Volume 20, No. 3, Art. 29 – September 2019
The Discovery of Causal Mechanisms: Extractive Qualitative Content Analysis as a Tool for Process Tracing
Jochen Gläser & Grit Laudel
Abstract: With this article, we seek to contribute to the methodological discussion about the fit of qualitative methods for specific purposes by examining the role that extractive qualitative content analysis (EQCA) can play in the discovery of causal mechanisms. The methodological literature on the empirical identification of causal mechanisms (an approach called process tracing) has been dominated by the idea of empirically testing the presence of hypothesized mechanisms. We argue for the discovery of causal mechanisms on the basis of causal reconstruction as suggested by MAYNTZ (2009 [2002], 2016). We establish EQCA as a distinct qualitative method and specify its outcome—namely, a structured information base that can be used for the reconstruction of social situations and processes. Such an information base is an important source for causal analysis. We demonstrate the role of EQCA in process tracing with an empirical study by LAUDEL and BIELICK (2018), who discovered the mechanisms that produce individual research programs of early career researchers.
Key words: qualitative content analysis; causal mechanism; process tracing; case studies; structured focused comparison; comparative methodology
Table of Contents
1. Introduction
2. A New Task for Qualitative Research: The Discovery of Causal Mechanisms
3. Positioning Extractive Qualitative Content Analysis in Qualitative Research
4. Discovering Causal Mechanisms with Extractive Qualitative Content Analysis—An Example
4.1 Theoretical background and categories for extractive qualitative content analysis
4.2 Constructing categories
4.3 Extracting information from interview transcripts and processing the extracted data
4.4 Causal analysis
5. Discussion
6. Conclusions
Appendix: Extraction of relevant information with EQCA
With this article we seek to answer the question of how the discovery of causal mechanisms can be supported by the specific version of qualitative content analysis we have developed (GLÄSER & LAUDEL, 2010, 2013). This question can be positioned at the intersection of two methodological problems. The first problem is the reluctance of qualitative methodology to specify methods supporting causal analysis. Although the search for causal explanations has been previously acknowledged as a possible aim of qualitative research (CRESWELL, 2013; HAMMERSLEY & COOPER, 2012; MAXWELL, 2013; MILES, HUBERMAN & SALDAÑA, 2014; PATTON, 2014; ZNANIECKI, 1934), it remains to be shown how the application of qualitative methods of data collection and analysis can lead to the discovery of causal mechanisms. The few qualitative approaches available for establishing causality remain focused on causal relationships between variables. Even MILES et al. (2014), who explicitly included the discovery of causal mechanisms as an aim of qualitative research, focused on relationships between variables and had little to say about mechanisms. [1]
The second methodological problem is the reluctance of proponents of mechanismic explanations to engage with empirical methods. Over the last two decades, scholars have argued that better explanations of social phenomena could be achieved if the causal mechanisms producing these phenomena were to be provided. Although this argument has triggered many philosophical and methodological discussions, scant attention has been paid to the empirical methods required for that purpose. The discussion is focused on the use of empirical data to test hypotheses about the existence of mechanisms, and proponents of the mechanismic approach appear to regard the collection and analysis of empirical data as unproblematic (BENNETT & CHECKEL, 2015a; BENNETT & GEORGE, 2005). [2]
We address these problems by demonstrating how our version of qualitative content analysis (GLÄSER & LAUDEL, 2010, 2013) can contribute to the discovery of causal mechanisms. As a first step, we argue that an important and thus far undervalued strength of qualitative research is its ability to discover causal mechanisms. Then, as a second step, we present our version of qualitative content analysis as a distinct method that covers the initial phase of data analysis and which is unique in that it uses categories to extract information from texts rather than describing it. Our discussion of the strengths and weaknesses of this method leads to the conclusion that it can support causal analysis. In a third step, we demonstrate how this can be done as well as what role qualitative content analysis can play in the process of discovering causal mechanisms. [3]
2. A New Task for Qualitative Research: The Discovery of Causal Mechanisms
In the last three decades there has been a resurgence of interest in causal mechanisms as a means of explanation in social science. We define a causal mechanism as a sequence of causally linked events that occur repeatedly in reality if certain conditions are given and which link specified initial conditions to a specific outcome. This definition is adopted from MAYNTZ (2004, p.241), and is consistent with work from BOUDON (1976, 1979), ELSTER (1989) and MERTON (1957), and probably several others.1) MERTON's description of the self-fulfilling prophecy illustrates the understanding of causal mechanisms applied in this article. He gives the example of a cycle that starts with a rumor about a bank being in financial trouble. Whether the rumor has some truth to it or not does not matter; it still affects the behavior of some depositors, who subsequently withdraw their money. This may or may not create actual liquidity problems. More importantly, however, it signals to others that something may be wrong with the bank, thereby reinforcing the rumor. This makes even more people withdraw their money. Via this mechanism, even a financially healthy bank may be driven into bankruptcy (MERTON, 1968). This cycle of events—belief formation, acting on that belief, creating the situation that was believed to be true—is a very general and powerful mechanism. We can also observe some of the conditions that trigger and maintain it: the initial definition of the situation must be public, communicable, and strong enough to lead to the actions through which the mechanism operates. Furthermore, these actions must affirm the initial definition of the situation (GLÄSER & LAUDEL, 2013, §11). [4]
The renewed interest in causal mechanisms emerged from two related considerations, namely an increasing degree of uneasiness with the way quantitative social research explains social phenomena, and the question of what constitutes a satisfying explanation in the social sciences. On the most fundamental level, POPPER's hypothetico-deductive model and HEMPEL's covering-law model of explanation, which have been treated as the gold standards of scientific explanation for a long time, have since been suggested to be too narrow. Critics have pointed out that these are rarely applicable, even in the sciences (GORSKI, 2004). Correlational analysis has also been found to provide insufficient support for the integration of diverse findings into a coherent theoretical framework (SØRENSEN, 1998) and to black-box the processes producing the observed effects (MAHONEY, 2001; MAYNTZ, 2004; STEEL, 2004). This is why many scholars consider identifying causal mechanisms as a way of improving explanations of social phenomena. The argument for using causal mechanisms in explanations is rooted in the following understanding: "To explain something, then, is to represent, and thereby render more readily comprehensible, the principal process which produced it" (GORSKI, 2004, p.17, emphasis added). This argument appears to be widely accepted by those who support the use of causal mechanisms in explanations (GRESHOFF, 2015; HEDSTRÖM & YLIKOSKI, 2010; MAYNTZ, 2004). [5]
While the argument that an adequate explanation of a social phenomenon requires the identification of a mechanism is becoming increasingly popular, we are still lacking a strategy for generating the empirical data conducive to the discovery of these mechanisms. The only exception is a suggestion in the political science literature that "process tracing" is an analytical strategy that leads to the empirical identification of mechanisms. Process tracing was proposed as an inductive strategy that overcomes the weaknesses of applying the large-N logic of inferring causation from covariation to small-N case studies (GEORGE & McKEOWN, 1985; MAHONEY, 2000). It was initially described as a procedure that is "intended to investigate and explain the decision process by which various initial conditions are translated into outcomes. A process-tracing approach entails abandonment of the strategy of 'black-boxing' the decision process; instead, this decision-making process is the center of investigation" (GEORGE & McKEOWN, 1985, p.35). This approach has been used for excluding variables from explanations and for disproving hypotheses (MAHONEY, 2000, pp.413-414). The recent surge of interest in causal mechanisms has led to the suggestion that process tracing also supports the identification of causal mechanisms (p.412, p.414). [6]
Unfortunately, little progress has been made since the original proposal. To begin with, there is little agreement on the meaning of "process tracing." In a recent review, TRAMPUSCH and PALIER (2016, p.438) counted 18 definitions and 18 types of process tracing. The authors observed
