Volume 17, No. 3, Art. 2 – September 2016
Open Online Research: Developing Software and Method for Collaborative Interpretation
Christian Bröer, Gerben Moerman, Johan Casper Wester, Liza Rubinstein Malamud, Lianne Schmidt, Annemiek Stoopendaal, Nynke Kruiderink,
Christina Hansen & Hege Sjølie
Abstract: Inspired by the potentials of web-based collaboration, in 2014, a group of social scientists, students and information specialists started tinkering with software and methodology for open online collaborative research. The results of their research led to a gathering of academics at the #ethnography Conference Amsterdam 2014, where new material was collected, shared and collaboratively interpreted. Following the conference, they continued to develop software and methodology. In this contribution, we report on the aims, methodology, inspiring examples, caveats and results from testing several prototypes of open online research software. We conclude that open online collaborative interpretation is both feasible and desirable. Dialogue and reflexivity, we hold, are able to transcend separated perspectives and stimulate agreement on a set of distinct interpretations; they simultaneously respect the multiplicity of understandings of social phenomena whilst bringing order into this diversity.
Key words: open online research; collaborative interpretation; software development; ethnography
Table of Contents
1. Introduction
2. Inspirations and Concerns
3. Perspectivism
4. From Crowd Wisdom to Collaboration
5. Collaborative Science Projects
5.1 Qualitative data analysis (QDA) tools
5.2 Wikipedia
5.3 Wiki survey
6. Outline of the OOR Tool
7. The Tests
7.1 Tool 1: Tweaking Media Wiki software
7.2 Tool 2: Tweaking Disqus software and the #ethnography conference
7.3 Phase 3: A purpose built tool
8. Conclusion
1. Introduction1)
What are the potentials and pitfalls of online collaboration for qualitative social science research? Is it possible to ground interpretive analysis on extensive online collaboration? What can qualitative researchers learn from existing open online knowledge platforms like Wikipedia or Zooniverse? In this contribution, we report on a unique attempt to address these questions. We prototyped and tested software for what we termed Open Online Research (OOR). The OOR tool enables academics and non-academics to collect, share and interpret qualitative data online. It allows for a diversity of perspectives while working towards collaborative learning and clustering similar interpretations. Through this, OOR is able to arrive at a reduced number of interpretations from a larger number of collaborators. [1]
The OOR tool and methodology were tested at the conference of the European Sociological Association RN 20 on Qualitative Methods, titled #ethnography Amsterdam 2014. In this article, we first sketch the main elements of the OOR tool. Second, we describe our sources of inspiration and formulate methodological considerations for OOR. Third, we evaluate a range of tools and projects that support open online collaboration to varying degrees. Lastly, we present versions of the tool and test results. [2]
We were inspired by the creativity of collaborative qualitative analysis in small teams and wondered if we could scale this up to an online group; our aim was to enable wider collaboration across distance and time. Could we design an online environment that retains the advantages of offline qualitative interpretation? What challenges arise when face-to-face interpretative interactions are replaced by online collaborations, and how can these be overcome? What new possibilities emerge when larger numbers of participants, including those from outside academia, collaborate in the process of interpreting aspects of social life? [3]
The points of departure for answering these questions come from advances in citizen science, open access, computer-assisted qualitative research, computer-supported cooperative work, science and technology studies and open online courses (e.g., GILBERT, JACKSON & DI GREGORIO, 2014). However, instead of big data, harvested and processed by software, we want to rely on the collaborative intelligence of networked people, including academics and non-academics, to deepen and broaden qualitative research. Mass-observation (WILLCOCK, 1943), member validation (LINCOLN & GUBA 1985) and action research (SCHRATZ & WALKER, 2005) are known examples of research practices in which citizens are more actively involved. [4]
OOR builds on these experiences in the sense that it acknowledges the capacity of interested citizens to use and reflect on common sense. OOR also acknowledges that citizen scientists are able to learn social science theory and methods. [5]
Most common tasks in qualitative and interpretive research can be executed without designated software. However, this type of analysis still requires structuring tools and technologies: classrooms and offices, whiteboards and cards, scissors and glue, word processors and recordings (ORLIKOWSKI, 2005). Our contribution is not simply an attempt to add one more tool to this list; we try to refrain from neophilia, which is to say, being too enthusiastic about technologies just because they are new (CARVAJAL, 2002). At the same time, we join GILBERT et al. (2014) in their observation that computer-assisted qualitative analysis (CAQDAS) can enhance our understanding of complex qualitative material. Moreover, newcomers to the qualitative research community are "digital natives" who expect to work online; such individuals are familiar with chatting and are accustomed to sharing their thinking processes. Instead of embracing or rejecting web technologies on principle, we assume that human-machine interaction is increasing and can be employed beneficially (SCARDAMALIA & BEREITER, 2014). These technologies allow researchers to collaborate online throughout the research process. [6]
We are also concerned with the state of collaboration in qualitative social science. Publication pressure triggers the fragmentation rather than integration of knowledge. Standard textbooks in qualitative social science methodology pay little attention to collaboration in general and joint interpretation in particular, even if there is a tradition of working in small teams (BRYMAN, 2008; FLICK, 2011; MILES & HUBERMAN, 1994; SILVERMAN, 2001, 2005). Although co-authoring is becoming more common in qualitative social science (WUCHTY, JONES & UZZI, 2007), the open and joint gathering and analysis of data are still rare. Lastly, although social science has a mandate to involve citizens in research to some degree (BURAWOY 2005), this is still mostly achieved through the dissemination of findings rather than through collaboration at the research stage. [7]
We recognize that critiques of the re-analysis of qualitative material might also be relevant to collaborative analysis. However, the quality of the analysis depends on its organization, regardless if it is executed on first or second hand data, by a single researcher or by a team (HAMMERSLEY, 2010; JAMES, 2012; VAN DEN BERG, 2005). More specifically, we attempt to draw out the particular benefits and drawbacks of collaborative analysis. For example, collaborative interpretation means that most participants might lack the familiarity and contextual knowledge necessary to understand an observation or interview. On the upside, group members can provide contextualization, and the relative outsiders are positioned to achieve analytic distance. In other words, collaboration between different types of participants leads to both familiarity and distance. [8]
OOR is based on insights from the study of scientific practice that suggest that knowledge is produced in interactions between humans, technologies and objects being studied (STAHL, KOSCHMANN & SUTHERS, 2006). OOR deliberately designs an "interpretive zone" (WASSER & BRESLER, 1996), where "multiple viewpoints are held in dynamic tension, as a group seeks to make sense of fieldwork issues and meanings" (p.6). This makes sense because a larger number of participants can more effectively draw out the range of potential interpretations of a social phenomenon, including the interpretations of non-academics (SWEENEY, GREENWOOD, WILLIAMS, WYKES & ROSE, 2013). CORNISH, GILLESPIE and ZITTOUN (2013) therefore suggest basing collaborative research on perspectivism. This concept suggests that "all knowledge is relative to a point of view and an interest in the world" (p.80). Furthermore, "from a perspectivist point of view, the attraction of collaborative data analysis is that it brings a diversity of perspectives to the analysis" (ibid.). [9]
However, perspectivism comes with a challenge: imagine a team of 100 members looking at the same material. Do we end up with 100 or more perspectives? How do we reduce these varied views into meaningful content? [10]
