für die Beurteilung der Güte und Qualität qualitativer Forschung. [50]
Ich habe in diesem Artikel versucht, einen weiten Bogen zu spannen. Einführend wurde die Ausgangslage in Bezug auf die Archivierung sozialwissenschaftlicher und insbesondere qualitativer Daten beschrieben. In Österreich gibt es am WISDOM seit vier Jahren ein qualitatives Archiv, und durch die intensive Arbeit mit ForscherInnen/ProjektleiterInnen und vielfältigen qualitativen Datenbeständen sowie durch die theoretische und praktische Auseinandersetzung mit wichtigen Fragestellungen, die es bei der Archivierung qualitativer Daten zu berücksichtigen gilt, kann nunmehr auch in diesem Bereich Expertise angeboten werden. Anhand der Beschreibung einzelner Archivierungsstrategien habe ich dann die Argumentation verdichtet, dass Forschungs- und Archivierungsprozess an vielen Stellen nahtlos ineinandergreifen und nicht voneinander separiert gesehen werden können. Defizite bei der Datendokumentation und beim Datenmanagement wurden identifiziert und Leitlinien für eine gute wissenschaftliche Praxis wurden vorgeschlagen. [51]
Als modernes Archivkonzept wurde die Idee des living archive entwickelt. Es zeigt auf, dass der Gedanke einer freien Datennutzung in der Wissenschaft nicht nur für SekundärforscherInnen Vorteile bringt, sondern auch einen Qualitätsgewinn des Datenmaterials zur Folge haben kann, von dem Primär- und SekundärforscherInnen profitieren und wodurch neue Möglichkeiten im Umgang und in der Verwendung von Daten entstehen. [52]
Schließlich habe ich die von mir aufgeworfenen Fragen der Archivierung mit der Diskussion rund um Gütekriterien für die qualitative Forschung zu verbinden versucht. In der Literatur wird der Dokumentation von Studien – worunter neben dem Datenmaterial auch die Kontextdokumentation verstanden wird – ein zentraler Stellenwert für die Beurteilung der Qualität der Studie und die intersubjektive Nachvollziehbarkeit des Forschungsprozesses und seiner Ergebnisse zugeschrieben. Archive stellen die notwendige Infrastruktur zur Verfügung, um diese Dokumentationen zu prüfen und zugänglich zu machen und können somit als mögliche Instanzen im Prozess der Qualitätssicherung betrachtet werden. [53]
In den letzten Jahren hat sich im Diskurs um die Archivierung und Sekundärnutzung qualitativer Daten viel bewegt. Dafür ausschlaggebend sind Initiativen auf nationaler und internationaler Ebene, die Einführung von Datenpolitiken durch die Forschungsförderung sowie in nicht unwesentlichem Ausmaß die gewachsene Bedeutung der Open-Access-Bewegung, die auch in diesen Diskurs hineinspielt und die Forderung nach open data vehement einbringt und diskutiert. In Österreich ist die erfolgreiche Etablierung eines qualitativen Archivs für Datendeponierungen, aber auch für Datennutzungen allerdings nur unter sehr erschwerten Bedingungen möglich. Das liegt vor allem daran, dass der Stellenwert der Forschungsinfrastruktur für hochwertige Forschungsleistungen und eine internationale Wettbewerbsfähigkeit in Österreich noch nicht von allen am System Forschung beteiligten Stellen in vollem Ausmaß erkannt bzw. betrieben wird (vgl. POCK et al. 2010, S.123). Bei der Einführung von Datenpolitiken, der ausreichenden Finanzierung von Infrastruktureinrichtungen, der Kooperationen mit Archiven und deren Einbindung in Forschungsprozesse und bei der Vermittlung notwendiger Kompetenzen sehe ich großen Entwicklungsbedarf. Dazu braucht es aber (auch aufseiten der GeldgeberInnen) eine wertschätzende Haltung für die Arbeit von Archiven und eine Wahrnehmung der Vorteile, die data sharing mit sich bringt. [54]
1) SILC ist eine Erhebung, durch die jährlich Informationen über die Lebensbedingungen der Privathaushalte in der Europäischen Union gesammelt werden. <zurück>
