Volume 21, No. 1, Art. 1 – Januar 2020
Qualitative Inhaltsanalyse in der literaturdidaktischen Rezeptionsforschung: über die Herausforderung, Verstehensprozesse zu verstehen
Mark-Oliver Carl & Friedemann Holder
Zusammenfassung: In diesem Beitrag werden Spezifika der mit der qualitativen Inhaltsanalyse vorgenommenen Leserezeptionsforschung dargestellt. Der Schwerpunkt liegt auf dem literarischen Lesen. In Analysen von Textrezeptionszeugnissen, die zu literaturdidaktischen Forschungszwecken vorgenommen werden, ergibt sich eine doppelt-hermeneutische Herausforderung: Ziel ist es zu verstehen, was Leser_innen in Texten verstehen. Für den Analyseprozess folgen daraus spezifische Anforderungen: Erstens muss der Umfang der Kontexteinheit geklärt werden. Hier sind differenzierte Antworten notwendig, weil sich der gegebene Kontext im Leseprozess ständig verändert. Zweitens erfordert das Forschungsinteresse eine bestimmte Art von Kategorien, die in der Literatur als formal bzw. analytisch bezeichnet werden. Eine weitere Differenzierung zwischen strikt formalen und theoriebasiert formalen Kategorien wird hier vorgeschlagen. Drittens muss geklärt werden, ob die rekonstruierten Leseaktivitäten Prozesse sind, oder ob sie auf zugrunde liegende Dispositionen schließen lassen. Diese Anforderungen werden diskutiert und mit Lösungsansätzen versehen.
Keywords: Literaturdidaktik; qualitative Inhaltsanalyse; doppelt-hermeneutische Perspektive; Textverstehen; Kontexteinheit; Kategorienarten
Inhaltsverzeichnis
1. Qualitative Inhaltsanalyse in literaturdidaktischen Studien zum Textverstehen
2. Die doppelt-hermeneutische Perspektive
3. Die Kontexteinheit in literaturdidaktischen Textverstehensstudien
3.1 Beispiel 1: Inferenzen beim lesebegleitenden Lauten Denken?
3.2 Beispiel 2: Strategien im Umgang mit konfligierenden Textinformationen
3.3 Beispiel 3: Vermutungen über unvertraute Darstellungen im Bilderbuchkinogespräch
4. Inhaltliche, formale, analytische oder theoretische Kategorien?
4.1 Differenzierungsvorschlag 1: "strikt formale" und "theoriegeleitete formale Kategorien"
4.2 Differenzierungsvorschlag 2: "prozessbezogene" und "dispositionsbezogene Kategorien"
5. Ausblick
1. Qualitative Inhaltsanalyse in literaturdidaktischen Studien zum Textverstehen
Seit dem disziplinübergreifenden Paradigmenwechsel im Gefolge des PISA-Schocks ist auch in der deutschsprachigen Literaturdidaktik eine "empirische Wende" (GOER 2014, S.26) zu beobachten. Neben recht frühen quantitativ angelegten Großprojekten (z.B. DICKHÄUSER, FREDERKING, MEYER & STANAT 2008) finden sich in den letzten Jahren zahlreiche explorative Rezeptionsstudien, in denen auf unterschiedliche qualitative Forschungsmethoden zurückgegriffen wird. Unter ihnen zählt die qualitative Inhaltsanalyse zu den meistgewählten (z.B. FÜHRER 2013; HEINS 2017; HOLDER 2019; ODAĞ 2007; PIEPER & STRUTZ 2018; SEYLER 2016; STOLLE 2017). [1]
Zugleich wird die adäquate Passung der Methode zum literaturdidaktischen Gegenstand als große Herausforderung gekennzeichnet (z.B. GROEBEN & RUSTEMEYER 2002; HEINS 2017). Doch worin besteht diese Herausforderung genau? Gibt es, jenseits einzelner Projekte und ihrer unterschiedlichen Fragestellungen, ein disziplinspezifisches Entwicklungsdesiderat der Literaturdidaktik bezüglich des qualitativ inhaltsanalytischen Methodeninventars für Rezeptionsstudien? [2]
In Studien, in denen (literarische) Textverstehensprozesse, -strategien oder -aktivitäten systematisch erfasst werden sollen, so die für diesen Beitrag maßgebliche Überlegung, besteht die zentrale Herausforderung darin, eine doppelt-hermeneutischen Perspektive zu bewältigen. Sie macht ein disziplinspezifisches Verständnis der Kontexteinheit und der Arten von Kategorien, die analytisch anvisiert werden, erforderlich, zu denen im Folgenden Systematisierungsansätze formuliert werden. [3]
Es wird zunächst erläutert, worin die doppelt-hermeneutische Perspektive qualitativer Inhaltsanalysen von Rezeptionszeugnissen im literaturdidaktischen Kontext besteht (Abschnitt 2). Anschließend werden mehrere Anleitungen zur Bestimmung von und zum Umgang mit Kontexteinheiten vorgestellt und mit einem Vorschlag für eine Spezifizierung für literaturdidaktische Rezeptionsstudien versehen, dessen Variation in konkreten Projekten anhand dreier Beispiele illustriert wird (Abschnitt 3). In Abschnitt 4 werden Vorschläge zur Differenzierung formaler Kategorientypen unterbreitet. [4]
2. Die doppelt-hermeneutische Perspektive
Qualitative Inhaltsanalyse kann grundsätzlich als hermeneutisch angelegte Methode angesehen werden (KUCKARTZ 2018). Bei Textverstehensstudien mithilfe qualitativer Inhaltsanalyse wird jedoch eine doppelt-hermeneutische Perspektive relevant. KUCKARTZ (2018) sieht in der hermeneutischen Herangehensweise einen konstituierenden Unterschied zwischen der qualitativen und der quantitativen Inhaltsanalyse: Nur wenige Aspekte kommunikativen, zumal sprachlichen Handelns lassen sich durch eine quantifizierende Analyse objektiv gegebener Oberflächenmerkmale (z.B. die Häufigkeit bestimmter Wörter, die durchschnittliche Satzlänge oder die Anzahl grafischer Elemente pro Seite) verstehen. Die Erschließung der pragmatischen Dimension von Texten, der Mitteilungsabsichten, der zugrunde liegenden Vorstellungen, Strategien und Wissensbestände und vieler weiterer Sinnebenen sprachlichen Handelns bedürfen eines interpretierenden Verstehens. Bei einem solchen hermeneutischen Zugriff wird versucht, die Bedeutung einzelner Zeichen und Zeichenkombinationen zur gesamten Äußerung und zu ihrem kommunikativen Kontext in Beziehung zu setzen. Dies erfordert allerdings zwangsläufig das Bilden von Hypothesen im Rückgriff auf das eigene Vorwissen und den Horizont der eigenen Vorstellungen. Eine objektiv zwingende Verifikation oder Falsifikation solcher Hypothesen ist gemeinhin unmöglich. Die Ergebnisse solcher Interpretationen können mit Blick auf ihre Subjektivität reflektiert und, so weit möglich, plausibilisiert werden; an ihrem subjektiven Status ändert das jedoch nichts. [5]
Dies gilt selbstverständlich auch für qualitativ inhaltsanalytische Studien, in denen das Textverstehensverhalten anderer Menschen (z.B. von Schüler_innen, Lehrpersonen, Expert_innen) untersucht wird. In diesen Fällen ist die hermeneutische Herausforderung jedoch eine doppelte. Denn in Textverstehensstudien versucht man zu verstehen, wie andere einen Text verstehen. [6]
Die (literarische) Textgrundlage ist ihrerseits mindestens ebenso interpretationsbedürftig wie die im Rahmen der jeweiligen Studie erhobenen Zeugnisse kommunikativen Handelns anderer im Umgang mit ihr – diesen Minimalkonsens teilen Vertreter_innen so unterschiedlicher Ansätze wie der psychoanalytischen, werkimmanenten, rezeptionsästhetischen, konstruktivistischen, (neo-)marxistischen, gender-theoretischen, interdiskursanalytischen, neohistoristischen, (neo-)intentionalistischen und kulturökologischen Literaturtheorien (für einen Überblick KÖPPE & WINKO 2013). [7]
Ob insbesondere Noviz_innen an literarischen Texten jedoch überhaupt Interpretationshandlungen vollführen, kann keineswegs vorausgesetzt werden – oft zeigen z.B. Laut-Denk-Protokolle vergebliche Bemühungen um ein Wort- und Satzverständnis (BRAAKSMA, JANSSEN & RIJLAARSDAM 2006; VAN DER MEULEN 2015). Inwiefern und auf welche Weise sie Texte interpretieren, wird in vielen literaturdidaktischen Textverstehensstudien untersucht. Das Erkenntnisinteresse gilt in diesen Fällen Größen (z.B. Textverstehensstrategien), deren Latenz etwa gegenüber den in soziologischen Studien oft gesuchten "Gesprächsthemen" noch einmal potenziert ist. Wie in letzteren gilt auch in literaturdidaktischen Textverstehensstudien das Interesse Denkstrukturen, d.h. Operationen von Individuen, mit denen sie die Welt wahrnehmen und zugleich hervorbringen. Dennoch gibt es einen wichtigen Unterschied: Mit der "Struktur des Denkens" meint der Soziologe Karl MANNHEIM (1980) etwas anderes als die Kognitionspsychologen Mark JOHNSON und George LAKOFF (2016). MANNHEIM zielt darauf, "soziales Handeln deutend [zu] verstehen und [...] ursächlich [zu] erklären" (1980, S.66); JOHNSON und LAKOFF (2016) geht es darum, die für das menschliche Denken typische erfahrungsbasierte Kategorienbildung und -erweiterung zu erforschen. Diese Auffassungen sind Ausdruck unterschiedlicher Fach- und Forschungsparadigmen, dem der Wissenssoziologie und dem der Kognitionspsychologie. In der Deutschdidaktik ist seit der Wende zum Kompetenzbegriff eine klare Orientierung an kognitionspsychologischen Konzepten zu erkennen. Sprachliche Kompetenzen sind – nach dem in der Deutschdidaktik geläufigen Kompetenzbegriff (GAILBERGER & HOLLE 2010) – nichts anderes als praktizierte Kognitionen. In einschlägigen Arbeiten wird dieser Zusammenhang hergestellt (z.B. TALMY 2000). Entsprechend liegt das Interesse der Deutschdidaktiker_innen im Bereich der sprachlichen Kognition und weniger im Feld der Wissenssoziologie. [8]