We do not think that perspectivism presents greater threats for collaborative research than individual research endeavors. From our experience as researchers and methodologists, we conclude that for any given matter, researchers can achieve interpretive diversity, and the number of sensible interpretations is limited. The quantity of perspectives need not increase with the number of participants because perspectives can also be properties of groups. The research practice determines whether perspectives emerge at the individual or group level. Expanding and improving collaboration could thus lead to a set of valid interpretations obtained within a single project, compared to a range of interpretations acquired in multiple single researcher projects. More precisely: criteria and good practices to assure validity are built into online collaboration. OOR shifts attention to the analysis phase and aims to enhance validity through joint interpretation by acknowledging that valid claims need reflection and disagreement. Incorporating different perspectives may increase the validity of findings, as this adds information and reduces errors. Working collaboratively can enhance the credibility of the results through what GUBA and LINCOLN (1989, p.238) have termed "progressive subjectivity": the continuous and collective (instead of individual) reflection on the constructs developed through collaborative interpretation. [11]
In OOR, participants are put in a position to agree or to agree to disagree. The ensuing deliberation fosters congruence: agreement on a set of alternative competing interpretations (FISCHER, 1998; SWEENEY et al., 2013). Because participants share a common goal, coordination is in part achieved by adjustments made vis-à-vis other participants. This process of "mutual adjustment" (HALL, LONG, BERMBACH, JORDAN & PATTERSON, 2005) reduces complexity as well as the number of valid interpretations, compared to multiple single researcher projects. In OOR, participants repeatedly compare interpretations in groups that are larger than common research teams. This systematic comparison of interpretations among participants facilitates the emergence of patterns of interpretations among analysts. [12]
Since all interpretations can be continuously debated, regular issues of inter-participant reliability become less salient. Therefore, measures of intercoder reliability, as they are used in content analysis (such as Krippendorff's Alpha (KRIPPENDORFF, 2004)), are less relevant. [13]
Lastly, by using collaborative interpretation rather than codes, we try to avoid mechanistic coding, which commonly presents problems; this is particularly seen among new users in code based analysis software (MacMILLAN, 2005). Even though codes are or should be defined in terms of an intended interpretation, these interpretations can get lost in the coding process. While coding requires some training, interpreting and discussing information are everyday competencies and are thus better suited for citizen science. [14]
A problem might arise here. Can sparsely trained participants go beyond common sense? Is it possible for team members to bracket their presuppositions and move from "first" to "second order constructs" (SCHÜTZ & LUCKMANN, 1973)? Again, our reply is optimistic. Personally, as teachers and team researchers, we have observed that non-academics or juniors can be introduced to social science concepts and quickly learn to apply them productively (see for example how coders were trained in membership categorization analysis in MOERMAN, 2010). As HOUSLEY and SMITH (2011) show, categories for analysis are commonly created in dialogue. Non-academics, moreover, are not cultural dopes and are already assessing the workings of daily social life. In addition, collaboration supports learning and reflexivity (BARRY, BRITTEN, BARBER, BRADLEY & STEVENSON, 1999, SAUERMAN & FRANZONI, 2015). Participants are confronted with data from different contexts alongside multiple interpretations. Discussing interpretations can help with the identification of common sense: academic and non-academic participants can ask for explications and question the assumptions of other participants. Thus, they are able to move from first order to second order constructs. [15]
4. From Crowd Wisdom to Collaboration
Finally, we want to distinguish OOR and collaborative research from collective intelligence and "wisdom of the crowd." They are similar, but "collective" stresses that intelligence is a property of the group, while "collaborative" prioritizes action. [16]
The classic wisdom of the crowd examples offers numerical estimates by large groups (height of building, weight of a cow). After averaging, these are more precise than individual estimates and are almost as accurate as measurements (GALTON, 1907). The reliability of wisdom of the crowd is based on the fact that people's answers are diverse but are normally distributed around a correct answer (which is also the case for algorithm based text analysis). Interpretive research does not presuppose one correct answer or a normal distribution of interpretation. Therefore, "averaging" interpretations does not lead to enhanced results; nevertheless, frequencies of shared interpretations can be useful, for example for an analysis of discursive dominance. [17]
Research into wisdom of the crowd seems to suggest that one needs to avoid groupthink or tunnel vision (LORENZ, RAUHUT, SCHWEITZER & HELBING, 2011), although there is some discussion about this (FARRELL, 2011). Agreement between group members does not necessarily imply correct answers. Wisdom of the crowd and collective intelligence are more strongly debated for looming collectivism (TAPSCOTT & WILLIAMS, 2008) and the threat of the imposition of one truth. This is sometimes called "digital Maoism," alluding to Mao Zedong's totalitarian rule in China (LANIER, 2006). This reminds us that collaboration must not be equated with agreement or majority rule. Instead, "minority reports" are essential for establishing a varied—most likely limited—number of interpretations. [18]
5. Collaborative Science Projects
Many of the caveats mentioned so far stem from research on small group collaboration. These collaborations most often take place face-to-face and within an individualizing culture. In the next paragraph, we consider if and how existing online collaboration in larger groups offers a way forward for large scale social science research. Wikipedia is a prime example that suggests that online, asynchronous and anonymized collaboration can lead to quality knowledge. [19]
An early attempt at collaborative research in social science is mass-observation (WILLCOCK, 1943). Mass-observation originated in Great Britain in 1937. It involves several hundred observers who take notes of their daily lives in the form of diary entries or semi-structured surveys. Their data is later analyzed by academics. Mass-observation has raised a number of questions that are pertinent for OOR: it can potentially breach privacy since the observation of daily life can include sensitive information about others. Mass-observation might also resonate with populism, the glorification of ordinary life or surveillance culture. Importantly for OOR, mass-observation did not include the joint analysis of material. [20]
FRANZONI and SAUERMAN (2014) provide an overview of current open online and citizen science projects and tools. Looking at 31 projects, they organize the field by means of two dimensions: open participation and sharing of intermediate results (data and analysis). They identify numerous classification and tagging tools and a couple of examples involving more complex problem solving. According to FRANZONI and SAUERMAN, it is difficult to attract complex interdependent contributions, which explains why most projects are in the lower left corner of the figure below.
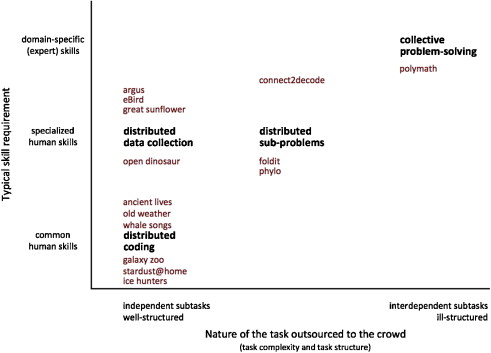
Figure 1: Open online and citizen science projects and tools according to FRANZONI and SAUERMAN (p.13) [21]
FRANZONI and SAUERMAN do not report on social science projects and hardly refer to research in the humanities (for crowd science in the humanities see: DUNN & HEDGES, 2012). We also had a hard time locating relevant open online social science and humanities research projects, and interpretive projects seem completely absent from the field. Many of the examples studied by FRANZONI and SAUERMAN (2014) have single solutions or delineated tasks as (intermediate) outcomes. [22]
Our group has looked at 30+ cases of collaborative research, some of which were studied by FRANZONI and SAUERMAN. They range from strictly scientific (e.g., Polymath, a blog hosting collaborative mathematical research projects) to entertaining, and from facilitated collaboration without a predefined goal (e.g., Truthmapping, a tool to structure discussions about arguments) to single purpose designed tools (e.g., decision making in collaborative internet chess). Twenty-four cases were analyzed for degrees of participation and scientific results using a combination of qualitative comparative analysis and framework analysis (WESTER, 2014). We found that it is possible to involve large numbers of contributors and arrive at scientifically relevant results if the following conditions are met: contributors feel they are personally making socially relevant contributions (hero), dialog about interpretations is encouraged (dialog), and the software includes game elements (game). For scientific results in particular, a feeling of group-membership (tribe) also seems crucial. [23]
5.1 Qualitative data analysis (QDA) tools
The analysis of qualitative material is now routinely supported by software packages, particularly for organizing, exploring, interpreting/reflecting and integrating data (GILBERT et al., 2014). Generally, steps are taken non-linearly or iteratively, and the core analytic tasks are code-assigning and memo-writing. The development of web 2.0 (interactive sites, mobile tools, multi-media, social media) might impact QDA tools. Specifically, new possibilities for collaboration and web-based tools could emerge as GILBERT et al. argue and summarize (see Table 1).