2) Durch den Mikrozensus werden Grundinformationen zu den Bereichen Erwerbsstatistik und Wohnungsstatistik erhoben und die wichtigsten Veränderungen der wirtschaftlichen und sozialen Lage der österreichischen Wohnbevölkerung dokumentiert. Der Mikrozensus liefert international vergleichbare Daten zu Erwerbstätigkeit, Arbeitslosigkeit und Bildung. <zurück>
3) Der European Social Survey (ESS) untersucht Einstellungen, Überzeugungen und Verhalten der europäischen Bevölkerung. <zurück>
4) Der European Quality of Life Survey (EQLS) untersucht Themenbereiche wie Arbeit, Einkommen, Ausbildung, Wohnen, Familie, Gesundheit, Lebenszufriedenheit etc. <zurück>
5) Mittlerweile gibt es in den meisten europäischen Ländern Initiativen zur Archivierung und Nachnutzung qualitativer Daten. Für eine Liste an Einrichtungen s. http://www.esds.ac.uk/qualidata/access/internationaldata.asp [26.7.2013]. <zurück>
6) So auf den EUROQUAL (Qualitative Research in the Social Sciences in Europe) Konferenzen Ethics and Politics in Qualitative Methods, Juni 2009, Archives and Life-History Research, September 2009, International Perspectives on Qualitative Research in the Social Sciences, Mai 2010 oder den SLLS (Society for Longitudinal and Life Course Studies) Konferenzen Developments and Challenges in Longitudinal Studies from Childhood, September 2010 und Life Course and Social Change: Interdisciplinary and International Perspectives, September 2011. Auch beim 5.,7. und 9. Berliner Methodentreffen Qualitative Forschung gab es Beiträge zur Archivierung und Sekundäranalyse qualitativer Daten, und bei den jährlich stattfindenden Open-Access-Tagen ist das Thema open data spätestens seit 2009 in Form von Vorträgen oder Postern ein Fixpunkt im Programm. Bei der ESA (European Sociological Association) Midterm Conference Curiosity and Serendipity – A Conference on Qualitative Methods in the Social Sciences im September 2012 wurde das Thema qualitative Datenarchivierung ebenfalls behandelt. <zurück>
7) N = 183; insgesamt wurde der Fragebogen über relevante Mailinglisten an über 1.100 ForscherInnen verschickt. Die Auswertung des Fragebogens ergab Angaben zu 1.097 qualitativen Forschungsprojekten, die von den Befragten in den Jahren 2000 bis 2008 durchgeführt wurden (SMIOSKI et al. 2008, S.45). <zurück>
8) Auch der Rat für Forschung und Technologieentwicklung empfiehlt eine langfristige Budgetplanung für Infrastrukturförderungen: "[D]ie Budgets für neue Forschungsinfrastrukturprojekte sollen nicht wie bisher üblich nur für die Errichtungskosten (...) vorgesehen werden, sondern sie sollen auch den damit zusammenhängenden operativen Betrieb inkl. die Erhaltung, das technologische Upgrade und die Erneuerung im Voraus berücksichtigen" (POCK, HÖFLER, LAUTSCHAM, ALKAN & FRITZ, 2010, S.119). <zurück>
9) HUMPHREY, ESTABROOKS, NORRIS, SMITH und HESKETH (2000) erörtern in diesem Zusammenhang auch die Vorteile, schon während der Forschung einen/eine ArchivarIn "an Board" zu haben. <zurück>
10) Der FWF hält ForscherInnen in seinen Open-Access-Richtlinien seit Januar 2010 dazu an, Forschungsdaten innerhalb von zwei Jahren nach Projektende über ein disziplinspezifisches Repositorium zugänglich zu machen. Bisher hat diese sehr offen formulierte Richtlinie aber nicht zu Datenabgaben geführt. Inwieweit ihre Einhaltung überprüft wird, ist noch unklar und wird sich wohl erst nach längerer Wirksamkeit der Richtlinie abzeichnen. Der Jubiläumsfonds der Österreichischen Nationalbank sieht in seinen Förderverträgen die Archivierungspflicht für sozialwissenschaftliche Daten am WISDOM vor. Gegenüber ForscherInnen lässt sich von WISDOM in der Praxis daraus dennoch kein Anspruch auf die Archivierung der Daten geltend machen, da es seitens des Fonds weder eine Überprüfung noch Negativfolgen für ForscherInnen bei Nichteinhaltung gibt. <zurück>
11) Für eine Übersicht zu Kriterien bei ESDS Qualidata s. CORTI (2005a, §9f.). <zurück>