"... a confused state of affairs [...] The main reason is that most of this literature is mainly methodologically oriented, and discusses very abstract notions and philosophical assumptions, including different methodologies of process tracing such as Bayesian process tracing, set theoretic process tracing or process tracing with directed acyclic graphs ... Although some of these new contributions are potentially important, many of them become more and more distanced from real research." [7]
In the literature reviewed by TRAMPUSCH and PALIER, almost no attention has been paid to empirical methods that could lead to the discovery of causal mechanisms. Only a few scholars have considered the possibility of a mechanism not being known before process tracing begins, and none of them have discussed empirical methods that support the discovery of mechanisms (as illustrated by BENNETT & CHECKEL, 2015a). Instead, the bulk of the literature is focused on developing and testing hypotheses about the existence of mechanisms (BEACH, 2017; BENNETT & CHECKEL, 2015b; GOLDTHORPE, 2001). This is clearly expressed in the following definition of process tracing:
"In process tracing, the researcher examines histories, archival documents, interview transcripts, and other sources to see whether the causal process a theory hypothesizes or implies in a case is in fact evident in the sequences and values of the intervening variables in that case" (BENNETT & GEORGE, 2005, p.6). [8]
The Bayesian approach to process tracing is based on a similar understanding:
"The collection of empirical observations is not a random, ad hoc process but should instead be steered by theory, focusing on testing whether the predicted evidence for a hypothesized part of a mechanism is present in the empirical record. In process-tracing, we deliberately search for observations that allow us to infer whether the hypothesized part of a causal mechanism was present" (BEACH & PEDERSEN, 2013, p.123). [9]
The search for causal mechanisms proposed by these scholars is astonishingly similar to the hypothesis testing of quantitative research that they want to overcome. The main difference appears to be that instead of statistically testing hypotheses about causal relationships between variables, process tracing is supposed to qualitatively test hypotheses about the presence of causal mechanisms. [10]
This predominantly deductive approach to process tracing is complemented by a less prominent approach that can be traced back to GEORGE and McKEOWN (1985) and MAHONEY (2000). This inductive approach, which indeed supports the discovery of causal mechanisms from data, can be described as causal reconstruction (MAYNTZ, 2009 [2002], 2016). Causal reconstruction means explaining a phenomenon by identifying the processes and interactions that made it appear (see also the sections "Explaining-Outcome Process-Tracing" in BEACH & PEDERSEN, 2013, pp.18-21, 2016, pp.308-313). MAYNTZ (2009 [2002], 2016) proposed and used this approach for obtaining explanations of macro-social phenomena, which usually entails single-case studies. However, causal reconstruction can be adopted for the discovery of causal mechanisms at lower levels of aggregation, where mechanisms operate in a larger number of processes. [11]
Since discovering causal mechanisms from data depends on the available empirical evidence, one would expect a detailed account of what that evidence must look like, how it can be collected, and how it should be analyzed. Unfortunately, proponents of process tracing provide little guidance on methods beyond references to "historical narratives" (BÜTHE, 2002, p.486; see also BENNETT & GEORGE 2005, Chapter 10 on "Process-Tracing and Historical Explanation"), "examining the evidence" (BENNETT & GEORGE 2005, p.6), or "gathering diverse and relevant evidence" (BENNETT & CHECKEL, 2015b, p.21). This lack of discussion is surprising because it is not self-evident that a new form of causal analysis is able to utilize traditional forms of data collection and analysis. [12]
The only methodological suggestion for the discovery of mechanisms links process tracing to case studies (BENNETT & GEORGE, 2005; GEORGE & McKEOWN, 1985; MAHONEY, 2000). Building on this argument, we propose that discovering mechanisms requires comparative case studies for two reasons. First, since a mechanism is a repeatedly occurring sequence of events, we need to observe more than one instance of a causal process in order to consider it as a candidate for a mechanism. Secondly, the discovery of a mechanism must be complemented by a description of the conditions triggering it and the conditions maintaining its operation. Identifying these conditions requires the inclusion of cases of mechanisms not being triggered or ending before the causal process is completed. The strategy best suited to this task has been described by GEORGE (2019 [1979], p.212) and GEORGE and McKEOWN (1985, p.41) as "The Method of Structured, Focused Comparison":
"A comparison of two or more cases is 'focused' insofar as the researcher deals selectively with only those aspects of each case that are believed to be relevant to the research objectives and data requirements of the study. Similarly, controlled comparison is 'structured' when the researcher, in designing the study, defines and standardizes the data requirements of the case studies" (GEORGE & McKEOWN, 1985, p.41).2) [13]
This strategy for the discovery of mechanisms has not yet been underpinned with more concrete methodological steps of qualitative research methods. Prominent qualitative approaches to causality like analytic induction and qualitative comparative analysis still emphasize the discovery of causal factors or necessary and sufficient conditions (HAMMERSLEY & COOPER, 2012; RAGIN, 1987, 2000). We found only one approach that is dedicated to the discovery of causal mechanisms, at least at a programmatic level:
"Our tests do not use the deductive logic of classical positivism. Rather, our explanations flow from an account of how differing structures produced the events we observed. We want to account for events, rather than simply document their sequence. We look for an individual or a social process, a mechanism, or a structure at the core of events that can be captured to provide a causal description of the most likely forces at work" (MILES et al., 2014, p.7). [14]
Unfortunately, the methodology designed by MILES et al. deviates from this agenda. Instead, the causal analysis they propose consists of building causal networks of influences between variables. Mechanisms producing these influences are largely ignored in the analysis. [15]
Thus, while there is a clear indication that qualitative research can lead to the discovery of mechanisms if comparative case studies are employed and the empirical material is used to reconstruct processes as well as the conditions under which they occur, it is not yet clear how this is supposed to happen. We contribute to answering this question by discussing the use of one specific version of qualitative content analysis—the version we developed—for causal reconstruction. [16]
3. Positioning Extractive Qualitative Content Analysis in Qualitative Research
The term "qualitative content analysis" is used for a variety of very different approaches (HSIEH & SHANNON, 2005; JACKSON, DRUMMOND & CAMARA, 2007; MAYRING, 2014; SCHREIER, 2012; STAMANN, JANSSEN & SCHREIER, 2016). Given this diversity, we will not discuss qualitative content analysis in general because such a discussion would imply a consistency that does not exist. We also refrain from reiterating a complete description of our version of qualitative content analysis, as it has already been published (GLÄSER & LAUDEL, 2010, 2013). Instead, we offer a very brief overview of our method and discuss the features that make it a distinct qualitative method that supports causal analysis. In this discussion we touch upon three themes of qualitative methodology; namely what constitutes a method, what makes a method qualitative, and what makes a method distinct. [17]
To consider the first two questions, we start from the understanding of a method as a set of prescriptive rules about steps that produce a specific kind of information about an object. Data collection methods consist of steps that lead to data about empirical objects, and methods of data analysis consist of steps that lead from these data to scientific knowledge. A description of a method should include definitions of the objects it can be applied to, of the rules about the steps to be followed, of the conditions under which the method can be applied, and of the information outputs produced by the method. [18]
Qualitative content analysis can be applied to texts that contain information pertinent to a particular research question. These usually include texts generated in a field under study for purposes of the field (documents) and texts generated either by researchers alone (field notes) or cooperatively by researchers and informants or respondents (qualitative interviews). Our version of qualitative content analysis produces a structured account of a text's relevant content by extracting information that is relevant to answering a particular research question and then ordering this information according to the information requirements of the investigation (Figure 1). It is thus different from MAYRING's version of qualitative content analysis, which is "a mixed methods approach: assignment of categories to text as qualitative step, working through many text passages and analysis of frequencies of categories as quantitative step" (2014, p.10). It is also different from SCHREIER's version because it clearly is not "a method for describing the meaning of qualitative material in a systematic way" (2012, p.1). We label our version as "extractive qualitative content analysis" (EQCA) in order to avoid confusion with other versions and highlight differences in comparison with them when necessary.