|
|
QDA |
Web 2.0 |
|
Organizing tools |
Coding |
Tagging |
|
|
Sets, families |
Grouping |
|
|
Hyperlinking |
Hyperlinking |
|
Reflective tools |
Memoing |
Blogging |
|
|
Annotating |
Annotating |
|
|
Mapping |
Mapping |
|
Exploring tools |
Model, map, network |
Visualizing |
|
|
Text search, coding search |
Searching |
|
Integrating tools |
Memoing with hyperlinks |
Blogging with hyperlinks |
|
|
Merging projects |
Collaborating through wikis |
Table 1: QDA and Web 2.0 tools according to GILBERT et al. (p.233). [24]
We have tested a range of existing tools that have the potential to perform collaborative open online qualitative research. Established packages like Atlas.ti or NVIVO offer multiple analytic, reporting and output functionalities, including collaborative features. The packages were originally tailored for single academic researchers. In recent years, developers have advanced the software to facilitate (small) team projects. These tools do not fully enable online synchronous collaboration. For team projects, users have to work independently and combine their results after tasks have been performed. The common QDA tools necessitate training before collaboration begins, are better suited for smaller teams and do not work as well if project participants are based in regions with weak internet connections. [25]
Dedoose is a more recent web-based tool. It was built for online team-ethnographies (LIEBER, WEISNER & PRESLEY, 2003). It is similar to the packages mentioned above—code based interpretation and note-writing functionalities—and enables full online collaboration. Dedoose is easier to use than traditional CAQDAS packages but is still too complex for uninitiated users. The ability to code collaboratively online brings to the fore an important analytic question for inductive or iterative coding strategies: should researchers see existing codes before getting acquainted with material? The CAT tool is tackling this by enabling the assignment of "rights" and tasks to users. In CAT you can only code paragraphs and it is better suited for multi-participant codings than for dialogue amongst participants. CAT is free to use and is part of the commercial Discovertext tool, which combines human coding and machine learning (algorithms) to analyze larger quantities of text. Finally, CATMA is the most versatile online tool, allowing separated and joint coding on multiple levels and facilitating discussion through memos. This tool is also the most complex tool and therefore requires more advanced training for use. [26]
Even after selecting a group of highly motivated digitally savvy students as test users, all of the above mentioned tools still require extensive learning in order to enable their contributions. Prism, in contrast, is the only easy tool to use. It is a text highlighting and tagging/coding tool. Prism limits the number of codes to three, and these codes have to be pre-defined. The results are visualized frequencies of codings per text. Due to pre-defined codings and the absence of a discussion function, Prism markedly limits the creativity of users. [27]
A consideration of common analysis tools indicates the limits and challenges of open online collaboration and interpretation in particular. Nevertheless, there are projects and tools that utilize collaborative research, often on a massive scale. We now introduce two examples that offer important insight on collaborative online research. [28]
Wikipedia is arguably the most prominent online collaborative knowledge platform and is reasonably well researched (HILL, 2013, JEMIELNIAK, 2014). Wikipedia does not feature the interpretation of primary sources, but the range of topics and background discussions can be similar to scientific debate. Here, we point to three features that are both promising and disconcerting. [29]
Strong in co-authoring: First, all encyclopedic entries are co-authored online. The authoring software is surprisingly easy, albeit with an outdated user interface. Anyone can author and edit entries anonymously, even without registering as a user or logging in. Everyone who has access to the internet is entitled to change most contributions. Some hotly debated contributions require extra checks by Wikipedians. All efforts come together in one single shared text. This is starkly different from scientific practice, which puts a premium on distinct texts to present different perspectives and ideas; moreover, discussion on scientific research predominantly occurs after a text has been published and is typically a dialogue "between texts." Wikipedia illustrates that texts are dynamic and can absorb a multitude of changing authors and evolving insights. In the words of DE MOOR and KLEEF: "documents are no longer merely a paper-based transport mechanism for preformed ideas, but rather a medium for negotiation within communities, with multiple and complex links between document and discourse" (2005, p.133). Wikipedia's preservation of authors' anonymity and uncompensated contributions radically differ from an organization of science, where credentials and careers are tied to authorship. [30]
In need of moderators: Wikipedia is a half-open institution. To avoid vandalism and settle conflicts, democratically elected Wikipedians have moderating rights, which enabe them to undo changes on a large scale and to block users. Wikipedians have also generated an evolving and growing set of formal rules to guide authors' contributions. In addition, both first-time editors and contributing researchers report strong informal rules or an organizational culture. This is described in terms of a frequently discouraging tone of criticism, the anonymous rejection of edits and bureaucratic and cryptic referrals to rules. The dominant "feeling and framing rules" (HOCHSCHILD, 1979, p.566) in Wikipedia seem to be related to the stark overrepresentation of men (IOSUB, LANIADO, CASTILLO, MORELL & KALTENBRUNNER, 2014). In most languages, more than 80% of the contributors are male. Wikipedia is still growing, but is seems that the number of discussions is growing much faster than page entries, coinciding with the decrease in active contributors (KITTUR, CHI, PENDLETON, SUH & MYTKOWICZ, 2007). Wikipedia reveals that the radical openness which characterized the forum initially, is increasingly filled with formal and informal rules and conflicts (UITERMARK, 2015). A faceless crowd and the high status of open knowledge production may have induced insecurity among potential contributors. This is amplified by the last feature of Wikipedia that we consider: the ambition to achieve consensus. [31]
Forced consensus: Wikipedia claims to be an encyclopedia, which, according to Wikipedians, means that only verifiable (usually) published knowledge can form the basis of a lemma of general interest. A lemma is the result of (temporary) consensus. Disagreement is relegated to the backstage pages where it needs to be settled. This model of "singular undisputed truth" is called into question once we observe that the same lemma has different content in different languages and is disputed2). In contrast with an online encyclopedia, social science research does not necessarily aim to provide a singular "truth." For OOR, this means that we have to adjust collaboration to bring multiple interpretations to the foreground. [32]
Wikipedia has inspired many. For our purpose, the Wiki survey software is relevant. The Wiki survey software builds on users' experiences with Wikipedia and survey-research and aims to integrate the quantitative and qualitative input of respondents. One of the early examples is the "pairwise Wiki survey." It consists of a single question with many possible answers. Respondents can participate in a pairwise Wiki survey in two ways: first, they can make pairwise comparisons between items (i.e., respondents vote between item A and item B), and second, they can add new items that will be presented to future respondents (SALGANIK & LEVY, 2015, p.5). Wiki surveys spread rapidly. In August 2016, 8,681 surveys had been taken and generated almost five hundred thousand ideas and almost 13 million votes3). [33]
SALGANIK and LEVY (pp.3-4) detail the characteristics of ideal Wiki surveys, suggesting they should be greedy, collaborative and adaptive. They should be greedy in the sense that they accept any contributions, regardless of how small or large these are. This is distinct from traditional surveys that require a specified amount of input. A contributor can do one single pairwise comparison, which would take only minutes or work through the whole database. Allowing a range of efforts attracts more and different contributors, conveying "greed" through the prioritization of more participants over the quantity of individual input. The graph below shows the distribution of Wiki survey contributions. It is empirically corroborated by recent research into different collaborative tools (SAUERMANN & FRANZONI, 2015).