12) Detaillierte Informationen zu allen Tätigkeiten, die zu einem guten Datenmanagement gehören, finden sich – aufgeschlüsselt nach den einzelnen Arbeitsschritten im Forschungsprozess – auf der WISDOM Datenarchiv-Homepage unter dem Menüpunkt Datenmanagement. <zurück>
13) OCR steht für Optical Character Recognition. <zurück>
14) Siehe http://www.ddialliance.org/ [Zugriff: 26.7.2013]. <zurück>
15) XML ist eine Auszeichnungssprache, die den Austausch von Daten zwischen verschiedenen Computersystemen bzw. über das Internet unterstützt. <zurück>
16) Die Österreichische Systematik der Wissenschaftszweige 2012 (ÖFOS 2012) ist die auf die österreichischen Gegebenheiten abgestimmte Version der revidierten internationalen Klassifikation "Fields of Science and Technology" (FOS), deren Anwendung im internationalen Vergleich und insbesondere innerhalb des europäischen statistischen Systems verbindlich ist. <zurück>
17) Natürlich ist das in keiner Weise so zu verstehen, dass die Leistungen der PrimärforscherInnen geschmälert werden sollen. Im Gegenteil: WISDOM setzt sich dafür ein, das Publizieren von Daten genauso als wissenschaftliche Leistung anzuerkennen wie die Veröffentlichung wissenschaftlicher Artikel und Bücher. Alle PrimärforscherInnen, die Daten am WISDOM deponieren, müssen im Zuge einer Datennutzung entsprechend zitiert werden. <zurück>
18) Demgegenüber sei an dieser Stelle auf die Qualitätsdebatte in FQS hingewiesen: http://www.qualitative-research.net/index.php/fqs/browseSearch/identifyTypes/view?identifyType=Debate%3A%20Quality [Zugriff: 29.7.2013]. <zurück>
Barbour, Rosaline S. & Eley, Susan (Hrsg.) (2007). Refereed special section: Reusing qualitative data. Sociological Research Online, 12(3), http://www.socresonline.org.uk/12/3/contents.html [Zugriff: 26.7.2013].
Bergman, Manfred Max & Coxon, Anthony P.M. (2005). The quality in qualitative methods. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 6(2), Art. 34, http://nbn-resolving.de/urn:nbn:de:0114-fqs0502344 [Zugriff: 26.7.2013].
Bergman, Manfred Max & Eberle, Thomas S. (Hrsg.) (2005). Qualitative Forschung, Archivierung, Sekundärnutzung: Eine Bestandsaufnahme. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 6(2), http://www.qualitative-research.net/fqs/fqs-d/inhalt2-05-d.htm [Zugriff: 26.7.2013].
Corti, Louise (2000). Progress and problems of preserving and providing access to qualitative data for social research—The international picture of an emerging culture. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 1(3), Art. 2, http://nbn-resolving.de/urn:nbn:de:0114-fqs000324 [Zugriff: 26.7.2013].
Corti, Louise (2005a). Qualitative archiving and data sharing: Extending the reach and impact of qualitative data. IASSIST Quarterly, 3, http://www.iassistdata.org/downloads/iqvol293corti.pdf [Zugriff: 26.7.2013].
Corti, Louise (2005b). User support. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 6(2), Art. 41, http://nbn-resolving.de/urn:nbn:de:0114-fqs0502411 [Zugriff: 26.7.2013].
Corti, Louise & Ahmad, Nadeem (2000). Digitising and providing access to social-medical case records: The case of George Brown's works. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 1(3), Art. 6, http://nbn-resolving.de/urn:nbn:de:0114-fqs000368 [26.7.2013]
Corti, Louise & Gregory, Arofan (2011). CAQDAS comparability. What about CAQDAS data exchange?. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 12(1), Art. 35, http://nbn-resolving.de/urn:nbn:de:0114-fqs1101352 [Zugriff: 26.7.2013].
Corti, Louise; Day, Annette & Backhouse, Gill (2000). Confidentiality and informed consent: Issues for consideration in the preservation of and provision of access to qualitative data archives. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 1(3), Art. 7, http://nbn-resolving.de/urn:nbn:de:0114-fqs000372 [Zugriff: 26.7.2013].
