Volume 20, No. 3, Art. 28 – September 2019
Die Beobachter_innenübereinstimmung als Kompass bei der induktiven Kategorienbildung? Erfahrungen einer Forschungsgruppe mit der Auswertung von Interviewtranskripten
Judith Becker, Franziska Moser, Maria Fleßner & Bettina Hannover
Zusammenfassung: Obwohl ein kooperatives Forschungsvorgehen von Vertreter_innen qualitativer Forschung immer wieder eingefordert wird, lässt sich in der einschlägigen Literatur wenig zu dessen konkreter Umsetzung finden. Im vorliegenden Beitrag beschreiben wir unsere Erfahrungen mit der kooperativen Erarbeitung einer zusammenfassenden Inhaltsanalyse und einer induktiven Kategorienbildung. Um den Forschungsprozess fortwährend zu reflektieren und entsprechend anzupassen, erwies sich die wiederholte Berechnung der Beobachter_innenübereinstimmung als guter Kompass. Unsere Erfahrungen führen uns zu einem Plädoyer für die Arbeit in kooperativen Forschungsgruppen, auch wenn sie einen hohen zeitlichen Aufwand sowie ein hohes Maß an Transparenz erfordern. Abschließend geben wir Anregungen, wie Forscher_innen bei der Arbeit mit der qualitativen Inhaltsanalyse durch ein solches Vorgehen profitieren können.
Keywords: Kooperation der Forschenden; qualitative Inhaltsanalyse; zusammenfassende Inhaltsanalyse; induktive Kategorienbildung; Beobachter_innenübereinstimmung
Inhaltsverzeichnis
1. Kooperation im qualitativen Forschungsprozess
2. Induktive Kategorienentwicklung
2.1 Gemeinsames Kategoriensystem
2.2 Konsensuelles Codieren
3. Reflexion und Ableitungen
1. Kooperation im qualitativen Forschungsprozess
Immer wieder wird für die qualitative Forschung gefordert, dass die Arbeit in Gruppen ein "selbstverständlicher Standard" (REICHERTZ 2009, §25) werden solle. Auch bei der Durchführung induktiv ausgerichteter Varianten qualitativer Inhaltsanalyse scheinen kooperative Arbeitsformen angezeigt (JANSSEN, STAMANN, KRUG & NEGELE 2017; STAMANN & JANSSEN 2019; STAMANN, JANSSEN & SCHREIER 2016). Konkrete Beschreibungen derartiger Forschungsprozesse sind jedoch in der einschlägigen Literatur selten (für eine Ausnahme HOPF & SCHMIDT 1993). Mit dem vorliegenden Beitrag verfolgen wir das Ziel, ausgehend von den Erfahrungen, die wir in der eigenen Forschungsgruppe gemacht haben, die Potenziale kooperativen Arbeitens bei der Verwendung der qualitativen Inhaltsanalyse zu beschreiben. In der Forschungsgruppe arbeiteten vier wissenschaftliche Mitarbeiterinnen, drei Kolleg_innen unterstützten den Prozess der Auswertung phasenweise. Unsere Aufgabe im Forschungsprojekt "Der Einfluss musisch-kreativer Projekte auf die schulische Entwicklung von Jugendlichen" bestand in der Evaluation des schulbasierten Tanztrainings "TanzZeit – Zeit für Tanz in Schulen". In diesem unterrichten Tanzdozent_innen mit professioneller Ausbildung wöchentlich im Umfang von zwei Schulstunden zeitgenössischen Tanz an verschiedenen Berliner Schulen. Um die Auswirkungen auf die Beteiligten zu untersuchen, wurden u.a. Interviews mit Klassenlehrkräften, Tanzdozent_innen sowie Schüler_innen geführt. [1]