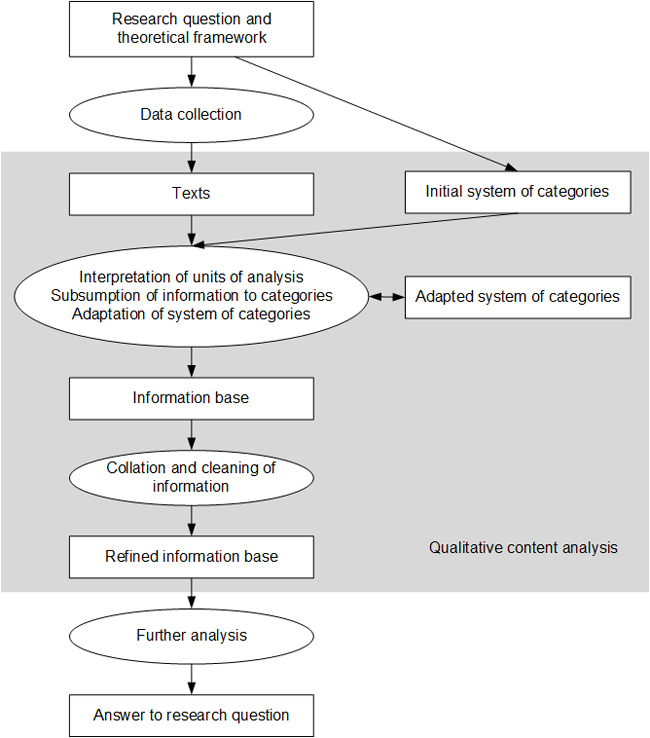
Figure 1: Extractive qualitative content analysis as a method in a qualitative research process [19]
The main steps of ECQA include developing a system of categories, extracting information by subsuming it under the categories, and consolidating the extracted information. For this approach, we define a category as a structured generalized descriptor that enables the delineation and extraction of empirical information. Most categories are constructed as multidimensional in order to capture qualitatively different but inherently linked properties of empirical phenomena. A system of categories is the set of categories designed to extract the information necessary to answer a particular research question. The initial construction of categories is informed by a study's theoretical framework. In particular, the multidimensional concepts of the theoretical framework are often used as the cores of categories. [20]
The information output of qualitative content analysis consists of data that are relevant to the research question, are structured according to the categories, and are described in the language of the researcher rather than the source. Irrelevant information is omitted, and the diversity of the language describing the information is reduced according to the conceptual framework of the study. [21]
This brief description must suffice to establish that EQCA is a method. However, is it a qualitative method? This question requires clarification mainly because doubts have been raised in the German qualitative research community concerning the status of qualitative content analysis as a qualitative method (JANSSEN, STAMANN, KRUG & NEGELE, 2017; ROSENTHAL, 2008, pp.200-205). Although not all stated criticisms apply to EQCA, we address this point because it is interesting from both a qualitative methodology perspective and from a sociology of science perspective. [22]
We start from a definition of qualitative methods as methods that are based on the reconstruction of meanings given to phenomena by the subjects under study. We believe that this definition
captures the difference between qualitative and quantitative methods (the standardization on which the latter are based prevents the reconstruction of meaning);
contains an explanation why the principle of openness is an important premise of all qualitative research (the meaning participants give to their world can only partly be anticipated); and
includes a justification of the diversity of qualitative methods because it highlights the different uses to which the reconstruction of meaning can be put. [23]
With regard to the last point, the difference between the reconstruction of meaning as the outcome of qualitative research and the reconstruction of meaning as a means to an end (namely explanation) is important. If the reconstruction of meaning is the main outcome of a qualitative research process, the methods used must support the in-depth exploration of meaning. However, if the reconstruction of meaning is a means to an end, methods must balance the reconstruction of meaning with the collection of data that are necessary for achieving an explanation.3) [24]
When we apply these definitions and distinctions, EQCA could be considered as a qualitative method if it enables the reconstruction of meaning and if it enables the capture of unexpected information in the data. This is indeed the case. ECQA fulfils the first criterion because the extraction of information from texts is based on understanding the meaning given to this information by those who created it (e.g., the authors of documents or interviewees) and on considering the context of the text that is interpreted. Since the consideration of context is clearly limited in all versions of qualitative content analysis, including EQCA, we must clarify this aspect. We would like to advance two arguments here. First, all versions of qualitative content analysis enable an atomistic approach, i.e., enable researchers to treat units of analysis (text segments like sentences or paragraphs) independently from the surrounding text. This approach appears to be not uncommon. For example, some researchers begin data analysis by coding text and then retrieving all text segments tagged with the same code for qualitative content analysis (KELLE, 1997, §5.9; MILES et al., 2014, p.72 recommending this procedure). However, we consider this selective retrieval and clustering of text dangerous because it makes interpretations more susceptible to errors. Interpreting text segments in isolation cuts through both explicit cross-references (e.g., "because of this incident I told you about earlier") and implicit cross-references or meaning given to particular terms or phrases in preceding segments of the text. This is why we strongly recommend a sequential approach in which each interpretation of a unit of analysis is informed by the interpretations of all preceding units of analysis of the same text. [25]
Secondly, the analyst's reconstruction of meaning is constrained by the sequential approach of EQCA. The structured, step-wise interpretation and extraction of information by means of a system of categories generates comparable information for focused, structured comparisons (see above, Section 2) but a full reconstruction of meaning requires a holistic approach in which each unit of analysis is interpreted in the light of the complete text. For the research questions EQCA can be applied to, we consider the possible distortion of interpretations that are based on the unit of analysis and the text preceding it (the "interpretation error") to be small enough to be acceptable.4) By the same token, EQCA should not be applied to research questions requiring holistic analysis (see below). [26]
Concerning the second criterion, the openness of EQCA and other versions of qualitative content analysis depends on the openness of categories and on the openness of the system of categories. We work with multidimensional categories whose dimensions have nominal open "scales." This means that the dimensions of a category capture aspects of empirical instances as they occur rather than subsuming them under predefined "values." For example, when we use the category "expectations of the scientific community" in our sociological analysis of research practices, the dimension "source of expectations" describes the actor who, according to the interviewee, communicated an expectation. In this dimension, we could build a list of empirical instances that include "group leader," "colleague," "reviewer of manuscript," "reviewer of project proposal," "member of recruitment committee" and so on. If an empirical instance can unambiguously be assigned to an already existing descriptor, this descriptor is thus used; otherwise, a new one is added. In this way, we achieve some unification while simultaneously making sure that we capture the specific empirical information communicated by the author of the analyzed text. [27]
With regard to the openness of the system of categories, we can reiterate a point made in prior research (GLÄSER & LAUDEL, 2013)—namely that creating a fixed system of categories using only part of the data does not constitute a sufficiently open procedure. This approach was proposed by SCHREIER (2012) and MAYRING (2014), the latter of whom states the following:
"After working through a good deal of material (ca. 10-50 %) no new categories are to be found. This is the moment for a revision of the whole category system. It has to be checked, if the logic of categories is clear (e.g. no overlaps) and if the level of abstraction is adequate to the subject matter and aims of analysis. Perhaps the category definition has to be changed. If there are any changes in the category system, of course the complete material once again has to be worked through" (p.81). [28]
Although this approach is very responsive to unexpected data, it is responsive only to the material used for inductive category building, i.e., to 10% to 50% of all of the material. We find the statement that after working through half the material "no new categories are to be found" to be highly optimistic. If category development leads to a fixed system of categories, true openness requires that all of the material is analyzed again if the last 10% necessitates a change of categories. This was suggested by SCHREIER (2012, pp.199-202). Furthermore, replacing theoretically derived categories by inductively constructed ones, if necessary, might satisfy the need for openness but undermines a strength of EQCA, specifically its support for a theory-guided analysis of data. Since conflicts between previous theory and data are interesting findings and deserve deliberation, we change categories by complementing rather than replacing theory-based categories with inductively constructed categories or dimensions of categories (GLÄSER & LAUDEL, 2013, §77). In this way, conflicts between data and theory are preserved, and are resolved when all relevant information can be considered, i.e., after the initial round of extraction is completed. [29]
Due to reconstructing meaning and being open to information and meanings in the data that have not been anticipated, EQCA can be deemed to be a qualitative method. It is also a distinctive method because its information output distinguishes EQCA from other qualitative methods (and from other versions of qualitative content analysis). The major difference in comparison with quantitative content analysis is that complex information is extracted without being reduced to standardized descriptors or ordinal scales such as "high," "medium," and "low," The main difference as compared with coding is that text segments are not tagged according to what is talked about but processed, i.e., what is actually said is paraphrased and extracted for further analysis. Additionally, the major difference to other versions of qualitative content analysis is that information is extracted rather than described or "classified" (SCHREIER, 2012, p.1). [30]
An important difference between EQCA and many other qualitative methods of data analysis is that the application of the former produces an intermediate resource for further analysis rather than ultimate answers to research questions. While e.g., narrative inquiry (CLANDININ, 2006), thematic analysis (BRAUN & CLARKE, 2006) or critical discourse studies (MEYER, 2002) cover the whole process from texts to answers, EQCA only covers the process leading to an information base that is then further analyzed. Of course, EQCA is not the only method that has such an intermediate function: when coding is used as a separate method, this also leads to an information base to which a variety of further analysis can be applied (GLÄSER & LAUDEL, 2013). The information base is then used to identify patterns in the data and integrate these patterns, for example by building and comparing empirical typologies. [31]
To sum up our argument, we consider EQCA to be a qualitative method for the interpretation of text segments in light of all preceding segments, the extraction of information from these texts, and the reduction of information by excluding information that is not relevant to the research question as well as paraphrasing the original text. Its output is a structured information base that needs to be subjected to further analysis in order to answer research questions. If qualitative methods are narrowly defined as methods that support the analysis of a text as a whole (its Gestalt), the interpretation of each element of the text in the context of the whole text, and the reconstruction of not only the text's manifest but also of its latent meaning, then qualitative content analysis in whatever version cannot be considered a qualitative method. If, however, these criteria are deemed necessary only for specific purposes of qualitative research and unnecessary for others (which we suggested with our own definition of qualitative methods), then ECQA can be considered as a qualitative method for specific purposes. [32]