Corti, Louise; Witzel, Andreas & Bishop, Libby (Hrsg.) (2005). Sekundäranalyse qualitativer Daten. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 6(1), http://www.qualitative-research.net/fqs/fqs-d/inhalt1-05-d.htm [26.7.2013]
Corti, Louise; Kluge, Susann; Mruck, Katja & Opitz, Diane (Hrsg.) (2000). Text. Archiv. Re-Analyse. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 1(3), http://www.qualitative-research.net/fqs/fqs-d/inhalt3-00-d.htm [Zugriff: 26.7.2013].
ESRC (2000, 2010). Economic and Social Research Council Data Policy, http://www.esrc.ac.uk/_images/Research_Data_Policy_2010_tcm8-4595.pdf [Zugriff: 29.7.2013].
Fink, Anne Sofie (2000). The role of the researcher in the qualitative research process. A potential barrier to archiving qualitative data. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 1(3), Art. 4, http://nbn-resolving.de/urn:nbn:de:0114-fqs000344 [Zugriff: 26.7.2013].
Flick, Uwe (2007). Qualitative Sozialforschung. Eine Einführung. Reinbek: Rowohlt.
Flick, Uwe (2008). Triangulation. Eine Einführung (2. Aufl.). Wiesbaden: VS Verlag für Sozialwissenschaften.
Gillies, Val & Edwards, Rosalind (2005). Secondary analysis in exploring family and social change: Addressing the issue of context. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 6(1), Art. 44, http://nbn-resolving.de/urn:nbn:de:0114-fqs0501444 [Zugriff: 26.7.2013].
Heaton, Janet (2004). Reworking qualitative data. London: Sage.
Helfferich, Cornelia (2005). Die Qualität qualitativer Daten. Manual für die Durchführung qualitativer Interviews (2. Aufl.). Wiesbaden: VS Verlag für Sozialwissenschaften.
Hopf, Christel (2005). Forschungsethik und qualitative Forschung. In Uwe Flick, Ernst von Kardorff & Ines Steinke (Hrsg.), Qualitative Forschung. Ein Handbuch (S.589-600). Reinbek: Rowohlt.
Hox, Joop J. & Beoije, Hennie R. (2005). Data collection. Primary versus secondary. Encyclopedia of Social Measurement, 1, 593-599, http://igitur-archive.library.uu.nl/fss/2007-1113-200953/hox_05_data%20collection,primary%20versus%20secondary.pdf [Zugriff: 26.7.2013].
Humphrey, Charles K.; Estabrooks, Carole A.; Norris, Judy R.; Smith, Jane E. & Hesketh, Kathryn L. (2000). Archivist on board: Contributions to the research team. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 1(3), Art. 5, http://nbn-resolving.de/urn:nbn:de:0114-fqs000356 [Zugriff: 29.7.2013].
Inter-university Consortium for Political and Social Research (ICPSR) (2009). Guide to social science data preparation and archiving: Best practice throughout the sata life cycle (4. Aufl.). Ann Arbor, MI. http://www.icpsr.umich.edu/files/ICPSR/access/dataprep.pdf [Zugriff: 26.7.2013].
Jacobs, James A. & Humphrey, Charles K. (2004). Preserving research data. Communications of the ACM, 47(9), 27-29.
Joye, Dominique (2005). Qualitative or quantitative? Data archiving in documentation, research and teaching. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 6(2), Art. 39, http://nbn-resolving.de/urn:nbn:de:0114-fqs0502394 [Zugriff: 29.7.2013].
Kardorff, Ernst von (1995). Qualitative Sozialforschung. Versuch einer Standortbestimmung. In Uwe Flick, Ernst von Kardorff, Heiner Keupp, Lutz von Rosenstiel & Stephan Wolff (Hrsg.), Handbuch Qualitative Sozialforschung. Grundlagen, Konzepte, Methoden und Anwendungen (S.3-8). Weinheim: Beltz.
Knoll, Elisabeth (2006). Frauen im Abseits [Archivierte Studie DISS200601q]. Wien: WISDOM.
Kuula, Arja (2000). Making qualitative data fit the "Data Documentation Initiative" or vice versa?. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 1(3), Art. 19, http://nbn-resolving.de/urn:nbn:de:0114-fqs0003194 [Zugriff: 26.7.2013].
Lamnek, Siegfried (2005). Qualitative Sozialforschung. Lehrbuch (4. Aufl.). Weinheim: Beltz.