Im vorliegenden Beitrag schildern wir unsere Erfahrungen mit einer kooperativen Kategorienentwicklung und der Umsetzung des konsensuellen Codierens, die wir bei der Auswertung von elf, auf Interviews mit Klassenlehrkräften beruhenden Transkripten gewonnenen haben. Unter Anwendung zweier Ablaufmodelle nach Philipp MAYRING (2015) wurde zunächst ein Kategoriensystem entwickelt, dessen Anwendbarkeit auf das weitere Material wir mit dem Ansatz des konsensuellen Codierens (HOPF & SCHMIDT 1993) überprüften (Abschnitt 2). Ausgehend von unseren Erfahrungen zeigen wir Problemfelder auf und beschreiben unsere Lösungsansätze. Abschließend geben wir auf der Grundlage unserer Erfahrungen Anregungen zur Zusammensetzung von Forschungsgruppen, auch bzgl. ihrer Offenheit nach innen und außen (Abschnitt 3). [2]
2. Induktive Kategorienentwicklung
Für die Auswertung der transkribierten Leitfadeninterviews (HELFFERICH 2009) bildeten wir in einem kooperativen Prozess induktiv Kategorien unter Verwendung der Ablaufmodelle der zusammenfassenden Inhaltsanalyse und der induktiven Kategorienbildung (MAYRING 2015). Während bei der zusammenfassenden Inhaltsanalyse mit Paraphrasierungen und schrittweisen Reduktionen gearbeitet wird, bleibt die Anwendung der "Makrooperatoren der Reduktion" (S.69) bei der induktiven Kategorienbildung implizit, d.h. wird nicht in Form von Paraphrasierungen, Generalisierungen etc. expliziert. Zudem wird bei der induktiven Kategorienbildung vorab ein Selektionskriterium festgelegt, "[...] das bestimmt, welches Material Ausgangspunkt der Kategoriendefinition sein soll" (S.86), während bei der zusammenfassenden Inhaltsanalyse lediglich eine Abstraktionsebene bestimmt wird. KUCKARTZ (2018) erachtet die vorherige theoriegeleitete Bestimmung des Themas bei der induktiven Kategorienbildung als problematisch, da hiermit ein eher deduktives Vorgehen nahegelegt werde. Auch wir sahen die Gefahr, dass Aspekte, die außerhalb der theoretischen Rahmung liegen, unentdeckt bleiben könnten. Aus diesem Grund nutzten wir die zusammenfassende Inhaltsanalyse als ersten Schritt, um uns – zumindest in diesem Sinne – vorbehaltlos dem Material der ersten zwei Transkripte zu nähern. Im weiteren Verlauf verwendeten wir die daran gemeinsam entwickelten Kategorien als Selektionskriterien für die Auswertung der übrigen neun Transkripte gemäß der induktiven Kategorienbildung. In Abbildung 1 ist unser Forschungsprozess dargestellt.
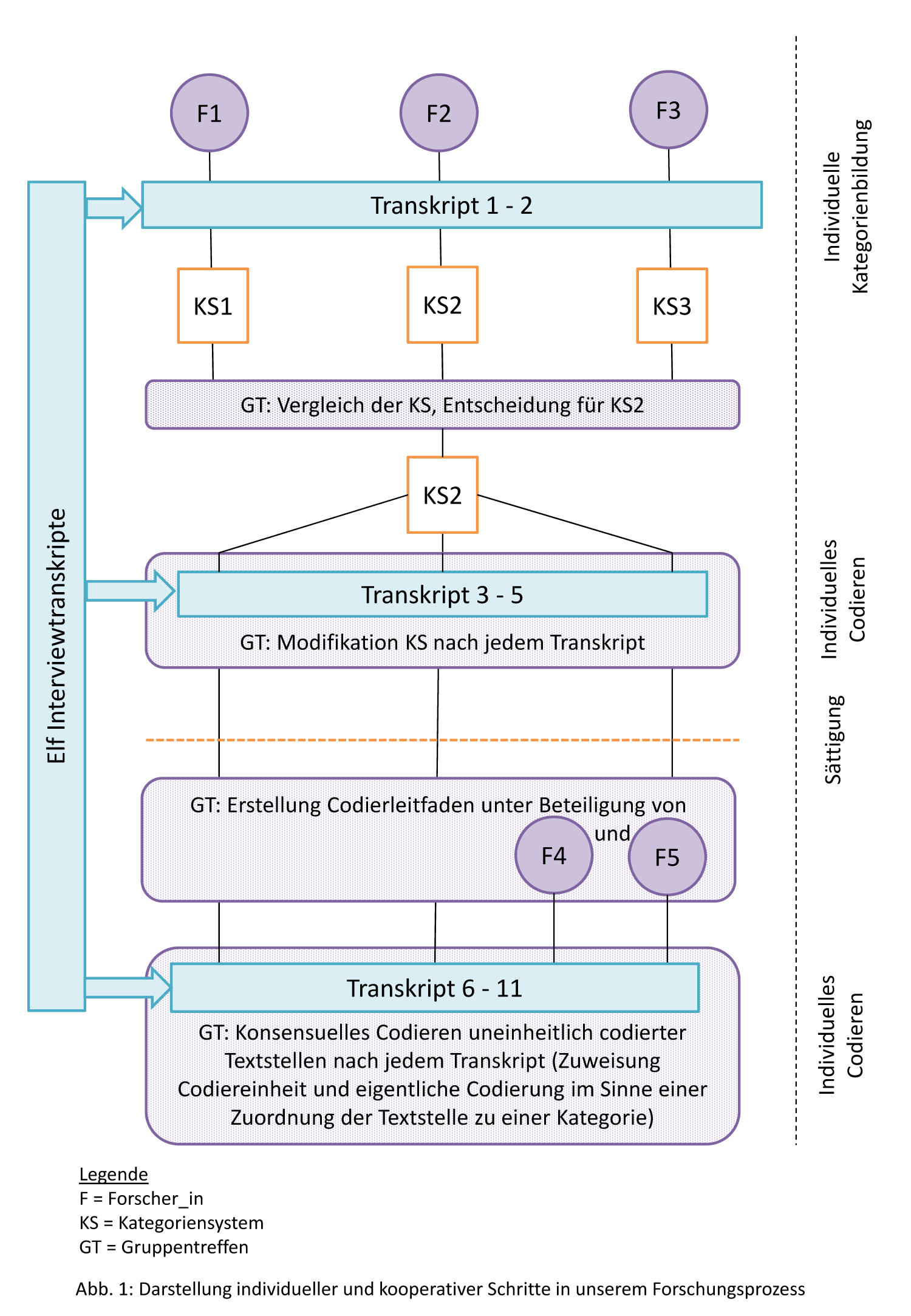
Abbildung 1: Darstellung individueller und kooperativer Schritte in unserem Forschungsprozess. Bitte klicken Sie hier oder auf die Abbildung für eine Vergrößerung. [3]
2.1 Gemeinsames Kategoriensystem
Die sieben Schritte der zusammenfassenden Inhaltsanalyse wurden von drei Mitgliedern der Forschungsgruppe unabhängig voneinander auf zwei Transkripte angewendet. Die Memo-Funktion bei dem von uns verwendeten Auswertungsprogramm MAXQDA erwies sich als überaus nützlich, da einzelne Textstellen separat vom restlichen Transkript bearbeitet werden konnten. So wurden die Antworten der Klassenlehrkräfte in ein Memo1) verschoben, mit einem Titel versehen und dort paraphrasiert. Anschließend wurden die Memos in eine Excel-Liste exportiert (entsprechend dem Demonstrationsbeispiel in MAYRING 2015), um dann die weiteren Schritte der Generalisierung und Reduktion umzusetzen. Nachdem jedes Mitglied der Forschungsgruppe die Aussagen zu einem Kategoriensystem zusammengestellt hatte, wurde deutlich, dass wir bereits bei den Paraphrasierungen unterschiedlich vorgegangen waren. Ein Mitglied wählte ein kleinschrittiges Vorgehen und paraphrasierte satzweise. Für jeden neuen inhaltlichen Aspekt legte es ein neues Memo mit eigenem Titel an. Die Paraphrasierungen der anderen Mitglieder waren deutlich abstrakter. In Abbildung 2 zeigen wir die unterschiedlichen Vorgehensweisen.