Ähnlich sind sich beide Blickrichtungen jedoch in der Lesart, der Daten unterzogen werden. Unterscheiden lässt sich bei der Datenlektüre die Ermittlung eines "objektiven Sinns", der die denotative Funktion des Gesagten beinhaltet und die Inhalte "mit den Augen der beteiligten Subjekte nachvollzieht" (GARZ 2007, S.225), von der Rekonstruktion eines tiefer liegenden Sinns, dessen Objektivation sich durch einen höheren Abstraktionsgrad auszeichnet und nicht der Zustimmung der Teilnehmer_innen bedarf (z.B. KRUSE 2014; MANNHEIM 1980). [9]
Ohne eine solche Rekonstruktion, die sich selten eindeutig am erhobenen Zeichenmaterial festmachen lässt, ist kaum zu klären, wie die Teilnehmer_innen einer Textverstehensstudie die Versuchsanordnung überhaupt auffassen. Ihr Umgang mit dem literarischen Text lässt sich nicht als schlichtes Befolgen oder Nichtbefolgen einer Versuchsanordnung beschreiben. Er ist daher als weitgehend offen und der Rekonstruktion durch die Forschenden bedürftig zu betrachten. [10]
Wer die hermeneutische Anstrengung literaturdidaktischer qualitativer Inhaltsanalysen von Textverstehenszeugnissen wagt, ist mit einer schwierigen Dialektik konfrontiert: Sowohl die Eigenschaften der Versuchsanordnung (insbesondere der Textgrundlage) als auch die auf sie gerichteten Verstehenshandlungen bedürfen einer Interpretation. Im letzten Fall gehen die Forscher_innen über das Erschließen des Gesagten und Gemeinten hinaus und zielen auf die den Deutungen zugrunde liegenden kognitiven Operationen. Um dieser doppelt-hermeneutischen Herausforderung zu begegnen, erscheinen uns zwei disziplinbezogene Spezifikationen des Methodeninventars der qualitativen Inhaltsanalyse geboten:
Das erhobene Zeichenmaterial lässt sich nur in der Zusammenschau mit der rezipierten Textgrundlage sinnvoll klassifizieren, wobei zu beachten bleibt, dass viele vorausgesetzte Merkmale der Textgrundlage und damit der möglichen Bezugnahmen von Rezipient_innen auf die Textgrundlage interpretativen Charakters sind. Dies erfordert, bei der Codierung des Zeichenmaterials im Rahmen einer literaturdidaktischen qualitativen Inhaltsanalyse der Kontexteinheit einen viel wichtigeren Stellenwert beizumessen, als dies in anderen Forschungszusammenhängen der Fall ist. In Abschnitt 3 wird deshalb anhand von Beispielen aus literaturdidaktischen qualitativen Inhaltsanalysen ausgeführt, unter welchen Umständen und auf welche Arten die Kontexteinheit beim Codieren von Zeichenmaterial im Hinblick auf eventuell zugrunde liegende Textverstehensprozesse zu berücksichtigen wäre.
Mit einer strukturell so radikal interpretationsbedürftigen Datengrundlage umzugehen, ist oft kaum möglich ohne Rückgriff auf sehr umfassende und spezifische Wissensbestände der Forscher_innen – vor allem Wissen um Modelle des (literarischen) Textverstehens. Hierin besteht im Falle literaturdidaktischer qualitativer Inhaltsanalysen die Ursache für die Notwendigkeit einer bestimmten Art der Kategorienbildung, die bei SCHREIER "formal-inhaltsanalytisch" (2014, §25), bei KUCKARTZ "analytisch" (2018, S.34), bei HSIEH und SHANNON "directed approach" (2005, S.1281) und bei SALDAÑA "provisional coding" (2016, S.120) heißt. Die Autor_innen entsprechender Methodenhandbücher widmen diesem Typus von Kategorien jedoch nur eine verhältnismäßig geringe Aufmerksamkeit. Unter diesen Oberbegriffen verbergen sich sehr unterschiedliche Möglichkeiten einer (partiell) theoriebasierten Kategorienbildung, die wir in Abschnitt 4 anhand einer Gegenüberstellung von soziologischen und literaturdidaktischen Beispielen ausdifferenzieren werden. [11]
3. Die Kontexteinheit in literaturdidaktischen Textverstehensstudien
In aktuellen Methodenhandbüchern zur qualitativen Inhaltsanalyse nehmen Ausführungen zur Kontexteinheit, ihrer Extension und Funktion, deutlich weniger Raum ein als etwa solche zur Analyse- oder gar zur Codiereinheit. Die äußerst knappen Definitionen und auch die Art der zur Veranschaulichung gewählten Beispiele enthalten unserer Meinung nach wenig hilfreiche Hinweise für die Bestimmung und Berücksichtigung von Kontexteinheiten in Textverstehensstudien. [12]
So legt KUCKARTZ (2018) ohne nähere Erläuterungen fest: "Die Kontexteinheit ist definiert als die größte Einheit, die hinzugezogen werden darf, um eine Codiereinheit zu verstehen und richtig zu kategorisieren" (S.44). SCHREIER (2012) bettet ihre ähnlich gelagerte Begriffsbestimmung ("the context unit is that portion of the surrounding material that you need in order to understand the meaning of a given unit of coding", S.133) immerhin in eine Problematisierung der dekontextualisierenden Effekte der Segmentierung der Analyseeinheit in Codiereinheiten ein. Dass die Kontexteinheit allerdings auch größer sein könnte als die Analyseeinheit, liegt eher außerhalb des Blickfelds und wird bei KUCKARTZ (2018) sogar ausdrücklich zum Sonderfall erklärt: "Normalerweise ist die Kontexteinheit nicht größer als die Analyseeinheit definiert, Sonderfälle können allerdings durchaus vorkommen" (S.44). Die Wahl der Beispiele, die solche knappen Begriffsbestimmungen erläutern sollen, entspricht diesen Vorüberlegungen. KRIPPENDORFF (2004) nennt den Satz als Kontexteinheit für die Kategorisierung einzelner Wörter, einige vorangehende Sätze als Kontexteinheit für anaphorische Wörter wie Pronomina, und "a paragraph or a whole speech" (S.101) als Beispiel einer eher großen Kontexteinheit zur Bestimmung, ob eine Codiereinheit als positive oder negative Bewertung einer politischen Position zu klassifizieren sei. [13]
SCHREIER (2012) und KUCKARTZ (2018) führen beide jeweils auch ein Beispiel an, in dem die Kontexteinheit größer als die Analyseeinheit ist – KUCKARTZ nennt vorherige Interviews in Panel-Studien als mögliche Ausnahme; SCHREIER betrachtet beispielsweise die Darstellungen von TV-Serien auf den Webseiten ihrer Sender als Kontexteinheit zur Kategorisierung von Figuren. [14]
Wie bereits SCHREIER (2014) feststellt, "spezifiziert und systematisiert Philipp MAYRING [...] [m]it seiner Explikation der Kontextanalyse [...] die Bestimmung der Kontexteinheit" (§39). MAYRINGs (2015) Modell der "Explikation (Kontextanalyse)" integriert zwar systematisch eine "weite Kontextanalyse, [die ...] nun auch Material [...] sammelt, das über den eigentlichen Text hinausgeht" (S.90). Allerdings finden Literaturdidaktiker_innen auch hier wenig passende Anleitungen für die Bestimmung von Kontexteinheiten in ihren Rezeptionsstudien, denn MAYRING begreift die Kontextanalyse vor allem dann als "interessant und wichtig [...], wenn der Sprecher davon [von lexikalisch-grammatischen Konventionen] abweicht, spezifische eigene Bedeutungen in Sprache hineinlegt oder sich unvollständig, unklar ausdrückt" (a.a.O.). Dies ist zwar in Rezeptionszeugnissen auch oft der Fall, doch die Notwendigkeit zur Berücksichtigung der gelesenen Textgrundlage als Kontexteinheit besteht auch dort, wo Rezipient_innen sich lexikalisch-grammatisch völlig konventionskonform ausdrücken. Auf sehr allgemeine Weise lässt sich dies aus MAYRINGs Interpretationsregeln für die "weite Kontextanalyse" ableiten:
"E 4.1: Überprüfe, ob zum Verfasser der Textstelle weiteres explizierendes Material zugänglich ist!