Larcher, Manuela (2009). Haushaltsstrategien und langfristige Entwicklung landwirtschaftlicher Biobetriebe in Österreich. Eine Typologie der Betriebsentwicklung
von 1991 bis 2004. Dissertation, Universität für Bodenkultur, Wien.
Leh, Almut (2000). Probleme der Archivierung von Oral-History-Interviews. Das Beispiel des Archivs "Deutsches Gedächtnis". Forum Qualitative Sozialforschung / Forum Qualitative Social Research, 1(3), Art. 8, http://nbn-resolving.de/urn:nbn:de:0114-fqs000384 [Zugriff: 26.7.2013].
Mayring, Philipp (2002). Einführung in die qualitative Sozialforschung (5. Aufl.). Weinheim: Beltz.
Medjedović, Irena (2007). Sekundäranalyse qualitativer Interviewdaten – Problemkreise und offene Fragen einer neuen Forschungsstrategie. Journal für Psychologie, 15(3), http://www.journal-fuer-psychologie.de/jfp-3-2007-6.html [Zugriff: 26.7.2013].
Medjedovic, Irena & Witzel, Andreas (2010). Wiederverwendung qualitativer Daten. Archivierung und Sekundärnutzung qualitativer Interviewtranskripte. Wiesbaden: VS Verlag für Sozialwissenschaften.
Moore, Niamh (2007). (Re) Using qualitative data? Sociological Research Online, 12(3), http://www.socresonline.org.uk/12/3/contents.html [Zugriff: 26.7.2013].
Muhr, Thomas (2000). Increasing the reusability of qualitative data with XML. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 1(3), Art. 20, http://nbn-resolving.de/urn:nbn:de:0114-fqs0003202 [Zugriff: 26.7.2013].
Neale, Bren & Bishop, Libby (2011). Qualitative and qualitative longitudinal resources in Europe. Mapping the field and exploring strategies for development. IASSIST Quarterly, 34(3-4), 35(1-2), http://iassistdata.org/downloads/iqvol34_35.pdf [Zugriff: 26.7.2013].
Nelson, Bryn (2009). Empty archives. Nature, 461, 160-163.
Niu, Jinfang (2009). Perceived documentation quality of social science data. Dissertation, University of Michigan, http://deepblue.lib.umich.edu/bitstream/2027.42/63871/1/niujf_1.pdf [Zugriff: 26.7.2013].
Opitz, Diane & Mauer, Reiner (2005). Erfahrungen mit der Sekundärnutzung von qualitativem Datenmaterial – Erste Ergebnisse einer schriftlichen Befragung im Rahmen der Machbarkeitsstudie zur Archivierung und Sekundärnutzung qualitativer Interviewdaten. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 6(1), Art. 43, http://nbn-resolving.de/urn:nbn:de:0114-fqs0501431 [Zugriff: 26.7.2013].
Opitz, Diane & Witzel, Andreas (2005). The concept and architecture of the Bremen Life Course Archive. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 6(2), Art. 37, http://nbn-resolving.de/urn:nbn:de:0114-fqs0502370 [Zugriff: 26.7.2013].
Pätzold, Henning (2005). Sekundäranalyse von Audiodaten. Technische Verfahren zur faktischen Anonymisierung und Verfremdung. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 6(1), Art. 24, http://nbn-resolving.de/urn:nbn:de:0114-fqs0501249 [Zugriff: 26.7.2013].
Plaß, Christine & Schetsche, Michael (2000). The analysis and archiving of heterogeneous text documents: Using support of the computer program NUD*IST 4. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 1(3), Art. 21, http://nbn-resolving.de/urn:nbn:de:0114-fqs0003211 [Zugriff: 26.7.2013].
Pock, Austin; Höfler, Bernhard; Lautscham, Helmar; Alkan, Sara & Fritz, Christian (2010). Erhebung österreichischer Forschungsinfrastruktur. Studie im Auftrag des Rats für Forschung und Technologieentwicklung, http://www.rat-fte.at/tl_files/uploads/Studien/Endbericht_Ergaenzende%20Erhebung%20oesterreichischer%20Forschungsinfrastruktur_Austin%20Pock%20+%20Partners_100617_final.pdf [Zugriff: 26.7.2013].
Przyborski, Aglaja & Wohlrab-Sahr Monika (2010). Qualitative Sozialforschung. Ein Arbeitsbuch (3. Aufl.). München: Oldenbourg Verlag.