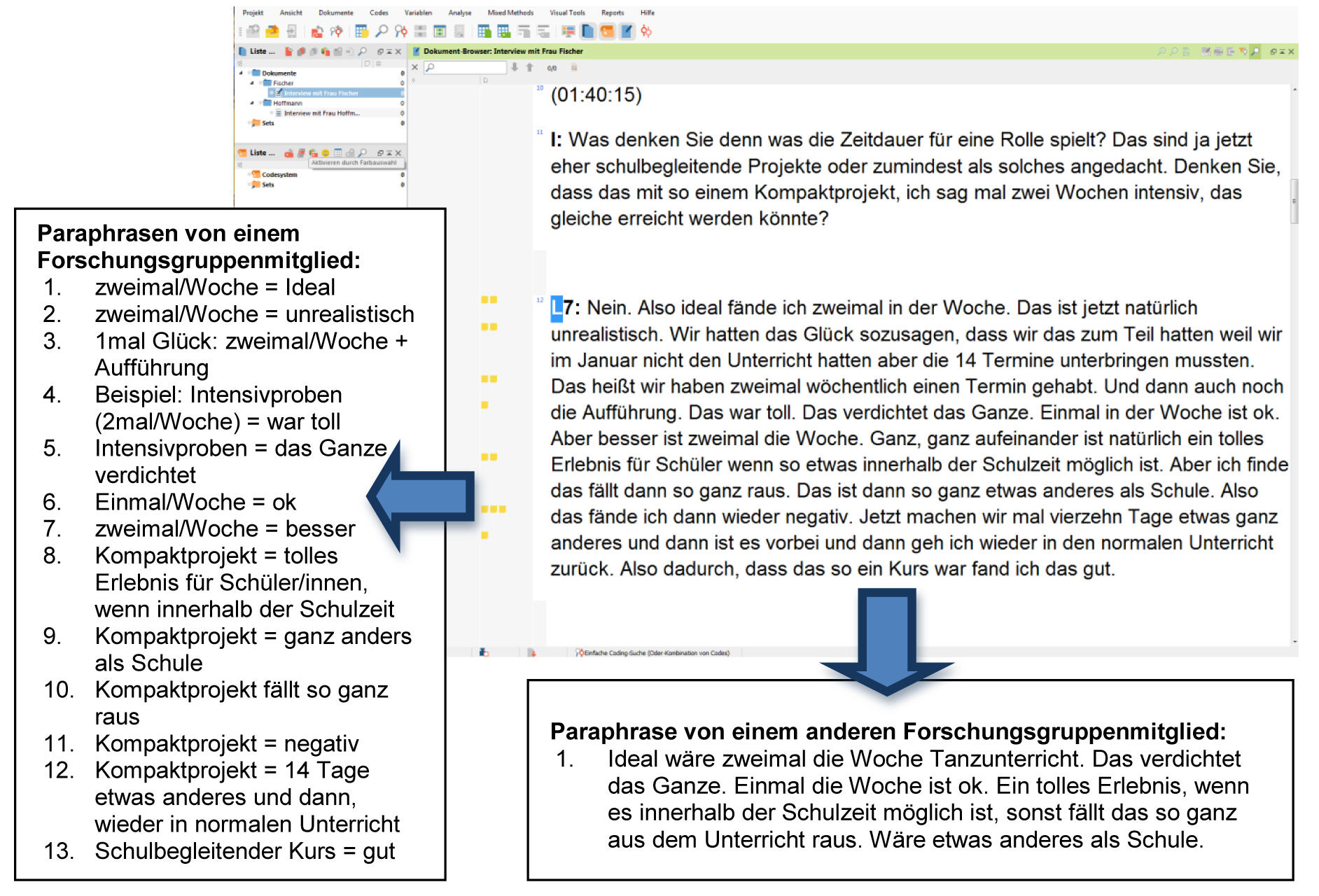
Abbildung 2: Darstellung der Paraphrasierungen zweier Forschungsgruppenmitglieder zu einem Absatz aus einem der ersten zwei
Transkripte. Bitte klicken Sie hier oder auf die Abbildung für eine Vergrößerung. [4]
So wurde z.B. die Aussage einer Lehrkraft zu einer einzelnen Paraphrase zusammengefasst, während aus der gleichen Aussage mit dem kleinschrittigen Vorgehen 13 Paraphrasen gebildet wurden. Ein solch unterschiedlicher Differenzierungsgrad zeigte sich auch bei den weiteren Schritten der Reduktion und Generalisierung, sodass schließlich drei sehr verschiedene Kategoriensysteme entwickelt wurden. Um dafür Sorge zu tragen, dass uns möglichst keine wichtigen Aspekte verloren gehen würden, entschieden wir uns für das detaillierteste und umfassendste Kategoriensystem. [5]
Dieses gemeinsame Kategoriensystem wurde im weiteren Verlauf der Auswertung fortwährend ergänzt und erweitert. Um die Entwicklung des Kategoriensystems für alle transparent zu gestalten, wurden Veränderungen nur bei den Gruppentreffen vorgenommen. Dafür haben wir die folgende Regel aufgestellt: Wenn die Zuordnung einer Aussage zu einer bestehenden Unterkategorie als nicht passend erscheint, wird diese Aussage vorübergehend in die jeweilige Hauptkategorie (mit der selbst nicht codiert wurde) verschoben (SCHREIER 2012). Stellte sich beim Gruppentreffen heraus, dass als relevant erachtete Aussagen im Kategoriensystem unberücksichtigt geblieben waren, wurden diese als Unterkategorie aufgenommen. Zudem wurden Doppelcodierungen besprochen und zusätzliche Abgrenzungskriterien für die jeweils betroffenen Kategorien festgelegt. [6]
Nachdem es ab dem fünften Transkript keine weiteren Ergänzungen zum Kategioriensystem gab, erstellten wir einen Codierleitfaden, bestehend aus Kategorienbeschreibungen und Ankerbeispielen. Zuvor hatten wir uns dafür entschieden, den Ablauf der Auswertung zu verändern, da das Kategoriensystem zu groß und zu unübersichtlich geworden war. Anstatt den gesamten Fragenkomplex mit einem Mal auszuwerten, legten wir den Fokus auf die Beantwortung einer Frage. Außerdem wurde der Codierleitfaden mit zwei nicht an der Entwicklung des Kategoriensystems beteiligten Kolleg_innen besprochen und auf diese Weise auf seine Anwendbarkeit außerhalb der Forschungsgruppe geprüft. [7]
Basierend auf dem gemeinsamen Kategoriensystem wurden die anderen neun Transkripte von jeweils drei Mitgliedern der Forschungsgruppe unabhängig voneinander codiert. Um den Codierprozess nicht mehrmals durchlaufen zu müssen, umfasste das Codieren sowohl das Bilden von inhaltlichen Codiereinheiten als auch das daran anschließende Zuweisen dieser Einheiten zu einzelnen Kategorien. Das Bilden von formalen Codiereinheiten, in denen z.B. jeder Satz eine Einheit bildet, stellte für uns keine Option dar (siehe für Ausführungen zur Segmentierung SCHREIER 2012), da durch dieses Vorgehen Inhalte aus ihrem Zusammenhang gerissen worden wären. Beim Festlegen der zu codierenden Textstellen gab es große Unterschiede zwischen den Codierer_innen, sodass wir das Bilden der Einheiten wiederholt üben mussten. Grundsätzlich sollte möglichst großflächig codiert werden, damit codierte Passagen auch aus dem Transkript herausgelöst verständlich waren (KUCKARTZ 2018). Für den Vergleich der verschiedenen Dateien nutzten wir in MAXQDA die Teamwork-Funktion in Verbindung mit der Analysefunktion zur Prüfung der prozentualen