E 4.2: Ziehe Material über die Entstehungssituation des Textes zur Erklärung heran!
E 4.3: Überprüfe, ob aufgrund des eigenen allgemeinen Verstehenshintergrundes weiteres Material heranzuziehen ist!
E 4.4: Begründe die Relevanz, den Bezug des gesammelten Materials zur fraglichen Textstelle!" (S.94) [15]
Die von den Studienteilnehmer_innen rezipierte Textgrundlage zählt fraglos zur Entstehungssituation der Rezeptionsdaten. Doch solch weit gefasste Empfehlungen wie die MAYRINGs bieten Literaturdidaktiker_innen, die Datenmaterial zum Textverstehen erhoben haben und mithilfe der qualitativen Inhaltsanalyse auswerten möchten, zu wenige konkrete Hinweise, inwiefern der von ihren Teilnehmer_innen gelesene literarische Text als Kontexteinheit für die jeweiligen Codiereinheiten zu betrachten ist. [16]
Dass eine Eingrenzung der Kontexteinheit prinzipiell sinnvoll ist – nicht nur aus forschungsökonomischer Sicht, sondern auch, weil sehr weit gesteckte Kontexte die Reliabilität der Analyse gefährden können "because different individuals approach a novel differently, and the analyst would have to keep the whole in mind when making judgments" (KRIPPENDORFF 2004, S.102) – steht außer Frage. Doch KRIPPENDORFFs Maxime für den optimalen Umfang einer Kontexteinheit ist zwar ob ihrer Allgemeinheit kaum zu widersprechen, allerdings ist sie für den spezifischen Kontext von Textverstehensstudien wenig hilfreich: "The best content analyses define their context units as large as is meaningful (adding to their validity) and as small as is feasible (adding to their reliability)" (a.a.O.). [17]
Für literaturdidaktische qualitative Inhaltsanalysen von Textverstehenszeugnissen wollen wir diese allgemeine Maxime in Gestalt einer Erweiterung der oben genannten Kurzdefinitionen wie folgt konkretisieren: Die Kontexteinheit ist die Einheit, die hinzuziehen ist, um eine Codiereinheit zu verstehen und zu kategorisieren. Sie umfasst – neben Teilen oder der Gesamtheit der jeweiligen Analyseeinheit – stets auch Teile oder die Gesamtheit des von den Studienteilnehmer_innen rezipierten Textes. [18]
Welche Teile der (literarischen) Textgrundlage jeweils zur Kontexteinheit zu rechnen sind, lässt sich naturgemäß nicht für alle Textverstehensstudien allgemeingültig beantworten. Mit den folgenden Beispielen sollen einige Varianten der Interpretationsrelevanz bestimmter Segmente der von den Teilnehmer_innen gelesenen Textgrundlage für bestimmte Codierungsfragen veranschaulicht werden. Es handelt sich dabei nicht um einen abgeschlossenen Katalog von Möglichkeiten der Bestimmung von Kontexteinheiten für Textverstehensstudien. [19]
3.1 Beispiel 1: Inferenzen beim lesebegleitenden Lauten Denken?
In einer Reihe deutschsprachiger wie auch internationaler Textverstehensstudien wird mit qualitativ inhaltsanalytischen Mitteln in Laut-Denk-Protokollen (DANNECKER 2016; PRESSLEY & AFFLERBACH 1995) (unter anderem) nach Inferenzprozessen gesucht, die beim Lesen der betreffenden literarischen Texte stattfinden (GOLDMAN & McCARTHY 2015; PESKIN 1998, 2007). Inferenzprozesse sind dabei definiert als Schlussfolgerungen aus dem Vorwissensbestand der Rezipient_innen, mit denen die mentale Repräsentation des rezipierten Textes angereichert wird (CONSTEN & SCHWARZ-FRIESEL 2014). Ob in einer Codiereinheit innerhalb eines Laut-Denk-Protokolls Hinweise auf ablaufende Inferenzprozesse zu finden sind, lässt sich nur im Abgleich mit dem gelesenen Text beurteilen – so zum Beispiel in der folgenden Codiereinheit aus einem Laut-Denk-Protokoll zu einem Ausschnitt aus Enid BLYTONs Abenteuerroman "Fünf Freunde auf geheimnisvoller Spur", das in CARLs aktuellem Habilitationsvorhaben unter anderem auf die jeweils verbalisierten mentalen Textrepräsentationsebenen untersucht werden soll, wofür die Frage nach Inferenzprozessen entscheidend ist:
"dann isch da noch n hund dabei" (CARL i.V.).1) [20]
Unerlässlicher Bestandteil der Kontexteinheit, um die Frage zu klären, ob es sich hier um eine Inferenz handelt, ist zunächst einmal der Satz, den die Teilnehmerin an der Studie während oder kurz vor ihrer Äußerung gelesen hat: "So stiegen die vier zum Strand hinab, hinter ihnen her sprang Tim und wedelte wie wild mit dem Schwanz" (BLYTON 1954 [1944], S.15). Stünde an dieser Stelle "[...] sprang Tim, der Hund, und wedelte [...]", so hätte eine Inferenz auf Grundlage dieser Kontexteinheit bereits ausgeschlossen werden können. Da dies nicht der Fall ist, muss auch die gesamte bis zu diesem Zeitpunkt gelesene Textgrundlage zur Kontexteinheit gerechnet werden: Würde dort an irgendeiner Stelle ein Hund oder eine Hunderasse erwähnt, so wäre die Codiereinheit als referenzidentitätskonstatierende Paraphrase2) zu kategorisieren. Fehlt eine solche explizite Information im Text, erscheint es als vertretbar, die Codiereinheit als Beispiel für einen Inferenzprozess zu kategorisieren, der sich etwa so beschreiben ließe: Mit Eigennamen bedachte Wesen, die mit dem Schwanz wedeln und um Menschen herumspringen, sind mit hoher Wahrscheinlichkeit Hunde. [21]
Allgemeingültigkeit und Gewissheit kann eine solche Entscheidung nicht immer erlangen, da die Frage, welche Informationen die Textbasis beinhaltet und welche Inferenzen nicht mehr als "minimal" oder "zwingend", sondern als "echte Inferenzen" gelten sollen, umstritten ist (SINGER 2007) – auch hier haben wir es wieder mit der doppelt-hermeneutischen Herausforderung zu tun. Doch lässt sich zumindest festhalten, dass für die Frage, ob in einer Codiereinheit eines lesebegleitenden Laut-Denk-Protokolls ein Inferenzprozess vorliegt, der gesamte bis zu diesem Zeitpunkt gelesene Abschnitt – und nur dieser – zur Kontexteinheit zu rechnen ist, weil er alleine Aufschluss gibt, ob Studienteilnehmer_innen eine Information dem Text entnehmen konnten (dann kann keine Inferenz vorliegen) oder nicht (dann muss eine Inferenz vorliegen). [22]
3.2 Beispiel 2: Strategien im Umgang mit konfligierenden Textinformationen