This positioning of EQCA enables some conclusions about the research questions it can and cannot support. First, since users of EQCA must start from conceptual considerations and derive the "entry point" system of categories from their research questions, the method can be applied in any investigation that has a clear research question from which categories can be derived. It is thus well suited for investigations featuring a theoretical research question but is unsuitable for purely explorative research questions.5) Secondly, whenever the answering of a research question requires the recombination of information across texts or cases, EQCA can be used because it creates an information base that fits this purpose. This is why it is applicable in research designs for the reconstruction of social situations or processes, and particularly in designs based on comparative case studies. Thirdly, the output of EQCA is an input for further work such as systematic comparisons, the construction of typologies, or causal analysis. [33]
EQCA consists of steps that lead to specifically reduced and structured information, which facilitates further analysis for the purposes of answering research questions as described above. We now turn to one type of research question we consider particularly interesting, which is the discovery of causal mechanisms. [34]
4. Discovering Causal Mechanisms with Extractive Qualitative Content Analysis—An Example
We demonstrate our approach with a research project aimed at the discovery of mechanisms leading to the first individual research programs (IRPs) of early-career researchers (ECRs) in the following three fields: plant biology, experimental atomic and molecular optics, and early modern history (LAUDEL & BIELICK, 2018). IRPs are plans for future research that exceed the scope or time frame of a single research project. The aim of the study conducted by LAUDEL and BIELICK (LB) was to find the causal mechanisms that led to the development and implementation of such plans by ECRs under current career conditions in Germany, and whose absence or malfunction left researchers without IRPs. [35]
In order to discover these mechanisms, LB conducted comparative case studies of ECRs. They expected initial conditions and operating conditions to be field-specific and therefore compared nested cases: on the higher level of aggregation, each field of research constitutes a case, while on the lower level of aggregation, each ECR also constitutes a case. [36]
In the following, we describe the process of discovering these causal mechanisms with examples from the field of plant biology. A total of 31 plant biologists were studied. LB selected researchers who obtained their PhD degree between two and nine years prior to the time of their interview. Most of these researchers held non-tenured positions (e.g., postdoc, university assistant, junior group leader or junior professor), which are common in the early-career stage in the German academic system. [37]
Data collection was based on semi-structured interviews with ECRs and individual-level structural bibliometrics (GLÄSER & LAUDEL, 2015a; LAUDEL & GLÄSER, 2007).6) The interviews consisted of two main parts. In the first part, the interviewee's research was explored. LB traced the development of the interviewee's research since their PhD project with an emphasis on thematic changes and the reasons for these. In the second part of the interview, LB focused on decisions made by the interviewee to take up each position, possible alternatives (positions not taken up and/or unsuccessful applications), and the conditions of research provided by each position. [38]
To prepare for the interviews, LB collected CV data, publications lists, full-text publications and other information about each interviewee's research. Most interviewees provided them with additional information about their research such as research statements or grant proposals. They used these documents when preparing for the interviews and included them in the data analysis. The interviews lasted about 90 minutes each and were fully transcribed. [39]
4.1 Theoretical background and categories for extractive qualitative content analysis
The research project drew on a discussion from the higher education literature about the process by which ECRs become independent researchers, as well as the sociology of science literature on individual research programs and research biographies (ÅKERLIND, 2005; CHUBIN & CONNOLLY 1982; HACKETT, 2005; LAUDEL, 2017; LAUDEL & GLÄSER, 2008; OWEN-SMITH, 2001). On the basis of this literature we defined an IRP and constructed dimensions in which IRPs vary. In order to embed IRP development in the progress of ECRs' careers, LB used a model that analytically separates three aspects of an academic career, namely the cognitive career (the sequence of projects a researcher is working on), the community career (the development of reputation and status in one's scientific community), and the organizational career (the sequence of organizational positions) (GLÄSER & LAUDEL, 2015b; LAUDEL & GLÄSER, 2008), respectively. Assumptions about relevant conditions of actions were derived from the analytical approach of actor-centered institutionalism (MAYNTZ & SCHARPF, 1995) and the sociology of science literature (e.g., HACKETT, 2005; KNORR-CETINA, 1999; OWEN-SMITH, 2001). [40]
Figure 2 shows the hypothetical causal model with the main variables and assumed causal relationships between them. LB assumed the mechanism—the recurrent sequence of events—to operate through the following two kinds of actions of ECRs: their decision on which position to take (all ECRs went through a series of postdoctoral positions) and their development of their IRPs. The conditions that can affect ECR's actions (and thus the mechanism) include the following:
the availability of autonomy, time, and resources for research;
the knowledge previously accumulated by the researcher;
epistemic conditions of research, i.e., material properties of research objects and methods as well as properties of knowledge that affect the ways in which knowledge is produced in a field;
the knowledge of a researcher's scientific community and the community's expectations concerning IRPs; and
contributions to the community's knowledge. [41]
An important intervening factor that modifies the impact of these conditions on the emergence of IRPs is the ECR's interests. [42]
Although an analytical distinction between independent, dependent and intervening variables is possible for each moment in time, the concept of a mechanism as a sequence of causally linked events implies that each event changes the conditions for subsequent events. This dynamic must be taken into account because the mechanism LB searched for was likely to span a sequence of positions that ECRs went through, with current conditions affecting their decisions to move from one position to certain others that provided different conditions and so on. We represent this dynamic by feedback arrows in the causal model (Figure 2). Notably, although career researchers agree that ECRs go through a sequence of positions, they are largely silent about the content of work in these positions and its evolution. This is why it was impossible to formulate an assumption about what the mechanism could look like.
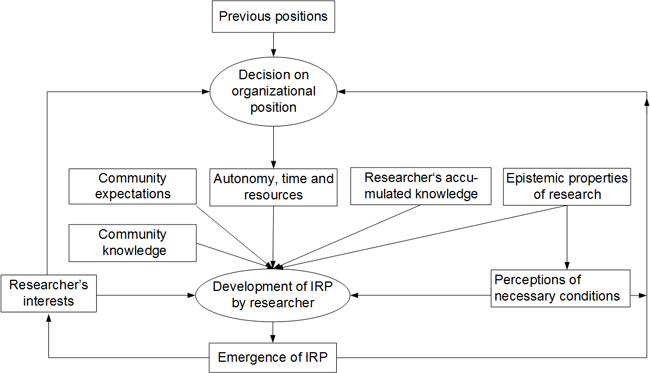
Figure 2: Hypothetical model of variables influencing the emergence of IRPs7) [43]
LB's construction of categories for EQCA started from the hypothetical causal model. Some variables can be translated into categories in the following three steps.
Establish the dimensions of the variable and use them as dimensions of the category. Theoretical variables like "community expectations" describe complex phenomena with several distinct properties that are inherently linked, and which cannot be treated separately.8) These dimensions of the theoretical variables are also used as dimensions of categories to capture the aspects about which information is provided.
Add a time dimension. Social phenomena constantly change, which is why it is very important to identify the point in time or the period of time for which information about the phenomenon is provided.
Add "causal" dimensions. Causes and effects of the social phenomenon that a category is supposed to capture are often reported in texts generated in the field, and by interviewees. This reported causality constitutes important empirical information that is extracted with the dimensions "reported causes" and "reported effects." [44]
Not all theoretical variables can be translated into categories. Since categories link theoretical interests to the presentation of empirical phenomena in texts (particularly interviewee responses), they cannot always be constructed by merely adapting theoretical variables. Some of the variables are too abstract. If they were translated into categories, these categories would enforce on-the-spot generalizations, or generalizations from the information in the unit of analysis that ignore other relevant empirical material. These generalizations would replace the specific information in the text with concepts that may prevent the researcher from understanding the extracted information in later stages of the analysis. For example, if a category "autonomy" is used, the researcher might be forced to make generalizations from specific information about research conditions and to categorize this information as a description of autonomy. [45]
Other variables represent analytical distinctions that do not correspond to the ways in which empirical information is represented in texts. Again, directly translating these variables into categories would enforce decisions about the meaning of information that should not be made while interpreting a single unit of analysis. For example, when ECRs describe how they accumulate scientific knowledge during their postdoctoral career, it would be very difficult to decide from the interpretation of one such description whether this knowledge becomes part of the IRP (which would be one category) or instead is "just" accumulated knowledge (which would be another category). [46]
In the end, only one variable of our hypothetical model could be directly translated into a category, i.e., could unambiguously be linked to empirically observable phenomena (Table 1). Specifically, LB constructed the category "epistemic conditions" from "epistemic properties of research." Separately, for a number of other variables, they created composite categories. The category "(other) research conditions" was created from "autonomy, time and resources," which is represented as one variable in Figure 2, but which is actually a bundle of three variables. The category "research trail" encompassed three variables ("researcher's accumulated knowledge," "development of IRP by researchers," and "emergence of IRP") and captured all information about an ECR's previous, current and planned research and their characteristics. The variables "community expectations" and "community knowledge" were combined in the category "community expectations" because it was difficult to empirically separate a scientific community's career expectations from an interviewee's knowledge about them. Our category "decisions" contained not only decisions about organizational positions, but also the role that perceptions of necessary conditions for IRP development played in these decisions and in other strategic actions such as applications for grants and negotiations about topics with other actors. [47]
Elsewhere, LB had to split two other variables. The variable "previous position" was separated into a category "career position" to capture the organizational career and "perception by the scientific community" to capture an ECR's career in their scientific community, respectively. Also, the variable "researcher's interests" was enriched and developed into two categories. The category "actor traits" was rather loosely defined and contained a researcher's interests and other specific personal characteristics that might affect decisions on careers (e.g., the specific research area, knowledge, and family situation). A second category, "career plan" was designed to capture a researcher's specific longer-term interests in terms of their organizational and cognitive careers. [48]
These translations led to a system of nine broad categories. In Table 2 we describe two examples.