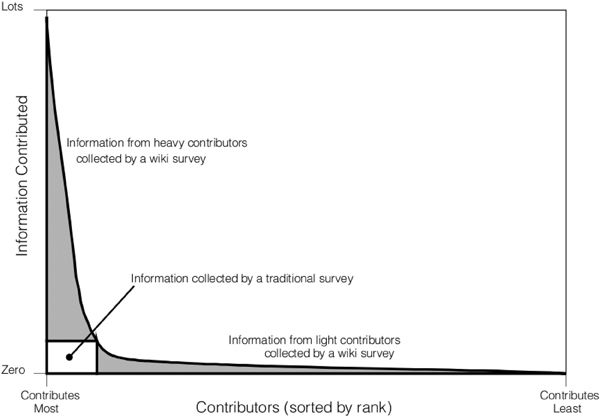
Figure 2: Information and contributors in online information aggregation project according to SALGANIK and LEVY (2015, p.3)
[34]
The next characteristic of Wiki surveys is collaboration. Here, this refers to participants co-constructing surveys by adding items. The role of participants is thus greater than that of "respondents," yet it does not extend to their analysis of the data. The third characteristic, adaptivity, describes how the instrument is continually optimized to elicit the most useful information for estimating the parameters of interest, given what is already known (p.6). The survey evolves according to what is learned from responses and in doing so, becomes more efficient. [35]
Early Wiki survey results provided insight "that is difficult, if not impossible, to gather from a more traditional survey instrument. This unique information may involve both the content of the ideas that are submitted by users and the language used to frame them" (p.16). The Wiki survey delivered additional information (ideas not included in the survey) and alternative framing approaches. [36]
Our tool enables online data collection and extended, sentence-based interpretation as well as participant discussions on interpretations. Collaborators thus are familiar with the data and the context of construction before entering into the analysis. Participants can also ask each other to further contextualize data through online notification and discussion functionalities. The final goal of OOR is to produce different sets of interpretations rather than substantive or formal theories. No consensus is needed in OOR. The tool allows for diverse interpretations, while it simultaneously stimulates participants to ground interpretations and categorize them in order to achieve reduction. In OOR, participants can report on the resultant set of interpretations, or these results can be introduced into a different research project. OOR can be used for responding to any kind of qualitative or interpretive research question; we have already used it to address four radically different topics like emotion in open answers or diversity in public space. [37]
The OOR interface builds on common web applications to facilitate its use and enable the participation of largely untrained citizens. OOR software and data are situated online and allow multiple academics and non-academics to work on a project simultaneously and utilize chat and notification functionalities. Similar to web tools in other domains, OOR supports inclusiveness by allowing participants to contribute to various extents and to take on different roles. Our tool fosters citizen-science through the individual learning processes of the participants and the collective development of a diverse and valid set of interpretations. In the future, these collaborative features will be connected to open access publishing and crowdsourcing of research questions and finances, which is to say, a full collaborative open online research process. [38]
OOR differs from current CAQDAS tools in several ways: OOR prioritizes the constant comparison of extended interpretations by multiple researchers. In contrast, many current tools have been developed based on codes, data-code and code-code comparisons made by single researchers. Our decision to work with sentence-based extended interpretations rather than codes is inspired by our experience with existing CAQDAS tools; we have found that coding can distract the (junior) researcher from the importance of code-definitions and memo writing (MacMILLAN, 2005). In that sense, constant memo writing and collaborative memo-memo comparisons are crucial for OOR. According to PAULUS and LESTER (2015), this is similar to grounded theory methodology or discourse analysis. The focus is much less on the emergence of concepts and categories than on the emergence of different interpretations. [39]
To bring about the ambitions outlined above, we iteratively developed software tools and a methodology. In the following three phases, we gradually came closer to a productive, functional tool. [40]
7.1 Tool 1: Tweaking Media Wiki software
Between January 2014 and September 2014, we developed and tested the first software for collaborative open interpretive research. In this phase, the core team consisted of scientific staff from the sociology department, educational technology experts from the graduate school, information specialists from the university library and from the psychology department, freelance developers and social science students participating as part of a course. [41]
The tool had to meet the following requirements: 1. the facilitation of data integration, coding, interpretation and discussion on a platform; 2. the use of a clear layout and instructions that make the tool easily accessible to both academics and non-academics; 3. the ability to stimulate active involvement and ongoing discussion; 4. the possibility for collaboration on conclusions. [42]
In this phase, we welcomed contributions from anyone interested in collaborating, regardless of academic background. Nevertheless, most contributors appeared to be part of our own social network. We were reminded that inclusiveness has to be cultivated and is not the same as openness. [43]
These considerations resulted in the development of two prototypes. The first tool uses Media Wiki software for data management and coding and was called TZN (abbreviation of "Tool Without a Name" in Dutch). The tool worked reasonably well when tested. However, it still required a considerable learning effort. While this does not deter dedicated users, it discourages those who wish to contribute minimally. We also experienced the need for ongoing, active encouragement to stimulate discussion. Moreover, the first tool did not allow participants to upload material. Thus, in Phase 2, we developed the second prototype, based on different existing tools. [44]
7.2 Tool 2: Tweaking Disqus software and the #ethnography conference
In the next phase, the software was used by a group of academics at the 2014 #ethnography conference of the European Sociological Association RN20 in Amsterdam. [45]
Conference participants were asked to collect observations, upload them and interpret them online. The tool basically combined Disqus and Wordpress software and a purpose built database. We called it Crowdedtheory4). Through Disqus, participants could easily leave comments as well as vote in favor of or against other interpretations to express their perspectives. We enabled participants to upload photos and texts in different formats. The following features were available in this tool:
one central user interface with basic instructions;
ability to upload pictures or texts or combinations from any device;
per item interpretation, in random order or self-selected;
interpretation fields (interpretations are in the format of sentences and can be edited following discussions);
discussion and voting (as a proxy for agreement) on interpretations;
access to debates about interpretations and participants;
overview and browsing of "votes";
a separate page for discussions about methods and conclusions;
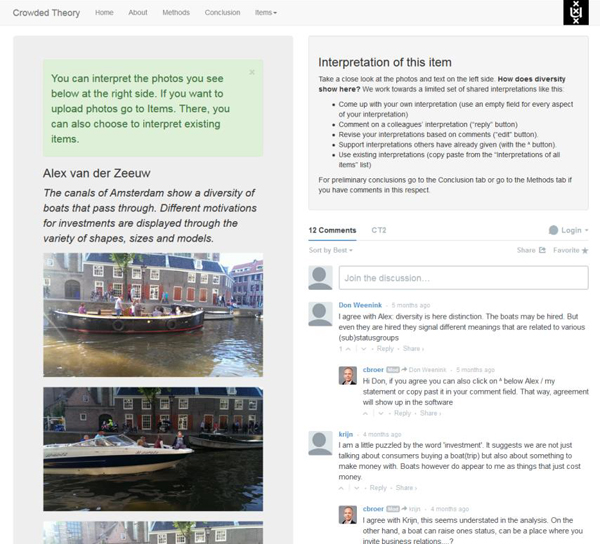
Figure 3: The main page of Crowdedtheory tool [46]
In the run up to the conference, all attendees were invited to join the test and received basic information. At the conference itself—lasting 44 hours—the following activities related to the test:
First evening: three lectures on 1. mass-observation, 2. the research theme, and 3. the test itself. Attendees were asked to go into the city center of Amsterdam in small groups immediately after the lecture and to take photos or notes relating to diversity. Those photos and notes had to be uploaded to the webtool. We had assistants for the city walk and for uploading pictures.