Intercoder-Übereinstimmung (MAXQDA 2011). Fälle, bei denen der empfohlene Übereinstimmungsgrad von mindestens 90% (NEUENDORF 2002) nicht erreicht wurde, besprachen wir während der Gruppentreffen, die nach der Codierung eines jeden Transkripts stattfanden. Wir strebten bei den Codierungen konsensuelle Entscheidungen nach HOPF und SCHMIDT (1993) an, wonach die Transkripte zunächst unabhängig voneinander codiert und die Codierungen anschließend in gemeinsamen Treffen miteinander verglichen und diskrepante Einschätzungen diskutiert wurden. Mit diesem Vorgehen verbanden wir die Hoffnung, dass durch den "[...] kommunikative[n] Prozess der Zuordnung [...] ein sensitive[r] Umgang mit dem Material und eine fortlaufende Anpassung und Ausdifferenzierung der Kategorien [...]" (SCHMIDT 2010, S.480) unterstützt werden würde. [8]
Wurde dieselbe Aussage unterschiedlich codiert, entschieden wir uns konsensuell für die Vergabe einer Kategorie (SCHREIER 2012). War dies nicht möglich, wurde die Aussage zunächst einer Hauptkategorie zugeordnet und solange darin belassen, bis wir nach etwas zeitlichem Abstand und/oder nach der Hinzunahme neuer Informationen (z.B. eines weiteren Transkripts) entweder eine neue Unterkategorie für diese Aussage bildeten oder die Aussage in eine bereits bestehende Unterkategorie aufnahmen. Zudem stellte der Abgleich der Codierungen eine Fehlerkontrolle dar, wenn eine als relevant angesehene Aussage z.B. von einer Codiererin übersehen worden war (SCHREIER 2012). [9]
Im weiteren Verlauf zeigte sich, dass die Entscheidungen für einzelne Codierungen teilweise zu vorschnell getroffen worden waren. Daher entschieden wir uns dafür, das ausgedruckte Transkript zunächst in Ruhe und ohne das Kategoriensystem zu lesen, es anschließend zu codieren und danach die Codierungen in der MAXQDA-Datei zu überprüfen (KUCKARTZ 2018). Auf diese Weise wurde der Codierprozess bewusster gestaltet. Nach Abschluss der Auswertung wurden Teile des Materials externen Personen vorgelegt und basierend auf deren Kategorienzuweisungen die Beobachter_innenübereinstimmung berechnet, was mit Werten für Cohens Kappa zwischen .823 und .910 zu sehr guten Ergebnissen führte (MAYRING 2000). [10]
Mit unserem kooperativen Vorgehen während des gesamten Forschungsprozesses sind wir von üblichen Arbeitsweisen abgewichen, bei denen Kategoriensysteme zumeist von einer Person entwickelt und andere Personen nur zu bestimmten Phasen der Auswertung hinzugezogen werden (SCHREIER 2012). Die kooperative Auswertung in der Forschungsgruppe und die mehrmalige Durchsicht des Materials führten unserer Ansicht nach zu nachvollziehbareren Ergebnissen, was sich u.a. in den sehr guten Übereinstimmungswerten mit Personen, die nicht an der Entwicklung des Kategoriensystems beteiligt waren, widerspiegelte. Der zeitliche Aufwand für diese kooperative Forschungsarbeit war von uns allerdings deutlich unterschätzt worden. Als besonders zeitintensiv erwies sich, alle Forschungsgruppenmitglieder stets auf dem gleichen Stand zu halten und immer wieder eine gemeinsame Sichtweise bzgl. der Kategorien herzustellen, um zu verhindern, dass sich individuelle Erklärungsmuster durchsetzten. [11]