|
Element of the Hypothetical Model |
Category |
|
Epistemic properties of research |
Epistemic conditions |
|
Autonomy, time and resources |
Research conditions |
|
Researcher’s accumulated knowledge |
|
|
Development of IRP by researchers |
Research trail |
|
Emergence of IRP |
|
|
Community expectations |
Community expectations |
|
Community knowledge |
|
|
Decisions about organizational positions + other strategic decisions |
Decisions |
|
Assumptions about necessary conditions |
|
|
Previous position |
Career position |
|
|
Perception by the scientific community |
|
Researcher’s interests |
Actor traits (for short term interests and other personal characteristics) |
|
|
Career plans (for long-term interests) |
Table 1: Translation of elements of the hypothetical model into categories
|
Category Career Position |
|
|
Definition |
An ECR’s organizational career (sequence of positions) and characteristics of the position |
|
Dimension |
Definition and possible values |
|
Time |
Time span during which the ECR held the position |
|
Type of position |
Precise description of position (e.g., postdoc, DFG postdoctoral fellow, junior professor), including affiliation and name of research group |
|
Characteristics of the position |
Formal duration, full-time/ part-time, etc. |
|
Scope |
Specific characteristics/ general characteristics of this type of position |
|
Reported causes |
Decisions that led to the research content, interests, job position, funding |
|
Reported effects |
Effects on IRP development, career decisions, funding decisions, etc. |
|
Category Research Trail |
|
|
Definition |
Information about previous, current and planned research activities and their characteristics |
|
Dimension |
Definition and possible values |
|
Time |
Point in time or time span during which the research activity is/was reported (including future) |
|
Research topic |
Concise identifier of the content of a project or of a series of projects |
|
Characteristics of research |
Property that is described - Element of research (method/object/problem) - Other epistemic characteristics (e.g., risk, conformity to the scientific community, duration, competition, interdisciplinarity, fundamental or applied character) |
|
Content of research |
Content of the research trail that is reported: - Changes such as topic started, continued, stopped, not started, resumed, expanded - Other epistemic characteristics of research line (see above) |
|
Reported causes |
Decisions that led to the research content, interests, job position, funding |
|
Reported effects |
Effects on IRP development, career decisions, funding decisions, etc. |
Table 2: Definition and dimensions of two categories [49]
4.3 Extracting information from interview transcripts and processing the extracted data
LB extracted information with the system of categories from interview transcripts. Other texts and the visualization of research trails were used ad hoc in later stages of the causal reconstruction. Since LB used paragraphs to separate themes when formatting interview transcripts, they decided to use paragraphs as the units of analysis. For each paragraph of an interview, relevant information was extracted and subsumed under the appropriate categories. During the extraction of information from the first interviews, LB developed extraction rules about the assignment of information in ambiguous cases. For example, they noticed an overlap between the categories "career position" and "research conditions" because the characteristics of the position could include information about research conditions. To guarantee that this kind of information was unambiguously assigned, LB introduced the following extraction rule: "If a description of characteristics of a position includes information about conditions of research, then extract it with the category 'research conditions'." [50]
The last step of EQCA consists of a revision of all extraction results. For any extracted information that was contradictory, LB checked whether the contradiction was the result of obvious errors, such as dates or organizational positions mixed up by interviewees. If this was the case and could be unambiguously determined as true without complex interpretations, the errors were corrected. In a second step, LB sorted the extracted information for each individual case. Results describing processes, e.g., the information in the categories "research trail" and "decisions", were sorted chronologically. Other categories like "community expectations" were sorted into subject matter. The Appendix contains excerpts of extraction tables for the categories "research trail" and "community expectations." [51]
With this step, the EQCA was completed, and the information base could then be used for causal analysis. The following description of the approach is limited to the analysis of plant biology and plant biologists. [52]
The identification of mechanisms and the conditions under which they operate was conducted as a causal reconstruction. LB began with the identification of IRPs and then searched for the sequences of events that led to IRPs. From these sequences they derived the mechanisms and identified their initial and operating conditions. [53]
Step 1: Identifying IRPs
The outcome of the mechanism LB looked for was an ECR's first IRP. To identify IRPs, they first excluded all ECRs who did not aim for independent research but who planned to end their research career or preferred to conduct research directed by group leaders. This left them with two sources for identifying IRPs. The first source was interviewees who conducted independent research as group leaders, which meant that they were implementing IRPs. The second source was the collectively shared frames of the scientific community concerning IRPs, which were expressed by plans for future independent research from those ECRs who still worked as dependent postdocs. The comparisons within and between the two groups revealed a consistent pattern of an IRP as encompassing a series of interconnected projects that address a limited set of questions about biological processes by investigating an "interesting" object. "Interesting" objects were generally plants, cells, or proteins that expressed thus-far-unexplored biological properties or combinations of such properties. The objects were produced by creating mutants and screening them for unexplored biological properties. [54]
Step 2: Identifying the sequences of events leading to IRPs
LB reconstructed the processes leading to the current research of each ECR by recombining information from several categories and condensing them into overviews of ECRs' research biographies (Figure 3). In these overviews, they represented the development of an ECR's research and the sequence of organizational positions (i.e., PhD student, postdoc, etc.). They retrieved these data from the extraction tables of the categories "research trail" and "career position." These overviews of the research show the content of the work leading up to the current research, which includes learning processes in the postdoc phase (e.g., learning new methods). The overview of organizational positions links the development of the research with the positions during which this work was done. These overviews were also produced for those ECRs who had not (yet) developed an IRP (see the discussion of these cases below). [55]
In addition to these graphical overviews, LB created brief written descriptions of an ECR's research and reasons for undertaking it (Figure 4). These descriptions were mainly based on information from the extraction table of the category "research trail," which was complemented with information from the extraction tables of the categories "actions" and "research conditions." At first glance, this approach may resemble case summaries that have been suggested as a tool in the literature on coding qualitative data (e.g., KUCKARTZ, 2014). However, LB's intention was not to create a comprehensive story for each case. Instead, they aimed at establishing a selective description that carved out the sequence of research processes, including reported reasons for research decisions. Since the summaries were based only on a few categories, they cannot be considered full case summaries.
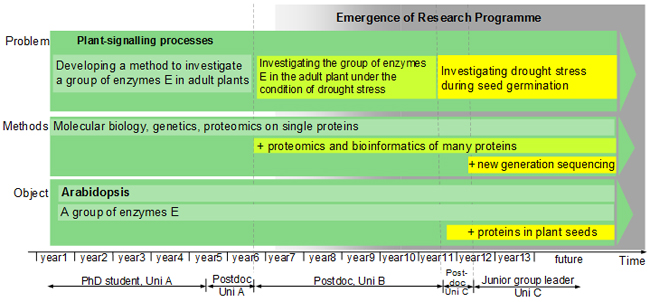
Figure 3: A plant biologist's IRP development and organizational career (LAUDEL & BIELICK 2018, p.979)

Figure 4: An example excerpt of an ECR's research processes and reasons for research decisions [56]
From these overviews, LB identified the actions that created the necessary ingredients of an IRP in plant biology, i.e., the "interesting object" and the methodological knowledge for experimenting with it. The object was found by creating mutants of cells or plants and then screening them for interesting biological properties. The methods were learned by moving to groups possessing expert knowledge about them. [57]
Step 3: Deriving the mechanism
LB compared all cases in order to find recurrent sequences of events that led to IRP development. For this step, they drastically reduced the information of the graphic representation and created one timeline of IRP emergence for each ECR (Figure 5). This made it possible to compare sequences of positions for researchers who had not (yet) developed an IRP, those who developed it already at the end of their PhD, others who did this during the first three years, and again others who took considerably more time. LB also found that the sequence of formal positions did not show a pattern that could be linked with success or failure in the development of IRPs.