Second day: participants could still upload material and were instructed to start interpreting their own and others' contributions. Our team participated online and was available to answer questions.
Third day: participants were asked to continue interpreting photos and notes and to make methodological or theoretical statements. In the afternoon, we presented and discussed preliminary results of the test in a plenary. [47]
The tool contained the following instruction on observations on its about page:
"The theme of the observations will be diversity in inner-city Amsterdam. We ask you to stroll through parts of the inner-city and take photos and notes on diversity. Diversity is a highly debated issue and in politics as well as in academia it is assumed that Amsterdam is hyper-diverse. But how does this show? In this experiment, we do not provide you with a definition of diversity. Instead, comparing the photos and notes collectively should provide us with one or—most likely—several grounded definitions. And, this should offer an empirical answer to the question: how diverse is Amsterdam?" [48]
From earlier tests, we learned that it is necessary to provide basic instructions on how to collaborate on interpretations. The main page provided the following instructions:
"Take a close look at the photos and text on the left side. How does diversity show here? We work towards a limited set of shared interpretations like this:
Come up with your own interpretation (use an empty field for every aspect of your interpretation).
Comment on colleague's interpretations ('reply' button).
Revise your interpretations based on comments ('edit' button).
Support interpretations others have already given (with the '^' button).
Use existing interpretations (copy paste from the 'Interpretations of all items' list).
For preliminary conclusions go to the Conclusion tab or go to the Methods tab if you have comments in this respect." [49]
How did the test unfold? The conference was attended by a total of 108 academics (60% women, 15% professors) of all ages and ranks, mainly from Europe and predominantly from sociology departments, assisted by a team of 13 staff members and students. During the conference, 32 attendees uploaded 80 items containing multiple photos and text. Of those 80 items, 24 were not interpreted, 22 had one interpretation, and 34 showed several interpretations or discussions of interpretations. 26 people contributed 166 interpretations in total. [50]
Participants were more often mid-career scholars, while senior full professors were largely absent. Students mostly participated when they had a role or a task within the test, for example providing technical support. There was also a clear gender bias. 70% of those who uploaded items were women, and 60% of those who interpreted material were men. [51]
Throughout the preparation for the test, we noticed that feelings impacted participation. Our student group earlier reported anxieties when contributing to Wikipedia because they feared making a mistake and being criticized "publicly." From informal talks at the conference, we got the impression that this was also relevant in the case of our project. At the final plenary discussion, one junior attendant courageously expressed that she was uncertain about how she would be addressed and evaluated by other participants, which prevented her from contributing. This fear of being exposed has been noted in more online fora (for Wikipedia see: COLLIER & BEAR, 2012). [52]
It seems crucial, therefore, to actively work towards inclusion instead of merely "opening" a project. Furthermore, it is necessary to explicitly attend to the management of emotions, through moderators, user-interface and instructions. The test aimed to enhance collaboration and ground interpretations in data. The amount of data and interpretations suggest that this was achieved to some degree. In the beginning of the project, photos of diversity were added, but there were not many notes. It is possible that the vibrant and photogenic city triggered the practice of photography. Later on, participants began to use more texts to describe what they saw and increasingly offered their own interpretations of pictures. However, during the first 24 hours, interactions about interpretations remained limited. Participants filed their own interpretations but rarely responded to the interpretations of others. Moreover, the interpretations tended to be straightforward descriptions. Instead of addressing the research question (how does diversity show?), the interpretations referred to tourism, "skin color" or different cuisines as examples of diversity. Take for example two pictures out of an item containing eight pictures along with the following text:
"Diversity of different kinds of space in Amsterdam is really huge: not far from the crowded touristic centre you can find calm little streets, near clean buildings—buildings full of graffiti. In Amsterdam you even don't know when you've just come out from Red Light District and entered China Town" (Tool 2).

Figure 4-1: Examples of uploaded data, Part1

Figure 4-2: Examples of uploaded data, Part 2 [53]
Descriptions like this led to discussions. For example, one of the organizers asked:
"I really like the images. And I see the diversity in the crowd, the shops and even institutionalised in the street signs. But how do you see it in the graffiti? (ibid.). [54]
Gradually, participants started to react and respond verbally or with upvotes (55 votes concerning 31 items). The research questions and more profound questions on the meaning of diversity became more central, particularly among a small number of participants and after the conference ended. Participants discussed how to interpret sexuality in public space as one can see in the exchange below. The picture shows the window of a sex shop. It was interpreted in three different ways. Collaborator 1, a moderator, tries to introduce an interpretation related to the research question, which is questioned ("I rather") by Collaborator 2. Collaborator 3 adds another interpretation.

Figure 5: Example of uploaded data
Collaborator 1: "Diversity shows through different ways of regulating sexuality."
Collaborator 2: "I rather see homogenization of motives, symbols and artifacts into one new unity. The diversity of pieces creates similarity of the whole."
Collaborator 3: "sexual diversity in sex gadgets" (Tool 2). [55]
The discussion was quite extensive at times, going back and forth, including attempts to settle an issue. Item 25 for example triggered five different participants to file ten different comments, with fairly precise questions and answers to the participants and in relation to data. This exchange included attempts to arrive at generalizations like this: "Indeed diversity is so common here that it becomes even unified and sometimes indistinguishable. Omnipresence mashes diversity." [56]
In relation to sexuality in public space, the up- and down voting tool of the software enabled several participants to agree with a specific interpretation. Below, you can see that the interpretation used by C1 (Collaborator 1) above, "Diversity shows through different ways of regulating sexuality," is used again for another document. Note that below the interpretation, there is an upward and a downward arrow for voting. In this case, the interpretation is voted once. Thus, agreement can be reached by re-using and voting for interpretations.