Eine andere Frage, die zuletzt in zahlreichen qualitativ empirischen Textverstehensstudien bearbeitet wurde, ist, welche Strategien Lesende im Umgang mit konfligierenden Textinformationen verfolgen – das heißt: auf welche Leseverhaltensmuster sie zurückgreifen, wenn im Text Informationen auftauchen, die sich nur bedingt in die Kohärenz der bisher aufgebauten mentalen Repräsentation des Textes integrieren lassen. STARK (2017) listet die Strategien des Nicht-Aufgreifens der konfligierenden Textinformation, der begründeten Zurückweisung ihrer Konsistenz, Plausibilität oder Validität, ihrer Integration durch Korrektur des bisherigen mentalen Modells, ihrer Integration durch zusätzliche elaborative Prozesse oder des Aufschubs der Kohärenzetablierung auf. Wie umfassend dieses Strategierepertoire bei Rezipient_innen ist und wie angemessen es auf einen Text angewandt wird, wird als konstitutiv sowohl für wissenschaftsspezifische Aspekte ihrer Lesekompetenz (BROMME & STADTLER 2014; BROMME, SCHARRER, SKODZIK & STADTLER 2014) als auch für Momente literarästhetischer Erfahrung (CARL 2018; LESSING-SATTARI & WIESER 2016) erachtet. [23]
Der Zuschnitt der Kontexteinheit, die hinzuzuziehen ist, um einzuschätzen, ob eine – und wenn ja, welche – Rezeptionsstrategie im Umgang mit konfligierenden Textinformationen in einer Codiereinheit vorliegt, hängt von der Art der analysierten Daten ab. Handelt es sich, wie bei CARL (2018), LESSING-SATTARI und WIESER (2016) oder STARK (2017), um Laut-Denk-Protokolle, so ähnelt der Umfang der Kontexteinheit in vielen – aber nicht allen – Fällen dem in Beispiel 1: Hinzuzuziehen ist der bis zu diesem Zeitpunkt gelesene Text, nicht jedoch der hierauf folgende.3) Werden Plenums- oder Gruppengespräche oder Interviews, die im Anschluss an die Textlektüre erfolgen, analysiert, so ist jedoch potenziell der gesamte Ausgangstext zur Kontexteinheit zu rechnen. Die Art des Rückgriffs auf die Kontexteinheit lässt sich hier deutlich von derjenigen im ersten Beispiel unterscheiden. In einigen Fällen werden Codier- und Kontexteinheit auf eine viel stärker interpretative Weise in Beziehung zueinander gesetzt. Im ersten Beispiel musste die Kontexteinheit nur auf lokale Propositionen hin abgesucht werden, die den Studienteilnehmer_innen die jeweils wichtige Information liefern könnten. Wird jedoch auf den strategischen Umgang mit konfligierenden Textinformationen gezielt, müssen Forscher_innen ihre eigenen satzübergreifenden Kohärenzkonstruktionen mit jenen ihrer Teilnehmer_innen abgleichen. [24]
Dies lässt sich gut an zwei Beispielen von bereits durch STARK (2017) kontextualisierten Datenauszügen zeigen – STARK schickt den Lauten Gedanken des Studienteilnehmers Timur jeweils die gerade von Timur gelesene Textstelle voran. Die Äußerungen Timurs, die von STARK durch Zitate aus der gelesenen Textgrundlage voneinander getrennt wurden, seien Codiereinheit A, B und C:
"Text4): Dieser Krach musste kommen, weiß Burghausen. Ein Vierteljahr Bitten und Argumente, und der Junge kommt aus den Ferien zurück wie ein Penner. Irgendwann ist Schluss, weiß Burghausen, man macht sich ja lächerlich.
Timur: (A) Der disst den ... Ah, hab erst gedacht, Burghausen ist ne Stadt, aber das ist ein Mann. Herr Burghausen. Vielleicht sein Chef. Der findet den jedenfall wie ... wie ein Penner.
Text: "Ich hab dir klipp und klar gesagt: So gehst du nicht in die Schule! Morgen fängt der Unterricht wieder an, und wie siehst du aus?" Burghausen hat die Stimme gehoben, das ist Kommandoton, begreift er, er hat ihn immer vermeiden wollen, aber so was darf er sich nicht bieten lassen, muss ein Exempel statuieren – welches?
Timur: (B) Jetzt sieht man, das ist nicht sein Chef, sondern wahrscheinlich sein Lehrer. Sagt ihm, er soll vernünftig in die Schule kommen. Soll so Respekt bringen oder so. Nicht so rumlaufen.
[...]
Text: Burghausen: "Also, bevor du zur Oma fährst, kommt die Wolle runter!" Horst war zu Ende mit seinem Kräuterquark, ging in sein Zimmer.
Timur: (C) Jetzt wieder der Lehrer. Der sitzt auch mit am Tisch. Die reden alle auf ihn ein" (S.132f.). [25]
Wie bereits diskutiert, muss für jede dieser Codiereinheiten nicht nur die jeweils vorangestellte Textstelle, sondern der gesamte bis dahin gelesene Text als Kontexteinheit betrachtet werden, um zu entscheiden, ob und wenn ja welche Strategien im Umgang mit konfligierenden Textinformationen zu beobachten sind. Wie interpretativ dieser Rekurs auf die Kontexteinheit ist, variiert von Fall zu Fall – beziehungsweise verschärft sich die Deutungsbedürftigkeit im Verlauf des Protokolls zunehmend. [26]
Codiereinheit A lässt sich bereits ohne Rückgriff auf die Kontexteinheit eindeutig STARKs Kategorie Integration konfligierender Informationen durch Korrektur des mentalen Modells zuordnen, da Timur selbst explizit diese Korrektur thematisiert ("Ah, hab erst gedacht, Burghausen ist ne Stadt, aber das ist ein Mann. Herr Burghausen.") [27]
Codiereinheit B ist bereits weniger eindeutig. Dass irgendeine Integration konfligierender Informationen vorliegt, lässt sich bereits am Wort "Jetzt" und an der Gegenüberstellung "nicht sein Chef, sondern wahrscheinlich sein Lehrer" ablesen, und durch einen Abgleich mit Codiereinheit A ("Vielleicht sein Chef") als Kontexteinheit lässt sich diesbezüglich jeder Zweifel ausräumen. Doch wurde die konfligierende Information dem Text entnommen, sodass man in STARKs Sinne von einer Korrektur des mentalen Modells durch Integration einer Textinformation sprechen muss – oder liegt ein elaborativer Prozess vor? Timurs Äußerung ("sieht man") deutet Ersteres an – doch kann dies im Sinne von STARKs Erkenntnisinteresse nicht ausschlaggebend sein, weil Studienteilnehmer_innen sich der nicht vom Text gedeckten Natur elaborativer Prozesse meist nicht bewusst sein dürften. In der Tat deutet STARK diese Äußerung als elaborativen Prozess – eine Einschätzung, bei der er sich auf seine Interpretation der Kurzgeschichte von LOEST (1979) stützt. In der Terminologie der qualitativen Inhaltsanalyse ausgedrückt: STARK greift auf den bis dahin von Timur gelesenen Text als Kontexteinheit