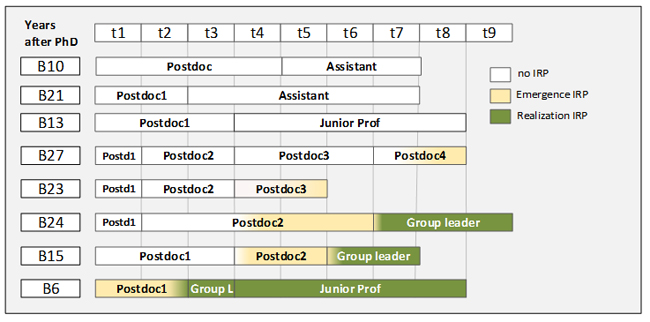
Figure 5: Comparison of IRP development of plant biologists (extract) [58]
In order to find the sequence of events that was necessary for the emergence of an IRP, LB started with the largest group of cases where ECRs had successfully developed an IRP. The process overviews for these cases revealed some steps that all researchers went through while building an IRP. Specifically, plant biologists first created, screened and tested objects to find candidate objects upon which an IRP could be based. They then checked the relevance of these candidates for their community and the degree of competition on this topic. In a third step, they negotiated the "ownership" of the chosen object with their senior group leader (which is necessary because they produced it as dependent researchers using the group leader's resources). Finally, they systemically formulated an IRP and sought approval by their scientific community (by applying for grants for building a research group). [59]
In order to confirm that this is the necessary sequence for producing an IRP, LB had to explain all cases. They started from distinguishing between cases of straightforward IRP development (containing all the steps described above once, taking about three years), and deviant cases. Deviant cases included cases of researchers who failed to develop an IRP. Some of these researchers were successful with later attempts, while others still had not developed an IRP at the time of the interview. A second group included ECRs who had not even attempted to develop an IRP because they were aiming for a career outside academia, were unaware of the necessity to develop an IRP, unaware of how to go about developing an IRP, or were so occupied with their group leader's projects that they didn't have time for developing their own IRP. [60]
The third group of deviant cases consisted of researchers who developed their IRP much earlier than was to be expected in the light of the sequence LB derived from the majority of cases. It turned out that these researchers did indeed go through all steps but managed to do so during the time in which they worked on their PhD projects and were able to complete the sequence in one or two years after their PhD. [61]
The analysis of deviant cases was part of a general check of all cases as to whether the mechanism operated or not. Table 3 provides an excerpt of the cross-tabulation of the sequence of events constituting the mechanism against the cases. It shows three cases of plant biologists and their attempts to develop an IRP. The rows contain the major steps of the mechanism.
|
Event |
Case B2 |
Case B2 |
Case B5 |
Case B12 |
Case B12 |
|
Learn methods |
Proteomics |
|
Several new methods |
Whole Proteomics |
Bioinformatics; next-generation sequencing |
|
Screen objects |
Screening for interaction partners of enzyme family X in [plant] with proteomics |
Screening with Proteomics of [plant] (early stage of [..] development) |
Screening by Transcriptome Analysis |
Screening by Proteomics |
Screening with next-generation sequencing |
|
Search for suitable candidates |
Not enough candidates (abandoned topic) |
Found enough candidates |
Found new group of genes |
Found not enough interesting candidates |
Found interesting genes |
|
Check whether relevant and competition low |
|
Yes (function of enzyme family X in this new object) |
Their function was completely unknown, nobody worked on them |
|
Yes (connects two communities), competition low |
|
Coordination with group leader |
|
PhD group leader contested it (too close to his own topic) |
Wasn’t necessary (group leader was not interested) |
|
Not necessary (he had selected the topic, group leader was not interested) |
|
Formulation of IRP and approval by the community |
|
Wrote grant proposal, proposal was rejected |
Wrote grant proposal, approved |
|
(Not yet) |
Table 3: Cross-tabulation of cases against steps of the mechanism [62]
This cross-tabulation strengthened the argument that a candidate mechanism had been identified because cases of successful IRP development could be shown to have gone through all steps, while those without IRPs could be shown to have not (yet) undergone all the steps. [63]
Step 4: Identifying initial and operating conditions of the mechanism
The deviant cases also revealed important initial and operating conditions of the mechanisms, namely the ECR's interest in pursuing an academic career, knowledge about how to develop an IRP, and control over part of their time for research. Further initial and operating conditions were revealed by examining all cases within the field of plant biology: for example, ECRs required a certain level of reputation to secure their next position, which most of them were able to achieve by continuously publishing. They also needed basic conditions for research met, such as access to experimental infrastructure and resources, as well as time for research. A comparison with the other two research fields led to the identification of field-specific conditions for the mechanisms and helped to explain why the mechanisms that produced IRPs were specific to each field (Figure 6).

Figure 6: Mechanism of IRP emergence in the field of plant biology (LAUDEL & BIELICK 2018, p.998 and p.1001) [64]
The EQCA we presented here was based on a clear research question with some theoretical background. However, while the existence of a causal mechanism could be assumed, it was impossible to imagine the mechanism itself. It had to be discovered. [65]
The discovery process (unknowingly) followed the approach of causal reconstruction suggested by MAYNTZ (2009 [2002], 2016). We identified the outcome (an IRP) and worked backwards through the processes that produced the outcome. An important aspect of our approach that has ramifications for the discovery of mechanisms with qualitative methods is the number of cases we used. Discovering the three mechanisms (one in each research field), their initial conditions, and their operating conditions depended upon including a relatively large number of cases. Conducting these comparative case studies was only possible because the cases were individual ECRs who were interviewed once, and because two researchers worked for three years on a total of 87 cases in three fields. The typical number of cases in qualitative research is much lower. When cases are defined at higher levels of aggregation and only a few cases can be analyzed, the information on the mechanism itself and on the conditions under which it operates is likely to be incomplete. Nevertheless, the analysis of five or six cases can already result in the discovery of causally linked events that repeatedly occur in reality, i.e., to a candidate mechanism. [66]
It is important to emphasize that the process of discovering the mechanism was not as straightforward as presented here. There was much trial-and-error involved. We created many condensed tables and overviews that did not reveal any interesting patterns and subsequently abandoned them. Even with general guidance like "causal analysis" or "causal reconstruction," finding patterns in the data is a creative, messy, iterative process for which no recipe can be provided. [67]
The example we provide challenges the distinction between "across-case" and "within-case" analysis. Identifying mechanisms requires a back-and-forth between the within-case identification of sequences of events that are candidates for mechanisms and comparisons of cases that enable the identification of necessary steps, deviations, initial and operating conditions, and so on. Based on this experience, we doubt that it is possible to link the two forms of case analysis to different strategies of causal inference, as GEORGE and McKEOWN (1985) suggested. [68]
In our example, the application of EQCA provided an information base for the causal reconstruction by using prior theory to structure the collection of relevant information. It supported the identification of the outcomes of processes, the reconstruction of the processes themselves, and the connection of conditions to the mechanism that was identified. The limitations produced by the sequential rather than holistic approach to the reconstruction of meaning appear to be admissible. While we cannot be sure without comparing the "local" reconstructions realized by EQCA to "holistic" reconstructions with the same texts, we have not yet encountered significant contradictions between local reconstructions that could be ascribed to insufficient consideration of context. Thus, EQCA is a method that can be used for specific purposes, namely purposes requiring the use of qualitative data for the reconstruction of social situations and processes. These purposes include the discovery of causal mechanisms. [69]
If we aim at progress in the social sciences, and if this progress consists of achieving better explanations of social phenomena, then the discovery of causal mechanisms is a key issue of social science methodology. While not everyone will agree with these premises, there can be little doubt that the discovery of causal mechanisms crucially depends on qualitative research. [70]
The literature suggests two ways by which causal mechanisms can be discovered. First, a mechanism can be hypothesized and the hypothesis about the presence of the mechanism can then be empirically tested. Secondly, the mechanism can be searched for in the empirical material. The information requirements of both approaches and the resulting demands on data collection and data analysis have not yet received sufficient attention. This is why we discussed the use of EQCA for the discovery of causal mechanisms by causal reconstruction. Our discussion of this method and of subsequent steps of causal reconstruction leads to four conclusions. [71]
First, there is an essential tension between the conceptualization of a mechanism as a repeatedly occurring sequence of events and the strength of qualitative research, namely the in-depth analysis of relatively few cases. Identifying a sequence of events that occurs more than once and the conditions under which this happens requires comparative case studies. The specifics of qualitative methods limit the number of cases that can be investigated with sufficient depth, which means that only a few cases can be employed for the discovery of a mechanism. Our "proof-of-concept" example obscured this problem because each case was based on one interview and accompanying material, which made it possible to include a much larger number of cases than is common in qualitative research. Cases on higher levels of aggregation are likely to require more interviews. This means that fewer such cases can be investigated in a qualitative study, and findings on mechanisms will always be intermediate contributions to evolving theories of the middle range. [72]
Secondly, the discovery of mechanisms is likely to require the reconstruction of social situations and processes. EQCA supports exactly this reconstruction by enabling its user to create a structured information base. The extraction of all information that is relevant to a particular research question reduces and structures the empirical material in a way that supports systematic comparisons of cases while at the same time keeping the full information content available. The openness of categories for non-standardizable information and for unexpected findings prevents theoretical assumptions from excluding unpredicted information. [73]
Thirdly, our attempt to specify the potential of ECQA for a specific purpose also leads to questions about qualitative methodology. The questions we asked about EQCA were aimed at contributing to an account of which methods are suited for what purpose, and why. Although we have an impressive body of literature on qualitative methodology, we have far too little comparative methodology. Instead, the methodological discussion seems to bifurcate into fundamentals on the one hand, and the perusal of single methods on the other. [74]
This comparative methodology should also make more transparent where methods begin and end. Our discussion of EQCA describes a structured information base as the output of the method and discusses causal analysis as one possible way of using this information base. Some other methods go all the way from texts to final findings. However, it would be interesting to screen methods for steps that are constitutive parts of the method as well as steps of working with data that are more generic. Defining end points and outcomes of methods would support a comparative methodology by making comparisons more precise. [75]
Finally, we would like to propose a more systematic consideration of causal analysis. The current dominant understanding of process tracing as a means for empirically testing the existence of hypothesized mechanisms severely limits its potential to contribute to explanations by truly discovering causal mechanisms from data. Ultimately, this is about establishing qualitative research as an indispensable (and possibly superior) approach to causal analysis. [76]
We are grateful to the Write Club of the Institute of Sociology at the TU Berlin, Christopher GRIESER and two reviewers for their extensive and helpful comments.