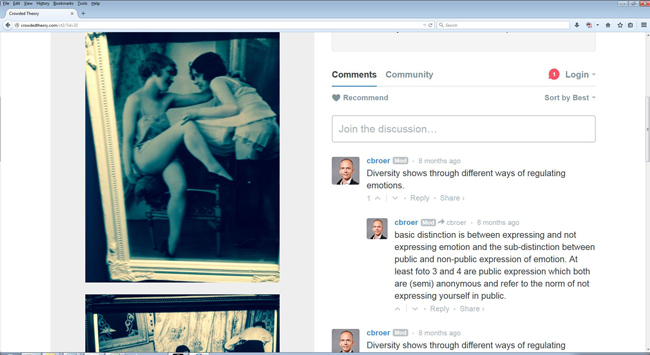
Figure 6: Example of uploaded data and interpretations [57]
Ultimately, the most extended discussion concerned the relevance of skin color, family name or ascribed ethnic categories for assessing diversity. This discussion moved from the interpretation page to the separate conclusion page, where seven participants posted fourteen texts. Here, the participants uttered a range of reflexive remarks like this:
Conclusion, C6: "I really liked this innovative addition to the conference. At the same time we were set a curious challenge. The brief to go out and see 'how diversity shows itself' suggested that 'diversity' was readily available and could be 'seen.' When looking at the contributions one is struck wondering what it is that we, the observers, bring to this task? Which expectations, viewing habits, and embodied identities guide what we see ... What do those see who are residents of the city, and those who have never been there before? And suddenly this becomes rather interesting ethnographically" (Tool 2). [58]
However, if diversity is more than meets the eye—if it is indeed a safe space for being different (or even a space of equal opportunities)—then walking around and looking will not yield sufficient answers. [59]
Our test showed that open online interpretation and collaboration in the social sciences is possible and that software to aid this is feasible. The software tools we developed were stable and enabled some degree of collaboration. Even though the participants in the #ethnography conference test were trained social scientists, they did not immediately work within the framework of the research, nor did they follow the instructions to work towards shared understandings. This improved over the course of two days. As is often the case in open online projects, some collaborators contributed a little and other a lot, capitalizing on the smaller contributions of others. [60]
There was a gender bias in the sense that women contributed relatively more material and relatively less interpretations. Additionally, early and late career scholars were largely absent. As mentioned above, it seems crucial to actively work towards inclusion instead of merely "opening up" a project. Furthermore, explicit attention towards emotion management seems necessary. The fear of making stupid remarks or being judged hinders individuals' collaborative efforts. [61]
Many interpretations were not initially refined, rejected or repeated. Still, participants did provide interpretations and interacted in a way that enhanced the depth and precision of the interpretations. The aggregation of findings was partly supported through the voting option and the conclusion page. Participants initially hardly worked towards aggregation. We suspect this is partly due to the conference format, which leaves very little time for in-depth analysis. Another reason is the way the software is designed. We used existing social media tools and tweaked them. These tools still "aired" individualism: every contribution is personalized (name, photo), and it is impossible to edit the interpretations of others (as for example is the case with Wikipedia). The discussion is presented as a potentially endless thread or blog. All of this does not stimulate collaboration, aggregation or reduction. Repeated and explicit calls to collaboration (e.g., to copy and paste interpretations one agrees with) did not have much effect in the beginning. Over the course of several days, though, substantive and grounded interpretations emerged and were flanked by debates about the test. [62]
Attempts to be open and inclusive cannot not mask the fact that collaboration also depends on perceived interests. For mid-career scholars, our test might add to their aspirations. For students, learning might be more attractive once it is credited study-points or certificates, which is why we will embed the next test in an online course. [63]
7.3 Phase 3: A purpose built tool
Learning from the first tests, we have since built fully new and dedicated software that includes the previously mentioned functionalities and further develops the constant comparison of interpretations. Collaborators upload data (if they wish) and then interpret other data. After they have written up one or more interpretations, they are asked to compare these with existing interpretations linked to that piece of data. Collaborators are asked to "stack" or group interpretations that are similar, thereby constantly comparing and reducing the interpretations. Below, you can see a screenshot of one step in the stacking process. Interpretation and stacking continue per piece of data until the data is saturated (saturation can be measured as the non-occurrence of new stacks). Later, interpretations attached to one piece of data can be used for other pieces of data. This is the core process of our recent tool, which also includes notification, discussion, moderation and co-authoring functions. OOR will be tested in Coursera in a research course in 2017.
Figure 7: The current OOR tool's "compare interpretations" page [64]
OOR is based on the premise that (social) science insights emerge out of the repeated interactions between humans, technologies and objects of study over the full course of the research process (STAHL et al., 2006). While this might be obvious, the stand-alone brilliant mind model is prominent in social science and is stressed in the race for output and excellence. At the same time, ethics of openness and sharing are very much alive, especially in citizen science. Inspired by small-team collaboration and advances in digital media and software, we wondered if in-depth and large-scale interpretive analysis was possible beyond small teams. To investigate this, we developed and tested software. [65]
OOR assists in adding information, correcting blind spots and comparing interpretations. It provides an "interpretive zone" (WASSER & BRESLER, 1996) and brings together interpretations to make them explicit and ground them, to inspire new interpretations and stimulate agreement and convergence. This facilitates the emergence of shared knowledge during data collection and analysis, instead of after publication. This learning process goes beyond perspectivism (CORNISH et al., 2013) or crowd wisdom. Our tests indicate that easy-to-use online collaboration brings to the fore the diversity in shared interpretations through "stacking" and the online organization of saturation. [66]
An easy-to-use interface facilitates the involvement of non-academics (SWEENEY et al., 2013). While this might lead to the exploitation of free labor, this is not really an issue since "free labor" necessitates a lot of work by core team members and editors. Collaborative research is not cheaper or faster, but it can involve more (lay) researchers in the same time span. [67]
Working in dispersed groups is enabled by software technologies that are similar to those of social media. The experience with existing online platforms shows, however, that the social "technologies" are no less important. The local culture within an online community is key for the diversity of collaborators and the quality of their contributions. [68]
In short, our tests suggest that the OOR tool is able to do the following:
enable collaborative learning during research;
revolve around full-text interpretation, instead of coding/tagging;
enable the co-authoring of interpretation;
move from individual to shared interpretations;
make visible the diversity in interpretations/minority reports;
strive for the reduction of diversity through mutual adjustment;
ground interpretations in the analysis of empirical data;
allow for collaboration based on minimal training and enable learning about methods and concepts throughout the collaborative process;
make use of existing knowledge and the ability to learn;
make use of any contribution regardless of how small or large, using different skills and motivations of participants;
enable synchronous and asynchronous collaboration;
stimulate both heroic feelings ("I made a relevant contribution") and feelings of belonging ("I am part of a group");
foster a diverse and emotion-sensitive practice where hierarchical differences, doubts and fear of exposure do not hamper collaboration;
avoid the suggestion that the tool itself provides an analysis. [69]
These features can be utilized in blended and online learning; in multi-sited and group based academic research and in research involving a greater number of citizens who are specifically invested in or experienced with regards to an issue. [70]
Our tests confirmed that valid and relevant interpretive knowledge can be produced through the online collaboration between humans, technologies and objects of study. It revealed not only the usefulness of open online research in qualitative social science research but also its potential and pitfalls. At present, we are further improving the tool and methodology and testing it in online learning environments. [71]
1) Christian BRÖER (0,2,3), Gerben MOERMAN (1,2,3), Johan Casper WESTER (1, 2, 3), Liza Rubinstein MALAMUD (1,2), Lianne SCHMIDT (1,2), Annemiek STOOPENDAAL (1,3), Nynke KRUIDERINK (2), Christina HANSEN (3), and Hege SJØLIE, (3) contributed in the following ways: 0: lead author, 1: coauthoring this article, 2: designing the software and tests, 3: uploading and interpreting data. The first author wrote the drafts for the first and second submission, which were then collaboratively rewritten in google-docs. Editing was provided by Gail ZUCKERWISE. Assistance was provided by Siebert WIELSTRA. The article was rewritten after the productive comments of two external reviewers and with guidance by the journal editor Katja MRUCK. <back>
2) For disputes see https://en.wikipedia.org/w/index.php?title=Wikipedia:List_of_controversial_issues&oldid=640343618 and contropedia.net/#case-studies [Accessed: August 15, 2016]. <back>
3) See http://www.allourideas.org/ [Accessed: August 15, 2016]. <back>
4) In this round of our try outs, we used a login to be able to prevent unwanted intrusion. Login: sociology. <back>
Barry, Christine; Britten, Nicky; Barber, Nick; Bradley, Colin & Stevenson, Fiona (1999). Using reflexivity to optimize teamwork in qualitative research. Qualitative Health Research, 9(1), 26-44.