Vor dem Hintergrund der geschilderten Erfahrungen lassen sich für andere Forscher_innen Hinweise ableiten, wie sie bei einer Auswertung mit der induktiven Kategorienentwicklung von einem kooperativen Vorgehen profitieren können. Als ersten Schritt der Annäherung an das Material hat sich für uns das Ablaufmodell der zusammenfassenden Inhaltsanalyse bewährt, auch wenn dies zeitlich aufwändiger ist als im Falle der induktiven Kategorienbildung. Des Weiteren haben wir es als sinnvoll wahrgenommen, von Beginn an eine große Bandbreite von Sichtweisen zu erzeugen und im Diskussionsprozess zu berücksichtigen. Bei der Gegenüberstellung der drei mit der zusammenfassenden Inhaltsanalyse gebildeten Kategoriensysteme ergaben sich zwar sehr unterschiedliche Einschätzungen; diese Vielfalt in den Wahrnehmungen stellte sich im weiteren Diskussionsprozess jedoch als großer Gewinn heraus. So waren wir ganz bewusst nicht der Empfehlung von HOPF und SCHMIDT (1993) gefolgt, wonach Personen, die das Interview führen, nicht zum Codierteam gehören sollten, um ein gleiches Vorwissen und eine gewisse "Chancengleichheit" zwischen den Codierer_innen zu gewährleisten. Für uns erwiesen sich die unterschiedlichen Erfahrungshintergründe der einzelnen Gruppenmitglieder als fruchtbar. So gab es immer wieder Situationen, in denen durch eine andere Deutung einer Person bereits getroffene Kategorisierungen nochmals infrage gestellt wurden und die neu gefundene Lösung schlussendlich von allen als überzeugender gewertet wurde. [12]
Wir haben zudem gute Erfahrungen damit gemacht, dass bei den Besprechungen der Codierungen neben den Codierer_innen auch weitere Personen aus der Forschungsgruppe anwesend sind. Dank ihrer Erfahrung u.a. mit der Auswertung anderer Transkripte aus dem Forschungsprojekt und ihrer kritischen Nachfragen, zu denen sich die Codierer_innen positionieren mussten, konnten Entscheidungen nochmals geändert oder aber mit mehr Klarheit in der Begründung beibehalten werden. Auch empfiehlt sich unserer Ansicht nach die Etablierung von festen Gruppentreffen, anstatt sie erst bei Bedarf einzuberufen. Damit erfährt der Austausch über voneinander abweichende Wahrnehmungen eine höhere Verbindlichkeit als dies z.B. bei HOPF und SCHMIDT der Fall gewesen ist, wo die Möglichkeit, bei Unstimmigkeiten eine weitere Person hinzuziehen, zwar vorgesehen war, aber in keinem Fall wahrgenommen wurde. Eine positive Wirkung hatte für uns auch die Öffnung der Forschungsgruppe nach außen, also der Einbezug von Personen, die nicht zu unserer Forschungsgruppe gehörten. So tauschten wir uns mit anderen Forscher_innen im Rahmen von externen Kolloquien und Workshops aus. Auch wurden wir zu einem späteren Zeitpunkt, zu dem zwei weitere Kolleg_innen in das Projekt eingestellt wurden, im Forschungsprozess von mancher "falschen Spur" (SCHMIDT 2010, S.481) abgebracht. [13]
Neben diesen positiven Erfahrungen gab es jedoch auch Schwierigkeiten, z.B. war der Koordinierungsaufwand ausgesprochen hoch. Im Nachhinein können wir die gemeinsame Entwicklung eines größeren Kategoriensystems daher nicht empfehlen. Wir hatten die kooperative Arbeit mit der Annahme begonnen, dass viele Personen viel Material auswerten könnten, was sich in unserem Fall jedoch als Irrtum herausstellte. Vielmehr hatten wir den Eindruck, dass die Diskussionen zu weitläufig geführt wurden. Um in der Gruppe handlungs- und diskussionsfähig zu bleiben, haben wir dann auf die gemeinsame Bearbeitung kleinerer Ausschnitte gesetzt. Aus zeitökonomischen Gründen wäre es auch denkbar, Teile der Auswertung von vornherein an unterschiedliche Gruppenmitglieder zu vergeben, die hierfür maßgeblich verantwortlich sind. Allerdings sollte es in diesem Fall feste Besprechungstermine während der Entwicklung geben, zu denen sich die gesamte Forschungsgruppe den bisherigen Stand mit direktem Bezug auf das Material zeigen lässt. [14]