Appendix: Extraction of relevant information with EQCA
Table A1 contains all the information about "community expectations" that was extracted from the interviews with biologists B1 and B2. The extraction tables contain empty cells because units of analysis did not always contain complete information on a category.
Table A1: Extraction table "community expectations" for two interviews. Click here to download the PDF file.
Table A2 contains all the information about research processes in the postdoctoral phase of plant biologist B28 (sorted by time and summarized). It contains information from 17 paragraphs of the interview transcript (in total, 39 paragraphs of this interview transcript were extracted with this category)
Table A2: Extraction table "research trail" for one case (excerpt). Click here to download the PDF file.
1) Without further discussion, we add that we assume that mechanisms are not necessarily unobservable, agreeing with MAYNTZ (2004, pp.242-243), and are not necessarily deterministic, agreeing with FALLETI and LYNCH (2009, p.1147), respectively. <back>
2) This approach and its steps (GEORGE & McKEOWN) are in accordance with our own strategy (GLÄSER & LAUDEL, 2010). <back>
3) Qualitative approaches that use the reconstruction of meaning for explanations are in line with WEBER's definition of sociology as "a science that in construing and understanding social action seeks causal explanation of the course and effects of such action" (2019 [1922], p.78). <back>
4) The sequential approach does not, of course, prevent us from retrospectively changing interpretations upon discovering later on in the process that we misunderstood the meaning given to a phenomenon by the interviewee or the author of the text. <back>
5) As will become clear in the following section, "theory" in this context refers to middle-range theories, i.e., theories that "[…] deal with delimited aspects of social phenomena" (MERTON, 1968, pp.39-40). These theories are often neglected because most social researchers spend their energy instead on the exegesis of general social theory or on descriptions of the social world. <back>
6) Individual-level structural bibliometrics uses the interviewee's publications to reconstruct their research biography. We produce a network of the interviewee's publications and project it on a time axis to visualize thematic continuity and change. These visualizations are used for the "graphic elicitation" of responses in interviews. <back>
7) LAUDEL and BIELICK (2018, p.976). This is a slightly simplified version of the original figure. <back>
8) For example, a prescriptive rule has a subject matter, a content, a scope, and a degree of formalization. These properties are distinct but inherently linked. It does not make sense to consider the degree of formalization or the scope separate from the content of the rule. See also STRAUSS and CORBIN (1990, pp.69-72) on dimensionalizing properties of empirical phenomena. For a more extensive discussion of dimensions, see GLÄSER and LAUDEL (2013). <back>
Åkerlind, Gerlese S. (2005). Postdoctoral researchers: Roles, functions and career prospects. Higher Education Research & Development, 24(1), 21-40.
Beach, Derek (2017). Process-tracing methods in social science. In William R. Thompson (Ed.), Oxford research encyclopedias of politics: Qualitative political methodology (pp.1-28). Oxford: Oxford University Press, https://doi.org/10.1093/acrefore/9780190228637.013.176 [Date of Access: September 11, 2019].
Beach, Derek & Pedersen, Rasmus Brun (2013). Process-tracing methods: Foundations and guidelines. Ann Arbor, MI: University of Michigan Press.
Beach, Derek & Pedersen, Rasmus Brun (2016). Causal case study methods: Foundations and guidelines for comparing, matching, and tracing. Ann Arbor, MI: University of Michigan Press.
Bennett, Andrew & Checkel, Jeffrey T. (Eds.) (2015a). Process tracing: From metaphor to analytical tool. Cambridge: Cambridge University Press.
Bennett, Andrew & Checkel, Jeffrey T. (2015b). Process tracing: From philosophical roots to best practices. In Andrew Bennett & Jeffrey T. Checkel (Eds.), Process tracing: From metaphor to analytic tool (pp.1-37). Cambridge: Cambridge University Press.
Bennett, Andrew & George, Alexander L. (2005). Case studies and theory development in the social Sciences. Cambridge, MA: MIT Press.
Boudon, Raymond (1976). Comment on Hauser's "Review of education, opportunity, and social inequality". American Journal of Sociology, 81, 1175-1187.
Boudon, Raymond (1979). Generating models as a research strategy. In Robert K. Merton, James S. Coleman & Peter H. Rossi (Eds.), Qualitative and quantitative social research: Papers in honor of Paul E. Lazarsfeld (pp.51-64). New York, NY: Free Press.
Braun, Virginia & Clarke, Victoria (2006). Using thematic analysis in psychology. Qualitative Research in Psychology, 3(2), 77-101.
Büthe, Tim (2002). Taking temporality seriously: Modeling history and the use of narratives as evidence. American Political Science Review, 96(3), 481-493.
Chubin, Daryl E. & Connolly, Terence (1982). Research trails and science policies. In Norbert Elias, Herminio Martins & Richard Whitley (Eds.), Scientific establishments and hierarchies (pp.293-311). Dordrecht: Reidel.
Clandinin, D. Jean (2006). Narrative inquiry: A methodology for studying lived experience. Research Studies in Music Education, 27(1), 44-54.
Creswell, John W. (2013). Qualitative inquiry and research design: Choosing among five approaches. Thousand Oaks, CA: Sage.
Elster, Jon (1989). The cement of society. A study of social order. Cambridge: Cambridge University Press.
Falleti, Tulia G. & Lynch, Julia F. (2009). Context and causal mechanisms in political analysis. Comparative Political Studies, 42(9), 1143-1165.
George, Alexander L. (2019 [1979]). Case studies and theory development: The method of structured, focused comparison. In Dan Caldwell (Ed.), Alexander L. George: A pioneer in political and social sciences (pp.191-214). Cham: Springer International.
George, Alexander L. & McKeown, Timothy J. (1985). Case studies and theories of organizational decision making. In Lee S. Sproull & Patrick D. Larkey (Eds.), Advances in information processing in organizations. A research annual (pp.21-58). London: JAI Press.
Gläser, Jochen & Laudel, Grit (2010). Experteninterviews und qualitative Inhaltsanalyse als Instrumente rekonstruierender Untersuchungen (4th ed.). Wiesbaden: VS Verlag für Sozialwissenschaften.
Gläser, Jochen & Laudel, Grit (2013). Life with and without coding: Two methods for early-stage data analysis in qualitative research aiming at causal explanations. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 14(2), Art. 5, http://dx.doi.org/10.17169/fqs-14.2.1886 [Date of Access: June 27, 2019].
Gläser, Jochen & Laudel, Grit (2015a). A bibliometric reconstruction of research trails for qualitative investigations of scientific innovations. Historical Social Research / Historische Sozialforschung, 40(3), 299-330, https://doi.org/10.12759/hsr.40.2015.3.299-330 [Date of Access: June 27, 2019].
Gläser, Jochen & Laudel, Grit (2015b). The three careers of an academic. Discussion Paper, 35/2015, Center for Technology and Society, TU Berlin, https://www.tu-berlin.de/fileadmin/f27/PDFs/Discussion_Papers_neu/discussion_paper_Nr__35.pdf [Date of Access: June 27, 2019].