zurück, und weil er diesen Text – wahrscheinlich vor allem die Passage: "Morgen fängt der Unterricht an" – anders als Timur so versteht, dass Burghausen nicht der Lehrer des Jungen sein kann, sondern dessen Vater ist, kategorisiert er Timurs Rezeptionshandlung nicht als Korrektur des mentalen Modells durch Integration von Textinformationen. STARKs Verständnis des Textes ist sicher weitaus plausibler als Timurs, doch um diese Frage mit einiger Gewissheit entscheiden zu können, reicht kein kurzer Blick auf den bisher gelesenen Textabschnitt, sondern beide konkurrierende Modellierungen der Situation sind mindestens durch einen eingehenden Abgleich mit dem gesamten Text gegeneinander abzuwägen. Während die Deutung, dass Burghausen definitiv der Lehrer des Jungen sei, sicher wenig plausibel ist, ließe sich allerdings mit einigem Recht die These aufstellen, dass LOEST hier eine eindeutige Identifikation nicht leicht gemacht bzw. Burghausens Identität mit einem Rest von Unbestimmtheit versehen hat, womit die Kategorisierung von Codiereinheit B noch schwerer fiele. [28]
Wie man sich im Falle von Codiereinheit B entschieden hat, dürfte auch ausschlaggebend für den Umgang mit Codiereinheit C sein. Wenn man LOESTs Erzählung als Kontexteinheit so interpretiert hat, dass Codiereinheit B nicht als Integration einer Textinformation gelten kann, dann lässt sich Timurs folgende Aussage: "Jetzt wieder der Lehrer. Der sitzt auch mit am Tisch" als elaborativer Prozess kategorisieren: Timur bleibt bei seinem Missverständnis, dass Burghausen der Lehrer, nicht der Vater des Jungen sei, und wenn in LOESTs Erzählung nun abwechselnd vom Vater des Jungen und von Burghausen die Rede ist, modelliert Timur mental die Situation deshalb so, dass der Junge nicht zwei (Vater und Mutter), sondern drei (Vater, Mutter und Lehrer Burghausen) – und später gar vier Personen (Vater, Mutter, Lehrer Burghausen und dessen Frau) gegenüber steht. Für diese Kategorisierung von Codiereinheit C muss nicht nur auf LOESTs Erzählung als große und deutungsbedürftige Kontexteinheit zurückgegriffen werden – innerhalb derer der Fokus leicht auf die gerade gelesene Textstelle verschoben wurde –, sondern auch das bisherige Laut-Denk-Protokoll Timurs als Kontexteinheit einbezogen werden. Nur so lässt sich mit hinreichender – wenn auch nicht absoluter – Gewissheit davon sprechen, dass es sich in Codiereinheit C um einen elaborativen Prozess und nicht etwa um die Integration konfligierender Textinformationen handelt. [29]
Im Fall von Studien, in denen mithilfe qualitativer Inhaltsanalyse nach Strategien im Umgang mit konfligierenden Textinformationen gesucht wird, hängt es also von der Art des erhobenen Datenmaterials ab, wie groß die Kontexteinheit sein sollte. Handelt es sich um leseprozessbegleitende Verbalisierungen (z.B. Laut-Denk-Protokolle), so kann maximal der bis zu diesem Zeitpunkt gelesene Text zur Kontexteinheit gerechnet werden. Handelt es sich um Verbaldaten aus Anschlusskommunikation, so kann maximal der gesamte gelesene Text zur Kontexteinheit gerechnet werden, um entscheiden zu können, ob bzw. welche Strategien im Umgang mit konfligierenden Textinformationen in einer Codiereinheit vorliegen. [30]
3.3 Beispiel 3: Vermutungen über unvertraute Darstellungen im Bilderbuchkinogespräch
Kontexteinheiten von ganz anderer Art und anderem Umfang sind hingegen empfehlenswert, wenn das auf Textverstehensprozesse hin zu analysierende Datenmaterial etwa ein literarisches Gespräch mit Kindern über ein Bilderbuch (von HOFFMANN [2013, S.38] "Bilderbuchkinogespräch" genannt) ist, und der Umgang der Kinder mit nicht schematisch verarbeitbaren Bildausschnitten analysiert werden soll. Die kindliche Rezeption von Bilderbüchern mit fantastischen, unvertrauten und irritierenden Gestalten wird in einigen Rezeptionsstudien aus jüngster Zeit beforscht (RIST 2018; SCHERER, SCHRÖDER & VOLZ 2014). Auch im Fall der folgenden Codiereinheit aus RIST (2018) lässt sich nur unter Berücksichtigung des betrachteten Bilderbuchs entscheiden, ob die Studienteilnehmerin Eline angesichts eines fehlenden Gestalt-Schemas eine Vermutung äußert:
"Eline: Da ist ein rot/ (.) rotes (.) Brief irgendwie" (o.P.).5) [31]
Die Modalpartikel "irgendwie" kann man zwar als Hinweis auf Elines Unsicherheit verstehen – worauf sich diese bezieht und woher sie rührt, lässt sich jedoch schnell klären, wenn man Elines Blick ins Bilderbuch (BECKER 2015) folgt:
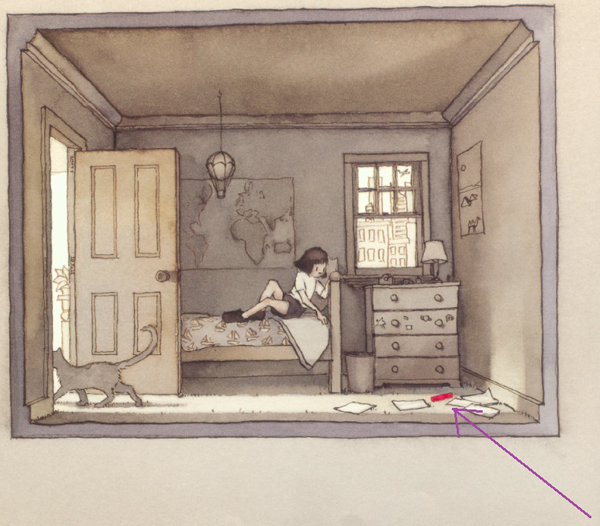
Abbildung 1: Bild aus "Die Reise" von Aaron BECKER (2015, S.5); der eingefügte Pfeil zeigt, worauf sich Eline im Gespräch
bezieht.6) [32]
Auf der Buchseite, die Eline ansieht, hat lediglich das in Abbildung 1 angezeigte Objekt eine rote Farbe. Ihre Äußerung kann nur darauf bezogen werden. Worum es sich genau handelt, dürfte auch für die meisten erwachsenen Betrachtenden, die noch nicht weitergeblättert haben, unklar sein. Als Kontexteinheit zur Klärung, dass Eline in der Codiereinheit tatsächlich eine Vermutung hinsichtlich einer unvertrauten Gestalt äußert, genügt möglicherweise bereits das rechte untere Bildviertel, in jedem Fall aber die gesamte gerade betrachtete Buchseite. Eine Ausweitung der Kontexteinheit über die betrachtete Seite hinaus wäre an dieser Stelle nutzlos. Wenn man mit einer Untersuchungsanordnung also auf Aspekte der Wahrnehmung fokussiert und aus den erhobenen Daten oder der Beschreibung der Untersuchung ableiten will, welche Objekte Studienteilnehmer_innen perzipieren können, bevor oder während sie sich äußern, kann von kleinen Kontexteinheiten ausgegangen werden. [33]
An diesen drei Beispielen wird ersichtlich, dass in Rezeptionsstudien immer Teile der rezipierten Textgrundlage als Kontexteinheit zu berücksichtigen sind. Welche Elemente dies sind und wie solche Kontexteinheiten in eine deutende Beziehung zur Codiereinheit zu bringen sind, muss jeweils reflektiert mit Blick auf das eigene Erkenntnisinteresse, Kategoriensystem und die Beschaffenheit der zugrunde gelegten Texte unterschiedlich bestimmt werden. [34]