Für uns war eine mehrfache Übereinstimmungsberechnung in MAXQDA wichtig. Diese Möglichkeit erleichterte uns den Vergleich sowohl zwischen den codierten Textstellen als auch den jeweils von verschiedenen Personen zugewiesenen Codierungen. Hiermit und mit der Berechnung von Cohens Kappa zum Ende der Auswertung konnten wir absichern, dass das entwickelte Kategoriensystem das Material weiterhin repräsentiert und Gruppenmitglieder sowie andere Personen zu ähnlichen Ergebnissen kommen. Auch wenn bei der Bewertung der Höhe der Beobachter_innenübereinstimmung der jeweilige Kontext berücksichtigt werden sollte (SCHREIER 2012) und auch auf "weichere" Vorgehensweisen zurückgegriffen werden kann (GLÄSER-ZIKUDA 2008), stellt die Berechnung der Beobachter_innenübereinstimmung für uns ein wichtiges externes Kriterium dar, um zu entscheiden, wie in den folgenden Phasen des Forschungsprozesses weitergearbeitet werden sollte. [15]
Von Anfang an legten wir viel Wert auf das Dokumentieren der Gruppentreffen, um die Übersicht nicht zu verlieren und den Forschungsprozess transparent abzubilden. So führten wir bei den Gruppentreffen stetig ein Forschungsprotokoll, in dem die Entscheidungen bezüglich der diskutierten Materialpassagen festgehalten wurden. Die Aufgabe des Protokollierens wurde im wechselnden Turnus vergeben und das Protokoll anschließend für alle zugänglich abgespeichert. Zudem wurde für eine größere Übersichtlichkeit das gemeinsame Kategoriensystem auf einem Wandplakat abgebildet, um mögliche Dopplungen und Uneinheitlichkeiten besser erkennen zu können. Im weiteren Verlauf erwiesen sich Wandplakat und Forschungsprotokoll jedoch als zunehmend unübersichtlich. Um sowohl die konkrete Entwicklung der einzelnen Kategorien darzustellen als auch Beschreibungen zu den Kategorien als Memos in das Auswertungsprogramm übertragen zu können, wurde stattdessen eine Excel-Datei angelegt, in der das gemeinsame Kategoriensystem enthalten war. Veränderungen am Kategoriensystem wurden dort fortlaufend eingetragen. Ein späteres Nachvollziehen z.B. der Entstehung und Veränderung einer Kategorie konnte so gewährleistet werden. Neben den verschiedenen Darstellungsoptionen wurde durch das Schreiben des Codierleitfadens die Bildung einer gemeinsamen Basis forciert und die Nachvollziehbarkeit der Kategorien gewährleistet. [16]
Zusammenfassend stellen wir fest, dass eine kooperative Erarbeitung einer induktiven Kategorienentwicklung zwar kein einfacher Weg ist, jedoch für uns zu zufriedenstellenden Ergebnissen führte, u.a. weil diese auch für andere Personen nachvollziehbar waren. Wir möchten andere Forscher_innen ermuntern, bei der Planung ihres Vorgehens kooperative Formen der Auswertung in Betracht zu ziehen und die Scientific Community über entsprechende Publikationen an der Reflexion ihrer praktischen Erfahrungen teilhaben zu lassen. Diese Erfahrungsberichte könnten die Forschungspraxis weiter bereichern, indem Fragen, Potenziale, aber auch Grenzen zur Diskussion gestellt werden. [17]
Unser Dank gilt Josephine WILS, Hagen TROSCHKE und Matthias J. BECKER für ihre Mitarbeit in unserem Forschungsprojekt. Zudem danken wir herzlich den beiden Gutachter_innen für ihre Hinweise und im Besonderen Christoph STAMANN für seine Anmerkungen, die uns halfen, den Beitrag zu verbessern.