Richter, Rudolf (2007). Arbeitslose Akademiker [Archivierte Studie UW200701q]. Wien: WISDOM.
Seale, Clive (2000). The quality of qualitative research. London: Sage.
Smioski, Andrea (2011a). Establishing a qualitative data archive in Austria. IASSIST Quarterly, 34(3-4), 35(1-2), http://iassistdata.org/downloads/iqvol34_35_smioski.pdf [Zugriff: 26.7.2013].
Smioski, Andrea (2011b). Archivierung qualitativer Daten in den Sozialwissenschaften. WISDOM. Das österreichische Archiv für sozialwissenschaftliche Forschungsdaten. In Gabriele Fröschl, Rainer Hubert, Elke Murlasits & Siegfried Steinlechner (Hrsg.), Reale Probleme und virtuelle Lösungen. Eine Bestandsaufnahme anlässlich 50 Jahre Österreichische Mediathek und des UNESCO-World-Day for Audiovisual Hertitage 2010 (S.137-147). Wien: LIT Verlag.
Smioski, Andrea (2011c). Wegweiser Qualitative Datenarchivierung: Infrastruktur, Datenakquise, Dokumentation und Weitergabe. SWS-Rundschau, 51(2), 219-238.
Smioski, Andrea; Richter, Rudolf & Bendl, Thomas (2009). Archiving of qualitative and quantitative research data at the Faculty of Social Sciences of the University of Vienna. Forschungsbericht an der Universität Wien, Fakultät für Sozialwissenschaften.
Smioski, Andrea; Müller, Karl H.; Casado Asensio, Juan & Kritzinger, Sylvia (2008). Feasibility study for the preservation and dissemination of qualitative research data in Austria. Forschungsbericht Nr. 12, anzufordern bei WISDOM.
Steinke, Ines (2000). Gütekriterien qualitativer Forschung. In Uwe Flick, Ernst von Kardorff & Ines Steinke (Hrsg.). Qualitative Forschung. Ein Handbuch (S.319-331). Reinbek bei Hamburg: Rowohlt
Thomson, Denise; Bzdel, Lana; Golden-Biddle, Karen; Reay, Trish & Estabrooks, Carole A. (2005). Central questions of anonymization: A case study of secondary use of qualitative data. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 6(1), Art. 29, http://nbn-resolving.de/urn:nbn:de:0114-fqs0501297 [Zugriff: 26.7.2013].
Valles Martínez, Miguel S.; Corti, Louise; Tamboukou, Maria & Baer, Alejandro (2011). Qualitative archives and biographical research methods. An introduction to the FQS special issue. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 12(3), Art. 8, http://nbn-resolving.de/urn:nbn:de:0114-fqs110381 [Zugriff: 26.7.2013].
Van den Berg, Harry (2005). Reanalyzing qualitative interviews from different angles: The risk of decontextualization and other problems of sharing qualitative data. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 6(1), Art. 30, http://nbn-resolving.de/urn:nbn:de:0114-fqs0501305 [Zugriff: 26.7.2013].
Andrea SMIOSKI leitet das qualitative Datenarchiv am Wiener Institut für sozialwissenschaftliche Dokumentation und Methodik (WISDOM). Zu ihren Tätigkeiten zählen neben der Datenakquise und -dokumentation die Unterstützung von DatengeberInnen und NutzerInnen. Sie lehrt qualitative Forschungsmethoden an der Universität Wien und beschäftigt sich mit der Weiterentwicklung der Sekundäranalyse qualitativer Daten. Außerdem arbeitet sie zu den Forschungsschwerpunkten Jugend und Jugendkulturen, Biografie und Identität und Arbeit. Zuletzt hat sie gemeinsam mit Reinhard SIEDER an einem biografieanalytischen Projekt zu Gewalt in Kinderheimen gearbeitet.
Kontakt:
Andrea Smioski
WISDOM
Wiener Institut für Sozialwissenschaftliche Dokumentation und Methodik
Liechtensteinstraße 22a/2/17
1090 Wien, Österreich
E-Mail: andrea.smioski@wisdom.at
Smioski, Andrea (2013). Archivierungsstrategien für qualitative Daten [54 Absätze]. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 14(3), Art. 5,
http://nbn-resolving.de/urn:nbn:de:0114-fqs130350.

Creative Commons Attribution 4.0 International License