Goldthorpe, John H. (2001). Causation, statistics, and sociology. European Sociological Review, 17(1), 1-20.
Gorski, Philip S. (2004). The poverty of deductivism: A constructive realist model of sociological explanation. Sociological Methodology, 34(1), 1-33.
Greshoff, Rainer (2015). Worum geht es in der Mechanismendiskussion in den Sozialwissenschaften und welcher Konzepte bedarf es, um sozialmechanismische Erklärungen zu realisieren?. In Martin Endreß, Klaus Lichtblau & Stefan Moebius (Eds.), Zyklos 1: Jahrbuch für Theorie und Geschichte der Soziologie (pp.47-92). Wiesbaden: Springer VS.
Hackett, Edward J. (2005). Essential tensions: Identity, control, and risk in research. Social Studies of Science, 35(5), 787-826.
Hammersley, Martyn & Cooper, Barry (2012). Analytic induction versus qualitative comparative analysis. In Barry Cooper, Judith Glaesser, Roger Gomm & Martyn Hammersley (Eds.), Challenging the qualitative—quantitative divide: Explorations in case-focused causal analysis (pp.129-169). London: Continuum International.
Hedström, Peter & Ylikoski, Petri (2010). Causal mechanisms in the social sciences. Annual Review of Sociology, 36, 49-67.
Hsieh, Hsiu-Fang & Shannon, Sarah E. (2005). Three approaches to qualitative content analysis. Qualitative Health Research, 15(9), 1277-1288.
Jackson, Ronald L., Drummond, Darlene K. & Camara, Sakile (2007). What is qualitative research?. Qualitative Research Reports in Communication, 8(1), 21-28.
Janssen, Markus, Christoph Stamann, Yvonne Krug & Christina Negele (2017). Conference Report: Qualitative content analysis—and beyond?. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 18(2), Art. 7, http://dx.doi.org/10.17169/fqs-18.2.2812 [Date of Access: June 27, 2019].
Kelle, Udo (1997). Theory building in qualitative research and computer programs for the management of textual data. Sociological Research Online, 2(1), https://journals.sagepub.com/doi/10.5153/sro.86 [Date of Access: June 27, 2019].
Knorr-Cetina, Karin (1999). Epistemic cultures: How the sciences make knowledge. Cambridge, MA: Harvard University Press.
Kuckartz, Udo (2014). Qualitative text analysis: A guide to methods, practice and using software. London: Sage.
Laudel, Grit (2017). How do national career systems promote or hinder the emergence of new research lines?. Minerva, 55(3), 341-369.
Laudel, Grit & Bielick, Jana (2018). The emergence of individual research programmes in the early career phase of academics. Science, Technology, & Human Values, 43(6), 972-1010.
Laudel, Grit & Gläser, Jochen (2007). Interviewing scientists. Science, Technology & Innovation Studies, 3, 91-111, https://core.ac.uk/download/pdf/46909377.pdf [Date of Access: June 27, 2019].
Laudel, Grit & Gläser, Jochen (2008). From apprentice to colleague: the metamorphosis of early career researchers. Higher Education: The International Journal of Higher Education and Educational Planning, 55, 387-406.
Mahoney, James (2000). Strategies of causal inference in small-n analysis. Sociological Methods & Research, 28(4), 387-424.
Mahoney, James (2001). Beyond correlational analysis: Recent innovations in theory and method. Sociological Forum, 16(3), 575-593.
Maxwell, Joseph A. (2013). Qualitative research design: An interactive approach (3rd ed.). Thousand Oaks, CA: Sage.
Mayntz, Renate (2004). Mechanisms in the analysis of social macro-phenomena. Philosophy of the Social Sciences, 34(2), 237-259.
Mayntz, Renate (2009 [2002]). Kausale Rekonstruktion. Theoretische Aussagen im akteurzentrierten Institutionalismus. In Renate Mayntz (Ed.), Sozialwissenschaftliches Erklären: Probleme der Theoriebildung und Methodologie (pp.83-96). Frankfurt/M.: Campus.
Mayntz, Renate (2016). Process tracing, abstraction, and varieties of cognitive interest. New Political Economy, 21(5), 484-488.
Mayntz, Renate & Scharpf, Fritz W. (1995). Der Ansatz des akteurzentrierten Institutionalismus. In Renate Mayntz & Fritz W. Scharpf (Eds.), Gesellschaftliche Selbstregelung und politische Steuerung (pp.39-72). Frankfurt/M.: Campus.
Mayring, Philipp (2014). Qualitative content analysis: Theoretical foundation, basic procedures and software solution, http://www.ssoar.info/ssoar/handle/document/39517 [Date of Access: June 27, 2019].
Merton, Robert K. (1957). The role set: Problems in sociological theory. British Journal of Sociology, 18(2), 106-120.
Merton, Robert K. (1968). On sociological theories of the middle range. In Robert K. Merton (Ed.), Social theory and social structure (pp.39-72). London: The Free Press.
Meyer, Michael (2002). Between theory, methods, and politics: Positioning of the approaches to CDA. In Ruth Wodak & Michael Meyer (Eds.), Methods of critical discourse analysis (pp.14-31). London: Sage.
Miles, Matthew B.; Huberman, A. Michael & Saldaña, Johnny (2014). Qualitative data analysis: A methods sourcebook (3rd ed.). Thousand Oaks, CA: Sage.
Owen-Smith, Jason (2001). Managing laboratory work through skepticism: Processes of evaluation and control. American Sociological Review, 66(3), 427-452.
Patton, Michael Quinn (2014). Qualitative research and evaluation methods. Newbury Park, CA: Sage.
Ragin, Charles C. (1987). The comparative method. Moving beyond qualitative and quantitative strategies. Berkeley, CA: University of California Press.
Ragin, Charles C. (2000). Fuzzy-set social science. Chicago, IL: University of Chicago Press.
Rosenthal, Gabriele (2008). Interpretative Sozialforschung. Eine Einführung (2nd rev. ed.). Weinheim: Juventa.
Schreier, Margrit (2012). Qualitative content analysis in practice. London: Sage.
Sørensen, Aage B. (1998). Theoretical mechanisms and the empirical study of social processes. In Peter Hedström & Richard Swedberg (Eds.), Social mechanisms: An analytical approach to social theory (pp.238-266). Cambridge: Cambridge University Press.
Stamann, Christoph; Janssen, Markus & Schreier, Margrit (2016). Qualitative Inhaltsanalyse –Versuch einer Begriffsbestimmung und Systematisierung. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 17(3), Art. 16, http://dx.doi.org/10.17169/fqs-17.3.2581 [Date of Access: June 27, 2019].
Steel, Daniel (2004). Social mechanisms and causal inference. Philosophy of the Social Sciences, 34(1), 55-78.
Strauss, Anselm & Corbin, Juliet (1990). Basics of qualitative research. Grounded theory procedures and techniques. Newbury Park, CA: Sage.
Trampusch, Christine & Palier, Bruno (2016). Between X and Y: How process tracing contributes to opening the black box of causality. New Political Economy, 21(5), 437–454.
Weber, Max (2019 [1922]). Economy and society: A new translation (ed. and transl. by K. Tribe). Cambridge, MA: Harvard University Press.
Znaniecki, Florian (1934). The method of sociology. New York, NY: Rinehart & Company.
Dr. Jochen GLÄSER is professor for social studies of science and technology at Technical University Berlin. His research interests include the relationship between epistemic practices and social structures of scientific communities, qualitative methodology, and methods of science studies.
Contact:
Professor Dr. Jochen Gläser
Sozialwissenschaftliche Wissenschafts- und Technikforschung
Sekretariat HBS 7
TU Berlin
Hardenbergstr. 16-18
10623 Berlin, Germany
Tel.: +49 (0)30 314 24815
E-Mail: Jochen.Glaeser@tu-berlin.de
URL: https://www.researchgate.net/profile/Jochen_Glaser
Dr. Grit LAUDEL is a senior researcher at the Institute of Sociology, Technical University Berlin. Her research interests include the influence of institutions (e.g., funding, evaluations, academic careers) on the content of scientific research, the methodology and methods of qualitative research, and the methodology and methods of science studies.
Contact:
Dr. Grit Laudel
Institut für Soziologie
Sekretariat FH 9-1
TU Berlin
Fraunhoferstr. 33-36
10587 Berlin, Germany
Tel.: +49 (0)30 314 28871
E-Mail: grit.laudel@tu-berlin.de
URL: http://www.laudel.info/
Gläser, Jochen & Laudel, Grit (2019). The Discovery of Causal Mechanisms: Extractive Qualitative Content Analysis as a Tool for Process Tracing [76 paragraphs]. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 20(3), Art. 29, http://dx.doi.org/10.17169/fqs-20.3.3386.

Creative Commons Attribution 4.0 International License