Bryman, Alan (2008). Social research methods (3rd ed.). Oxford: Oxford University Press.
Burawoy, Michael (2005). For public sociology. American Sociological Review, 70(1), 4-28
Carvajal, Diogenes (2002). The artisans tools. Critical issues when teaching and learning CAQDAS. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 3(2), Art. 14, http://nbn-resolving.de/urn:nbn:de:0114-fqs0202147 [Accessed: August 22, 2016].
Collier, Benjamin & Bear, Julia (2012). Conflict, criticism, or confidence: An empirical examination of the gender gap in Wikipedia contributions. In Steven Poltrock & Carla Simone (Eds.), Proceedings of the ACM 2012 conference on computer supported cooperative work (pp.383-392). New York: ACM.
Cornish, Flora; Gillespie, Alex & Zittoun, Tania (2013). Collaborative analysis of qualitative data. In Uwe Flick (Ed.), The Sage handbook of qualitative data analysis (pp.79-93). London: Sage.
De Moor, Aldo & Kleef, Rolf (2005). A social context model for discussion process analysis. In Lorentz M. Hilty, Eberhard K. Seifert & René Treibert (Eds.), Information systems for sustainable development (pp.128-145). London: Idea Group Publishing.
Dunn, Stuart & Hedges, Mark (2012). Crowd-sourcing scoping study-engaging the crowd with humanities research. Centre for E-Research, King's College London, UK, http://crowds.cerch.kcl.ac.uk/wp-content/uploads/2012/12/Crowdsourcing-connected-communities.pdf [Accessed: August 22, 2016].
Farrell, Simon (2011). Social influence benefits the wisdom of individuals in the crowd. Proceedings of the National Academy of Sciences of the United States of America, 108(36), E625, http://www.pnas.org/content/108/36/E625.full.pdf [Accessed: August 25, 2016].
Fischer, Frank (1998). Beyond empiricism: Policy inquiry in post positivist perspective. Policy Studies Journal, 26(1), 129-146.
Flick, Uwe (2011). Introducing research methodology: A beginner's guide to doing a research project. London: Sage.
Franzoni, Chiara & Sauermann, Henry (2014). Crowd science: The organization of scientific research in open collaborative projects. Research Policy, 43(1), 1-20.
Galton, Francis (1907). Vox populi. Nature, 75, 450-451.
Gilbert, Linda S.; Jackson, Kristi & di Gregorio, Silvana (2014). Tools for analyzing qualitative data: The history and relevance of qualitative data analysis software. In Michael J. Spector, David M. Merrill, Jan Elen & M.J. Bishop (Eds.), Handbook of research on educational communications and technology (pp.221-236). New York: Springer.
Guba, Egon G. & Lincoln, Yvonna S. (1989). Fourth generation evaluation. Newbury Park, CA: Sage.
Hall, Wendy A.; Long, Bonita; Bermbach, Nicole; Jordan, Sharalyn & Patterson, Kathryn (2005). Qualitative teamwork issues and strategies: Coordination through mutual adjustment. Qualitative Health Research, 15(3), 394-410.
Hammersley, Martyn (2010). Can we re-use qualitative data via secondary analysis? Notes on some terminological and substantive issues. Sociological Research Online, 15(1), 5, http://www.socresonline.org.uk/15/1/5.html [Accessed: August 22, 2016].
Hill, Benjamin Mako (2013). Essays on volunteer mobilization in peer production. Doctoral dissertation, management and media arts and sciences, Massachusetts Institute of Technology, Cambridge, MA, USA.
Hochschild, Arlie Russel (1979). Emotion work, feeling rules and social structure. American Journal of Sociology, 85(3), 551-575.
Housley, William & Smith, Robin James (2011). Telling the CAQDAS code: Membership categorization and the accomplishment of "coding rules" in research team talk. Discourse Studies, 13(4), 417-434.
Iosub, Daniela; Laniado, David; Castillo, Carlos; Morell, Mayo Fuster & Kaltenbrunner, Andreas (2014). Emotions under discussion: Gender, status and communication in online collaboration. PloS One, 9(8), http://dx.doi.org/10.1371/journal.pone.0104880 [Accessed: August 22, 2016].
James, Allison (2012). Seeking the analytic imagination: Reflections on the process of interpreting qualitative data. Qualitative Research, 13(5), 562-577.
Jemielniak, Dariusz (2014). Common knowledge?: An ethnography of Wikipedia. Stanford, CA: Stanford University Press.
Kittur, Aniket; Chi, Ed; Pendleton, Bryan A; Suh, Bongwon & Mytkowicz, Todd (2007). Power of the few vs. wisdom of the crowd: Wikipedia and the rise of the bourgeoisie. World Wide Web, 1(2), 19, http://www-users.cs.umn.edu/~echi/papers/2007-CHI/2007-05-altCHI-Power-Wikipedia.pdf [Accessed: August 25, 2016].
Krippendorff, Klaus (2004). Content analysis: An introduction to its methodology (2nd ed.). Thousand Oaks, CA: Sage.
Lanier, Jaron (2006, May 29). Digital Maoism: The hazards of the new online collectivism. Edge, https://www.edge.org/conversation/jaron_lanier-digital-maoism-the-hazards-of-the-new-online-collectivism [Accessed: August 22, 2016].
Lieber, Eli; Weisner, Thomas S. & Presley, Matthew (2003). EthnoNotes: An internet-based field note management tool. Field Methods, 15(4), 405-425.
Lincoln, Yvonna S. & Guba, Egon G. (1985). Naturalistic Inquiry. London: Sage.
Lorenz, Jan; Rauhut, Heiko; Schweitzer, Frank & Helbing, Dirk (2011). How social influence can undermine the wisdom of crowd effect. Proceedings of the National Academy of Sciences of the United States of America, 108(22), 9020-9025.
MacMillan, Katie (2005). More than just coding? Evaluating CAQDAS in a discourse analysis of news texts. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 6(3), Art. 25, http://nbn-resolving.de/urn:nbn:de:0114-fqs0503257 [Accessed: August 25, 2016].
Miles, Matthew B. & Huberman, A. Michael (1994). Qualitative data analysis: An expanded sourcebook (2nd ed.). Thousand Oaks, CA: Sage.
Moerman, Gerben (2010). Probing behaviour in open interviews. Doctoral dissertation, sociology, Vrije Universiteit, Amsterdam, The Netherlands.
Orlikowski, Wanda J. (2005). Material works. Exploring the situated entanglement of technological performativity and human agency. Scandinavian Journal of Information Systems, 17(1),183-186.
Paulus, Trena M. & Lester, Jessica N. (2015). ATLAS.ti for conversation and discourse analysis studies. International Journal of Social Research Methodology, 19(4), 405-428.
Salganik, Matthew J. & Levy, Karen E.C. (2015). Wiki surveys: Open and quantifiable social data collection. PLoS ONE, 10(5), http://doi.org/10.1371/journal.pone.0123483 [Accessed: August 25, 2016].