1) Bei Memos handelt es sich um "[...] die von den Forschenden während des Analyseprozesses festgehaltenen Gedanken, Ideen, Vermutungen und Hypothesen. Es kann sich bei Memos sowohl um kurze Notizen handeln (ähnlich wie Post-its, die man an eine Buchseite heftet) als auch um reflektierte inhaltliche Vermerke, die wichtige Bausteine auf dem Weg zum Forschungsbericht darstellen können" (KUCKARTZ 2018, S.58). <zurück>
Gläser-Zikuda, Michaela (2008). Qualitative Inhaltsanalyse in der Lernstrategie- und Lernemotionsforschung. In Philipp Mayring & Michaela Gläser-Zikuda (Hrsg.), Die Praxis der Qualitativen Inhaltsanalyse (S.63-83). Weinheim: Beltz.
Helfferich, Cornelia (2009). Die Qualität qualitativer Daten. Manual für die Durchführung qualitativer Interviews (3., überarb. Aufl.). Wiesbaden: VS Verlag für Sozialwissenschaften.
Hopf, Christel & Schmidt, Christiane (Hrsg.) (1993). Zum Verhältnis von innerfamilialen sozialen Erfahrungen, Persönlichkeitsentwicklung und politischen Orientierungen: Dokumentation und Erörterung des methodischen Vorgehens in einer Studie zu diesem Thema, https://nbn-resolving.org/urn:nbn:de:0168-ssoar-456148 [Zugriff: 16. April 2019].
Janssen, Markus; Stamann, Christoph; Krug, Yvonne & Negele, Christina (2017). Tagungsbericht: Qualitative Inhaltsanalyse – and beyond? Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 18(2), Art. 7, http://dx.doi.org/10.17169/fqs-18.2.2812 [Zugriff: 24. Januar 2018].
Kuckartz, Udo (2018). Qualitative Inhaltsanalyse. Methoden, Praxis, Computerunterstützung (4. Aufl.). Weinheim: Beltz Juventa.
MAXQDA (2011). Referenzhandbuch zum Textanalysesystem MAX QualitativeDatenAnalyse 10. Marburg: VERBI Software, https://www.maxqda.de/download/manuals/MAX10_manual_ger.pdf [Zugriff: 27. August 2019].
Mayring, Philipp (2000). Qualitative Inhaltsanalyse. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 1(2), Art. 20, https://doi.org/10.17169/fqs-1.2.1089 [Zugriff: 27. August 2019].
Mayring, Philipp (2015). Qualitative Inhaltsanalyse. Grundlagen und Techniken (12., überarb. Aufl.). Weinheim: Beltz.
Neuendorf, Kimberly A. (2002). The content analysis guidebook. Thousand Oaks, CA: Sage.
Reichertz, Jo (2009). Die Konjunktur der qualitativen Sozialforschung und Konjunkturen innerhalb der qualitativen Sozialforschung. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 10(3), Art. 29, http://dx.doi.org/10.17169/fqs-10.3.1382 [Zugriff: 9. August 2012].
Schmidt, Christiane (2010). Auswertungstechniken für Leitfadeninterviews. In Barbara Friebertshäuser; Antje Langer & Annedore Prengel (Hrsg.), Handbuch Qualitative Forschungsmethoden in der Erziehungswissenschaft (S.473-486). Weinheim: Juventa.
Schreier, Margrit (2012). Qualitative content analysis in practice. London: Sage.