4. Inhaltliche, formale, analytische oder theoretische Kategorien?
In Rezeptionsstudien sind Deutschdidaktiker_innen auch mit spezifischen Erfordernissen hinsichtlich der Art der zu verwendenden Kategorien konfrontiert, für die sie in den allgemeinen Verfahrensanleitungen zur qualitativen Inhaltsanalyse nur wenig Hilfestellung finden. Wie bei der Diskussion der doppelt-hermeneutischen Herausforderung bereits angedeutet, resultiert diese Spezifik einerseits aus dem Kontrast zwischen einer wörtlichen und einer reflexiven bzw. analytischen Lesart der Daten, andererseits aus den unterschiedlichen wissenschaftlichen Diskursen, in denen sich bspw. die Soziologie und die Deutschdidaktik bewegen. Für die qualitative Inhaltsanalyse sind neben den hier uninteressanten evaluativen, natürlichen und Fakten-Kategorien (KUCKARTZ 2018) inhaltliche und formale (SCHREIER 2014) bzw. thematische, analytische und formale Kategorien (KUCKARTZ 2018) vorgesehen, wobei ein deutlicher Schwerpunkt auf den inhaltlichen bzw. thematischen Kategorien zu erkennen ist. So sind auch die von KUCKARTZ vorgeschlagenen analytischen Kategorien zwar Theorie-geleitet, nehmen jedoch ihren Ausgang im thematischen Bereich. [35]
Tatsächlich ist es ein am Alltagsverständnis orientierter Themenbegriff, mit dem bspw. in soziologischen Studien oft gearbeitet wird, wenn es um die Erfassung der Denotate der Propositionen und ihrer Beziehungen geht, die sich innerhalb einer Äußerung bzw. eines Datums ausmachen lassen. Die Bezüge zu textlinguistischen Thema-Konzepten (z.B. VAN DIJK 1980) und zur klassischen Textinterpretation sind deutlich. In der qualitativen Inhaltsanalyse werden auf der Basis einer wörtlichen Lesart u.a. Kategorien gebildet, die Index-Charakter haben und den thematischen Kategorien zuzuordnen sind (KUCKARTZ 2018). So wird in den Lehrbuchbeispielen zur qualitativen Inhaltsanalyse aus den Gesprächsdaten in der Regel auf identische übergeordnete Themen geschlossen, z.B. auf die Einschätzung großer Weltprobleme (a.a.O.) oder auf den Umgang mit Arbeitslosigkeit bei Lehrer_innen (MAYRING 2015). In beiden Fällen können aus den unterschiedlichen thematischen Schwerpunkten, die in den Gesprächen ausgemacht werden, direkt Kategorien entwickelt werden. In der Studie von KUCKARTZ (2018, S.107) wird in dem gegebenen Zusammenhang z.B. über die "Umwelt" gesprochen (Kategorie 1), außerdem über "konflikthaltige Auseinandersetzungen" (Kategorie 2), "Krankheit" (Kategorie 4) und eine Reihe weiterer Themen. Die Gesprächsinhalte lassen sich hier ganz unmittelbar vergleichen und führen direkt zu unterschiedlichen thematischen Kategorien. In vielen Studien werden auf dieser Grundlage Sekundäranalysen vorgenommen, in denen dann die Sicht der Studienteilnehmer_innen erheblich überstiegen wird. [36]
In Rezeptionsstudien hingegen sind die beschriebenen thematischen Kategorien auch auf der Ebene der Primäranalyse nur selten sinnvoll. Selbst dort, wo sie zum Einsatz kommen, resultieren aus den Erkenntnisinteressen, die literaturdidaktischen Rezeptionsstudien zugrunde liegen, Anforderungen an die Kategorienbildung, die weit von den Beispielen entfernt sind, die bei KUCKARTZ (2018) und MAYRING (2015) genannt werden. Die Rezeptionsdaten, die hier analysiert werden, entstehen auf der Grundlage unterschiedlicher Primärtexte. Eine thematische Überschneidung kann sich daher nicht einstellen. Auch das Forschungsinteresse richtet sich nicht auf die Themen, die in den Texten entfaltet werden, sondern auf Merkmale der Studienteilnehmer_innen: Untersucht wird, welche Textverarbeitungsaktivitäten die einzelnen Äußerungen erkennen lassen, welche Dispositionen ihnen zugrunde liegen und welche sprachlich manifesten Details damit einhergehen. Es geht also um sprachliche Kognition in einem kognitionspsychologischen Sinne. Sie zu erfassen, ist bereits bei der Kategorienbildung das Ziel. Hier ist zu klären, welchen Arten von Kategorien solche Kategorienbildungen innerhalb der qualitativen Inhaltsanalyse zuzuordnen sind. [37]
4.1 Differenzierungsvorschlag 1: "strikt formale" und "theoriegeleitete formale Kategorien"
Wie lassen sich solche Phänomene kategorial fassen? Einen Ansatz bieten SCHREIERs "formale Kategorien" (2012). Was damit gemeint ist und weshalb diese für literaturdidaktische Rezeptionsstudien einen hilfreichen Rahmen bieten können, sei exemplarisch an Tanja STILLERs (2017) Studie zu literarästhetischen Verstehenskompetenzen von Viertklässler_innen verdeutlicht. STILLER geht von vorab etablierten Bereichen literarischen Verstehens aus und codiert vor diesem Hintergrund das folgende Datum mit der Kategorie "Globale Kohärenz herstellen":
"Es ist ein Gedicht und es geht um den Wind und um den Sturm" (S.112). [38]
Es ist offensichtlich, dass in der vorliegenden Äußerung nicht von Kohärenz die Rede ist. Vielmehr setzt eine solche Kategorisierung die Rekonstruktion eines spezifischen Aspekts des hier beobachteten Leseprozesses voraus. Die damit korrespondierende Leseaktivität besteht aus analytischer Perspektive darin, für die einzelnen Propositionen des zugrunde liegenden Textes übergeordnete Gesichtspunkte zu finden und so globale Kohärenz herzustellen. Was den sprachlich manifesten Bereich angeht, so ließe sich hier beobachten, dass die Teilnehmerin an der Studie das übergeordnete Thema des Gedichts mit "es geht hier um" einleitet. In der Zusammenschau mit anderen solchen Äußerungen ließe sich der Zusammenhang zwischen dem Auffinden globaler Kohärenz und der Phrase "es geht um" beschreiben (STILLER selbst geht darauf nicht ein). [39]
SCHREIER (1997, 2014) hat für solche Fälle eine eigene Variante qualitativer Inhaltsanalyse entwickelt, die formale qualitative Inhaltsanalyse. Sie unterscheidet zwischen eher induktiv und eher deduktiv gewonnenen formalen Kategorien. Ihr Beispiel für vorwiegend induktiv gewonnene Kategorien stammt aus ihrer Studie zum unintegren Argumentieren (1997), in der sie in Streitgesprächen zwischen Eltern und Kindern manipulative Äußerungen von Erwachsenen analysiert: Neben Kategorien, die sich auf sprachlich-linguistische Indikatoren wie "Pausen", "Hesitationsphänomene" und "Selbstkorrekturen" beziehen, stehen solche, die unintegre argumentative Muster beinhalten, beispielsweise "Wechsel auf die Metaebene" oder "wiederholtes Ausweichen" (2014, S.26). Entscheidend ist, dass die Kategorien aus dem Datenmaterial und nicht anhand theoretischer Vorannahmen gebildet wurden. [40]
SCHREIERs Beispiel für eine stärker theoriegeleitete deduktive Erstellung solcher Kategorien stammt ebenfalls aus dieser Studie. Um unterschiedliche Arten argumentativer Äußerungen zu kategorisieren, greift sie auf TOULMINs (1958) Argumentationsschema zurück. TOULMIN unterscheidet zwischen Daten, Qualifikatoren, Konklusionen, Rechtfertigungen, Stützungen und Ausnahmebedingungen. In SCHREIERs inhaltsanalytischem Kategoriensystem werden diese Äußerungstypen als Unterkategorien der Oberkategorie "Arten argumentativer Äußerungen" verwendet (1997, 2014). Ihr deduktiver Charakter liegt auf der Hand. [41]
Betrachtet man die verschiedenen Identifikationsverfahren, die bei derart unterschiedlichen Phänomenen erforderlich sind, liegt eine weitere Differenzierung nahe, die quer steht zu SCHREIERs Unterscheidung zwischen induktiven und deduktiven formal-inhaltsanalytischen Kategorien: SCHREIERs "Hesitationen" und "Pausen" und TOULMINs "Qualifikatoren" sind unmittelbar auf der Textoberfläche als formale Phänomene erkennbar. Für die Identifikation von argumentativen Mustern wie "Wechsel auf die Metaebene" sowie für die Erkennung von TOULMINs argumentativen Strukturelementen finden sich hingegen weniger Indizien an der Textoberfläche. Jede Codierentscheidung setzt im Falle solcher Kategorien eine theoriegeleitete Interpretation der Daten voraus. Im vorliegenden Kontext erscheint es uns daher angebracht, zwischen strikt formalen und theoriegeleitet formalen Kategorien zu unterscheiden. [42]