Sauermann, Henry & Franzoni, Chiara (2015). Crowd science user contribution patterns and their implications. Proceedings of the National Academy of Sciences of the United States of America, 112(3), 679-684.
Scardamalia, Marlene & Bereiter, Carl (2014). Smart technology for self-organizing processes. Smart Learning Environments, 1(1), 1-13.
Schratz, Michael & Walker, Robert (2005). Research as social change. New York: Routledge.
Schütz, Alfred & Luckmann, Thomas (1973). The structures of the life-world. Evanston, IL: Northwestern University Press.
Silverman, David (2001). Interpreting qualitative data: Methods for analysing talk, text and interaction (2nd ed.). London: Sage.
Silverman, David (2005). Doing qualitative research: A practical handbook (2nd ed.). London: Sage.
Stahl, Gerry; Koschmann, Timothy & Suthers, Dan (2006). Computer-supported collaborative learning: An historical perspective. In R. Keith Sawyer (Ed.), Cambridge handbook of the learning sciences (pp.409-426). Cambridge: Cambridge University Press
Sweeney, Angela; Greenwood, Kathryn E.; Williams, Sally; Wykes, Til & Rose, Diana S. (2013). Hearing the voices of service user researchers in collaborative qualitative data analysis: The case for multiple coding. Health Expectations, 16(4), e89-e99.
Tapscott, Don & Williams, Anthony D. (2008). Wikinomics: How mass collaboration changes everything. New York: Penguin.
Uitermark, Justus (2015). Longing for Wikitopia: The study and politics of self-organisation. Urban Studies, 52(13), 2301-2312.
Van den Berg, Harry (2005). Reanalyzing qualitative interviews from different angles: The risk of decontextualization and other problems of sharing qualitative data. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 6(1), Art. 30, http://nbn-resolving.de/urn:nbn:de:0114-fqs0501305 [Accessed: August 25, 2016].
Wasser, Judith Davidsson & Bresler, Liora (1996). Working in the interpretive zone: Conceptualizing collaboration in qualitative research teams. Educational Researcher, 25(5), 5-15.
Wester, Johan. C. (2014) Samen staan we sterker: Een mixed methods onderzoek naar collaboratieve interpretatie met behulp van qualitative comparative analysis en framework analyse [Stronger together. A mixed methods research of collaborative interpretation using qualitative comparative analysis and framework analysis]. Bachelor Thesis, sociology, University of Amsterdam, The Netherlands.
Willcock, H. D. (1943). Mass-observation. American Journal of Sociology, 48(4), 445-456.
Wuchty, Stefan; Jones, Benjamin F. & Uzzi, Brian (2007). The increasing dominance of teams in production of knowledge. Science, 316(5827), 1036-1039.
Christian BRÖER is associate professor in sociology at the University of Amsterdam and head of the program group Political Sociology. His central scientific concern is with the social origins of problems as diverse as bodily overactivity, sadness, overweight or aircraft noise. Particularly he aims to find out how the experience of a problem and political processes interact.
Contact:
Christian Bröer
University of Amsterdam
Department of Sociology
PO Box 15508
1001 NA Amsterdam, The Netherlands
Tel: + 31 20 525 2238
E-mail: c.broer@uva.nl
URL: http://www.uva.nl/en/profile/c.broer
Gerben MOERMAN is senior lecturer in social research methodology at the University of Amsterdam. His expertise lies in the field of qualitative research and mixed methods. Specifically, he works on interaction in various forms of interviewing and teaches different forms of qualitative analysis such as grounded theory methodology, content analysis, discourse analysis and ethnomethodology. He is the current chair of ESA RN20 on Qualitative Methods.
Contact:
Gerben Moerman
University of Amsterdam
Department of Sociology
PO Box 15508
1001 NA Amsterdam, The Netherlands
Tel: + 31 20 525 2674
E-mail: gmoerman@uva.nl
URL: http://www.uva.nl/en/profile/g.moerman
Johan Casper WESTER is a research master student in the social sciences program of the University of Amsterdam, Graduate School of Social Sciences.
In his bachelor thesis, he wrote about the factors contributing to the success of online citizen science projects. Throughout
his education, he has pursued a strong methodological interest in both quantitative and
qualitative applications, as well as their interplay. He has been working as a student assistant for the office of ICT in
education for over two years.
Contact:
Johan Wester
ICT in Education for Social Sciences, room B7.08
University of Amsterdam
Nieuwe Achtergracht 166
1018 WV Amsterdam, The Netherlands
Tel.: +31 20 525 3340
E-mail: wester@uva.nl
Liza RUBINSTEIN MALAMUD is a student of the research master social sciences at the University of Amsterdam in the Netherlands. For her master thesis, Liza is studying responsible investment and shareholder engagement in the Netherlands. Liza also works as a group facilitator and contributed to the design of the CrowdFindings course program.
Contact:
Liza Rubinstein Malamud
Amsterdam Institute for Social Science Research (AISSR)
University of Amsterdam
Nieuwe Achtergracht 166
1018WV Amsterdam, The Netherlands
E-mail: lizarubinstein@gmail.com
Lianne SCHMIDT is a student of the research master social sciences at the University of Amsterdam in the Netherlands and student member of the board of the university.
Contact:
Lianne Schmidt
Amsterdam Institute for Social Science Research (AISSR)
University of Amsterdam
Nieuwe Achtergracht 166
1018WV Amsterdam, The Netherlands
E-mail: lianne.schmidt@student.uva.nl
Annemiek STOOPENDAAL, PhD, assistant professor of organizational anthropology in Health Care at the Erasmus University Rotterdam, Department of Health Policy and Management. Her research interests include healthcare management and governance and she uses qualitative, ethnographic and formative research methods.
Contact:
Annemiek Stoopendaal
Dept. of Health Policy and Management
Erasmus University Rotterdam
P.O.Box 1738
3000 DR Rotterdam, The Netherlands
E-mail: stoopendaal@bmg.eur.nl
Nynke KRUIDERINK is team leader ICT in education at the College and Graduate School of Social Sciences at the University of Amsterdam.
Contact:
Nynke Kruiderink
University of Amsterdam
PO Box 15725
1001 NE Amsterdam, The Netherlands
Email n.j.kruiderink@uva.nl
Christina HANSEN, PhD candidate in the research program Migration, Urbanisation and Societal Change (MUSA) at the Department of Global Political Studies, Malmö University. Research interests: political activism, migration, and urban restructuring.
Contact:
Christina Hansen
Malmö University
Faculty of Culture and Society
205 06 Malmö, Sweden
Tel.: 46 40 66 58763
E-mail: christina.hansen@mah.se
Hege SjØLIE, PhD, associate professor at Department of Health Sciences, Oslo and Akershus University College of Applied Sciences, Norway. Research interests: mental health, staff perspective, emotion work.
Contact:
Hege Sjølie
Oslo and Akershus University College of Applied Sciences
Department of Health Sciences
PO Box 4 St Olavs plass
NO-0130 Oslo, Norway
E-mail: Hegesjo@gmail.com
Bröer, Christian; Moerman, Gerben; Wester, Johan Casper; Rubinstein Malamud, Liza; Schmidt, Lianne; Stoopendaal, Annemiek;
Kruiderink, Nynke; Hansen, Christina & Sjølie, Hege (2016). Open Online Research: Developing Software and Method for Collaborative
Interpretation [71 paragraphs]. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 17(3), Art. 2,
http://nbn-resolving.de/urn:nbn:de:0114-fqs160327.

Creative Commons Attribution 4.0 International License