Stamann, Christoph & Janssen, Markus (2019). Die Herstellung von Arbeitsfähigkeit als zentrale Herausforderung für das Gelingen einer gemeinsamen Praxis – Erfahrungen aus einer qualitativ inhaltsanalytischen Forschungswerkstatt und Ableitungen für die Gestaltung von Forschungswerkstattsitzungen. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 20(3), Art. 21, http://dx.doi.org/10.17169/fqs-20.3.3379.
Stamann, Christoph; Janssen, Markus & Schreier, Margit (2016). Qualitative Inhaltsanalyse ‒ Versuch einer Begriffsbestimmung und Systematisierung. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 17(3), Art. 16, http://dx.doi.org/10.17169/fqs-17.3.2581 [Zugriff: 17. März 2017].
Judith BECKER ist Diplom-Psychologin und arbeitet als Beraterin in der Beschwerde- und Informationsstelle Psychiatrie in Berlin. Sie war wissenschaftliche Mitarbeiterin in dem Forschungsprojekt "Der Einfluss musisch-kreativer Projekte auf die schulische Entwicklung von Jugendlichen" an der Freien Universität Berlin. Forschungsschwerpunkt: schulischer Tanzunterricht unter Anwendung qualitativer Forschungsmethoden.
Kontakt:
Judith Becker
Arbeitsbereich Schul- und Unterrichtsforschung
Fachbereich Erziehungswissenschaft und Psychologie
Freie Universität Berlin
Habelschwerdter Allee 45
14195 Berlin
E-Mail: judith.becker@fu-berlin.de
Franziska MOSER ist wissenschaftliche Mitarbeiterin am Institut für Psychologie an der Universität Bern und beim Bundesamt für Statistik. Im Rahmen des Initial Training Network "Language, Cognition, and Gender" promovierte sie 2013 an der Freien Universität Berlin. Forschungsschwerpunkte sind Geschlechterrollen und -stereotype, geschlechtergerechte Sprache sowie die Entwicklung der Geschlechtsidentität.
Kontakt:
Franziska Moser
Institut für Psychologie
Universität Bern
Fabrikstrasse 8
CH-3012 Bern
Tel.: +41 31 6313981
E-Mail: franziska.moser@psy.unibe.ch
URL: https://www.researchgate.net/profile/Franziska_Moser
Maria FLEẞNER ist als wissenschaftliche Mitarbeiterin an der Fakultät IV für Elektrotechnik und Informatik der Technischen Universität Berlin im Erstsemestermentoring tätig. Ihre Forschungsschwerpunkte liegen in den Bereichen Student-Life-Cycle, Gender in IT sowie videografischer Unterrichtsanalyse.
Kontakt:
Maria Fleßner
Fakultät IV Elektrotechnik und Informatik
Fakultätsverwaltung
Mentoring Fakultät IV, Sekr. MAR 6-1
Technische Universität Berlin
Marchstraße 23
10587 Berlin
Tel.: +49 30 314 73194
E-Mail: maria.flessner-jung@tu-berlin.de
URL: https://www.eecs.tu-berlin.de/menue/studium_und_lehre/beratung_und_service/mentoringeecs/
Bettina HANNOVER ist Diplompsychologin und Professorin an der Freien Universität Berlin, wo sie den Arbeitsbereich Schul- und Unterrichtsforschung leitet. Sie hat das Projekt "Der Einfluss musisch-kreativer Projekte auf die schulische Entwicklung von Jugendlichen" beim Bundesministerium für Bildung und Forschung eingeworben und wissenschaftlich verantwortet. In ihrer Forschung fragt sie, wie das Selbst – das Bild, das Menschen von der eigenen Person haben – ihr Denken, Fühlen und Handeln beeinflusst. Dazu untersucht sie die kognitiven Mechanismen, die der Verarbeitung selbstbezogener Informationen zugrunde liegen, sowie soziale oder kulturelle Einflussfaktoren. Ganz besonders spielen die Auswirkungen des Selbst auf Lernen und Interessensentwicklung im Kontext Schule in ihrer Forschung eine Rolle. Sie war langjähriges Mitglied des Fachkollegiums Psychologie der Deutschen Forschungsgemeinschaft und der Hauptjury für die Vergabe des Deutschen Schulpreises.
Kontakt:
Bettina Hannover
Arbeitsbereich Schul- und Unterrichtsforschung
Fachbereich Erziehungswissenschaft und Psychologie
Freie Universität Berlin
Habelschwerdter Allee 45
14195 Berlin
Tel.: +49 30 8385 69 50
E-Mail: bettina.hannover@fu-berlin.de
URL: https://www.ewi-psy.fu-berlin.de/einrichtungen/arbeitsbereiche/ewi-psy/mitarbeiter_innen/Aktuelles-Team/Hannover_B/index.html
Becker, Judith; Moser, Franziska; Fleßner, Maria & Hannover, Bettina (2019). Die Beobachter_innenübereinstimmung als Kompass bei der induktiven Kategorienbildung? Erfahrungen einer Forschungsgruppe mit der Auswertung von Interviewtranskripten [17 Absätze]. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 20(3), Art. 28, http://dx.doi.org/10.17169/fqs-20.3.3383.

Creative Commons Attribution 4.0 International License