KUCKARTZ (2018) deckt diesen Bereich mit zwei unterschiedlichen Kategorienarten ab: Neben formalen Kategorien, mit denen "Daten und Informationen über die zu analysierende Einheit" (S.35) codiert werden können, sieht er analytische Kategorien vor, die "Resultat der intensiven Auseinandersetzung der Forscherin oder des Forschers mit dem Datenmaterial" (S.34) sind. "[D]ie Kategorie entfernt sich von der Beschreibung, wie sie etwa mittels thematischer Kategorien erfolgt" (a.a.O.). Bei diesem Kategorientyp lassen sich zwei unterschiedliche Ausprägungen ausmachen. Die erste zeichnet sich dadurch aus, dass datennahe Analysekategorien induktiv zusammengefasst und so auf einem höheren Abstraktionsniveau verdichtet werden. Ihre Bildung hat bereits den Charakter einer Sekundäranalyse. KUCKARTZ' Beispiel bezieht sich auf das bereits zitierte Forschungsprojekt zum Umweltverhalten: Die Analyse der thematischen Kategorie "Umweltverhalten" und ihre Dimensionen "Mobilitätsverhalten", "Energieverhalten" etc. habe die Forscher_innen zu der Erkenntnis geführt, dass die Studienteilnehmer_innen eigentlich über Kosten und Nutzen bestimmter Verhaltensweisen sprachen; die Forscher_innen definierten so die analytische Kategorie "Kosten-Nutzen-Kalkül" (a.a.O.). Die zweite Ausprägung des analytischen Kategorientyps hat ein ebenso hohes Abstraktionsniveau, wird jedoch deduktiv gewonnen: "Werden inhaltsanalytische Kategorien in direkter Verbindung zu einer Theorie entwickelt, können sie auch als theoretische Kategorien bezeichnet werden" (a.a.O.). Es ist die zweite Ausprägung, die für den vorliegenden Zusammenhang interessant wäre. Allerdings führt KUCKARTZ diesen Kategorientyp nicht weiter aus. Seine Beispiele zur Kategorienbildung und zur Durchführung der Analyse beziehen sich lediglich auf jenen Aspekt analytischer Kategorien, in denen thematische Kategorien analytisch verdichtet werden. Seine "theoretischen Kategorien" finden bei der Beschreibung der Analyseschritte seiner Basismethoden keine Berücksichtigung. [43]
Jener Teil von SCHREIERs formalen Kategorien, die sich auf Manifestationen auf der sprachlichen Oberfläche beziehen und die formalen Kategorien KUCKARTZ' lassen sich leicht zur Deckung bringen: Beide verhandeln in diesem Bereich Phänomene, die auf der Oberfläche der Daten sichtbar sind. Darüber hinaus zielt SCHREIER mit formalen Kategorien auf Phänomene, denen KUCKARTZ mit dem Spezialfall der theoretischen Kategorien begegnet, ohne diese jedoch soweit auszuführen, dass eine Analyse handhabbar wäre. Im hier vorliegenden Zusammenhang erscheint es uns naheliegend, SCHREIERs formalen Kategorientyp anhand von KUCKARTZ' Unterscheidungen weiter auszudifferenzieren.7) Entsprechend wäre zu unterscheiden zwischen
strikt formalen Kategorien und
theoriegeleiteten formalen Kategorien. [44]
Strikt formale Kategorien wären demnach Kategorien, die Phänomene auf der sprachlichen Oberfläche betreffen. Im Gegensatz dazu haben theoriegeleitete formale Kategorien rekonstruktiven Charakter und werden vor dem Hintergrund einer bestehenden oder einer zu entfaltenden Theorie induktiv oder deduktiv entwickelt. Beide Kategorien unterscheiden sich grundsätzlich von thematischen Kategorien; sie besitzen keine themenspezifische Dimension. [45]
Strikt formale Kategorien sind in Rezeptionsstudien häufig von Bedeutung. Oft ist es hilfreich, solche streng formalen Anker zu setzen, um die theoriegeleiteten formalen Kategorien zu stützen. Beispielsweise bildete HOLDER (2019) in seiner Metaphernverstehensstudie eine Kategorie, in der Vergleichsmarker (z.B. "als ob", "wie wenn") und Uneigentlichkeitsmarker (z.B. "sozusagen") zusammengefasst sind. Mittels der Kategorie können Passagen identifiziert und verstanden werden, in denen Studienteilnehmer_innen mit gängigen sprachlichen Mitteln metaphorische Projektionen nachvollziehen. Ganz ähnlich verfährt RIST (2018, o.P.), die bei der Formulierung von Codierregeln zu ihrer Kategorie der "Vermutungen hinsichtlich [...] ungewisser Darstellungen" auch auf explizite Unsicherheitsmarker ("glaube ich", "wahrscheinlich", "könnte ... sein") zurückgreift. Die Arbeit mit theoretischen Konstrukten und ihren sehr unterschiedlichen Realisierungen macht es notwendig, formale Anker zu erkennen und sie zu kategorisieren. [46]
Theoriegeleitete formale Kategorien stehen häufig im Zentrum von Rezeptionsstudien. Beispielsweise bildet STILLER (2017) eine ganze Reihe solcher Kategorien, darunter "Globale Kohärenz herstellen" (S.110). Um zu entscheiden, ob Studienteilnehmer_innen globale Kohärenz bilden, ist eine theoriegeleitete Interpretation notwendig. Bei sprachlich-kognitiven Rezeptionsaktivitäten, die im Fokus deutschdidaktischer Rezeptionsstudien stehen, handelt es sich sehr oft um Phänomene, die in dieser Form zu analysieren sind: STARKs "elaborative Reparaturen" (2017, S.137) und RISTs "Vermutungen hinsichtlich rezipientenseitig ungewisser Darstellungen" (2018, o.P.) sind ebensolche Kategorien. Die vorgeschlagene Differenzierung in der Systematik der formalen Kategorienarten ist in Tabelle 1 zusammengefasst.
|
Sub-Typen der formalen Kategorien nach SCHREIER (2014) |
Merkmale |
|
strikt formale Kategorien |
zielen auf unmittelbar beobachtbare Merkmale an der sprachlichen Oberfläche des Datenmaterials (z.B. Hesitationen, Pausen, Modus) |
|
theoriegeleitet formale Kategorien |
zielen auf nicht inhaltsbezogene Merkmale von Rezeptionszeugnissen, die unter Zuhilfenahme von (Kommunikations-, Textverstehens- o.a.)Theorien identifiziert werden können (z.B. Verletzung von Kommunikationsmaximen, Etablierung globaler Kohärenz) |
Tabelle 1: strikt formale und theoriegeleitet formale Kategorien [47]
4.2 Differenzierungsvorschlag 2: "prozessbezogene" und "dispositionsbezogene Kategorien"
Eine weitere Unterscheidung, die quer zu den Fragen nach induktiver oder deduktiver Kategorienbildung oder nach oberflächenorientierten vs. rekonstruktiven formalen Analysen liegt, erscheint aus literaturdidaktischer Sicht sinnvoll: Während mit den bis hierhin diskutierten Kategorien wie "Inferenzen", "elaborative Reparaturen" oder "globale Kohärenzbildung" Prozesse erfasst werden sollen, zielt man mit anderen Kategorien wie "Textsortenwissen" oder "Kenntnis literarischer Fachbegriffe" (STILLER 2017, S.111) auf grundlegende Dispositionen der Rezipient_innen. [48]
Da die Dispositionen der Rezipient_innen noch latenter sind als die durch sie ermöglichten Prozesse, lassen sich für ihre Rekonstruktion nur sehr selten Anker an der Oberfläche der Äußerungen finden. Sie ist in noch stärkerem Ausmaß auf den Rückgriff auf theoretische Modelle sprachlicher Kognition (z.B. TOMASELLO 1999) und insbesondere literarischer Textverstehenskompetenzen angewiesen. So entwickelt etwa STILLER (2017) ihr Kategoriensystem literarästhetischer Verstehenskompetenzen von Viertklässler_innen deduktiv im Rückgriff auf das LUK-Modell (DICKHÄUSER et al. 2008),8) modifiziert es jedoch im Zuge der Datenanalyse und passt es den Erfordernissen der vorgefundenen Phänomene an. In ihrem Kategoriensystem entsprechen die Oberkategorien den drei Dimensionen des literarästhetischen Urteilens: dem "semantischen literarästhetischen Textverstehen", dem "ideolektalen literarästhetischen Textverstehen" und dem "kontextuellen literarästhetischen Textverstehen". In jeder dieser Dimensionen werden weitere Unterscheidungen vorgenommen. So wird beim letzten Bereich zwischen dem "Herstellen intertextueller Bezüge", dem "literarischen Fachwissen" und dem "Weltwissen" unterschieden. [49]
Diese Bereiche des Kontextwissens werden weiter in Subkategorien ausdifferenziert. Im Fall des "literarischen Fachwissens" sind es
Textsortenwissen und
Kenntnis literarischer Fachbegriffe. [50]
Die folgenden Daten wurden mit der Kategorie "Textsortenwissen" versehen. Entstanden sind sie auf der Basis der Lektüre des Gedichts "Die Geschichte vom Wind" (GUGGENMOS 2001):
"Das ist ein Gedicht. 'Da war der Wind noch ein Kind, aber dann, in der Nacht, wurde aus dem Kind ein Mann.' Das reimt sich" (STILLER 2017, S.160).
"Mir gefällt der Text mit dem Ende. Und das klingt beim Lesen schön. Und es ist so mit einem Spannungsbogen" (S.162). [51]
Im ersten Fall, so STILLER, wird von einer Texteigenschaft, dem Reim, auf eine Textsorte geschlossen. Im zweiten wird das Gedicht als Geschichte aufgefasst. Dabei wird eine Eigenschaft von Geschichten, der Spannungsbogen, hervorgehoben. In beiden Fällen wird auf literarisches Fachwissen geschlossen. Die Codiereinheit als Indiz für die Fähigkeit der Rezipientin, literarisches Fachwissen anzuwenden, ist eindeutig ein theoriegeleiteter, interpretativer Akt der Rekonstruktion einer Disposition. [52]
Die Rekonstruktion von Dispositionen führt zu einem anderen analytischen Vorgehen, als dies oben für die Rekonstruktion von Prozessen geschildert wurde. Während Prozesse zeitlich begrenzt sind, muss im Falle von Dispositionen davon ausgegangen werden, dass diese während des gesamten Rezeptionsprozesses (sowie davor und danach) in gleichem Maße ausgeprägt oder nicht ausgeprägt sind. Das bedeutet, dass zwar einzelne Codiereinheiten, in denen eine hohe Konzentration der besagten Indizien auszumachen ist, entsprechend codiert werden können – doch darf dabei der Rest der von der rezipierenden Person gewonnenen Daten nicht aus dem Blick verloren werden: Wenn eine Leserin bekundet: "fünf freunde kenn ich, die hab ich als kind schon gehört" (CARL i.V.), dann ist diese Information für das gesamte folgende Laut-Denk-Protokoll zu berücksichtigen (etwa wenn die Teilnehmerin statt "Georg", wie in der Buchvorlage vorzufinden, die Figur englisch "George" ausspricht – es ist hier also anzunehmen, dass sie dies tut, weil sie sich an gehörte Hörspiele oder gesehene Fernsehserien erinnert). Die Rekonstruktion von Rezeptionsdispositionen erfordert also immer wieder ein Durchlaufen des hermeneutischen Zirkels: Die einzelne Codiereinheit ist im Abgleich mit der gesamten Analyseeinheit zu codieren; das resultierende Urteil bleibt auch im Folgenden bedeutsam. Ändert sich nach genauer Analyse weiterer Codiereinheiten das Gesamturteil, so müssen auch bereits erfolgte Codierungen von Dispositionen neu überprüft werden. [53]
Während der letztgenannte Umstand die Rekonstruktion von Dispositionen in literaturdidaktischen qualitativen Inhaltsanalysen anspruchsvoll gestaltet, deutet sich im letzten Beispiel allerdings auch die Möglichkeit eines kombinierenden Rückgriffs auf Verfahren thematischer Kategorisierung (KUCKARTZ 2018) an. Die unterschiedlichen Charakteristika und Anforderungen prozess- und dispositionsrekonstruktiver Kategorien in literaturdidaktischen Rezeptionsstudien lassen sich an den beiden "Dimensionen" (SCHREIER 2012, S.84) von CARLs Studie (i.V.) verdeutlichen. CARL untersucht Laut-Denk-Protokolle von Schüler_innen zehnter Klassen sowie von Lehramtsstudent_innen, die je drei kurze Prosatexte lesen, einerseits auf die mentalen Repräsentationen hin, die zum Text gebildet werden (GOLDMAN & VAN OOSTENDORP 1998; KINTSCH & VAN DIJK 1983), andererseits auf die Strukturen des dabei aktivierten Vorwissens hin. Alle von CARL gebildeten Kategorien gehören zum Typus der theoriegeleiteten formalen Kategorien. In der ersten Dimension, mit der mentale Textrepräsentationen erfasst werden sollen, werden in einer formalen Inhaltsanalyse anhand ausschließlich deduktiv gebildeter Kategorien Prozesse rekonstruiert (so gilt z.B. das reine Paraphrasieren von Propositionen des gelesenen Textes als Indiz für die Beschäftigung mit der "Textbasis" i.S. von KINTSCH & VAN DIJK 1983). In der zweiten Dimension geht es um das Vorwissen, also um eine Disposition; hier wird bei der induktiven Rekonstruktion der Strukturen dieses Vorwissens auch auf inhaltliche bzw. thematische Aspekte der lauten Gedanken der Teilnehmer_innen zurückgegriffen. [54]
Die vorgeschlagene Differenzierung der Vorgehensweise von qualitativen Inhaltsanalysen in literaturdidaktischen Rezeptionsstudien, je nachdem, ob mit ihnen auf die Rekonstruktion von Prozessen oder von Dispositionen gezielt wird, ist in der folgenden Tabelle 2 zusammengefasst:
|
Ziel der qualitativ inhaltsanalytischen Rekonstruktion |
Resultierende Anforderungen an das qualitativ inhaltsanalysche Vorgehen |
|
Rezeptionsprozesse |
zeitlich / lokal begrenzt → Segmentierung der Analyseeinheit beim Codieren unproblematisch; |
|
Dispositionen |
über längere Zeiträume stabil → ggf. immer wieder Gesamtbetrachtung der Analyseeinheit notwendig; |
Tabelle 2: Prozessbezogene und dispositionsbezogene Kategorien [55]
Beide hier vorgeschlagenen Antworten auf die doppelt-hermeneutische Herausforderung vereinfachen qualitative Inhaltsanalysen im Rahmen von Rezeptionsstudien nicht unbedingt: Umfangreiche Kontexteinheiten zu berücksichtigen erhöht den Codieraufwand beträchtlich gegenüber einer Vorgehensweise, bei der die Kontexteinheit in der Regel nicht größer als die Analyseeinheit ist. Auch der Vorschlag, zwischen oberflächenstrukturell-formalen und rekonstruktiven Kategorien sowie unter den rekonstruktiven Kategorien nochmals zwischen prozess- und dispositionsrekonstruktiven Kategorien zu unterscheiden und für letztere ein wiederholtes Durchlaufen des hermeneutischen Zirkels während des Codierens nahezulegen, muss sich zuerst mit den Forderungen nach einem exhaustiven System disjunkter, gesättigter Kategorien und der durchgängigen Orientierung an der jeweiligen Forschungsfrage in Einklang bringen lassen. [56]
Dennoch erscheinen uns beide Vorschläge zur Vorgehensweise angebracht, zumal die eingangs konstatierte große Popularität der qualitativen Inhaltsanalyse in literaturdidaktischen Rezeptionsstudien sich möglicherweise weniger ihrem Potenzial zur ökonomischen Datenreduktion verdankt als ihrer Orientierung an der Herstellung von Systematik und ihrer Anschlussfähigkeit an modellbildende Diskurse (vor allem an den Diskurs über literarische Rezeptionskompetenzen). Unter diesem Aspekt lassen sich unsere Vorschläge bezüglich der Kontexteinheit und unsere Reflexionen über häufig verwendete Verfahren der Kategorienbildung auch als Anstoß lesen, das Herzstück der qualitativen Inhaltsanalyse – das Codieren von Textsegmenten – um kontext- und fallbezogene Überlegungen zu erweitern, ohne die Systematizität (STAMANN, JANSSEN & SCHREIER 2016) und die Anschlussfähigkeit an Mixed-Methods-Designs preiszugeben. [57]
Insbesondere mit Blick auf den letztgenannten Aspekt wäre zu überlegen, inwiefern die hier entfalteten Überlegungen – nach notwendigen Anpassungen im Detail – sich auch auf andere deutschdidaktische qualitativ inhaltsanalytische Studien (etwa zur Argumentations- oder Schreibkompetenz) sowie auf Forschungsvorhaben in anderen Fachdidaktiken übertragen lassen. [58]
Für kritische Hinweise und Orientierung bei der Entstehung unseres Artikels bedanken wir uns bei Markus JANSSEN und Christoph STAMANN, den Leitern der Forschungswerkstatt qualitative Inhaltsanalyse an der Pädagogischen Hochschule Weingarten. Dank sei auch Katharina RIST für Einblicke in die Daten ihres laufenden Dissertationsprojekts sowie Christopher KLEBER für umfassende Hinweise zur Erforschung von Inferenzen.
1) Die dargestellten Daten stammen aus einem aktuellen Forschungsprojekt von Mark-Oliver CARL. <zurück>
2) Eine referenzidentitätskonstatierende Paraphrase ist eine umschreibende Wiedergabe des gelesenen Textes, die die Erkenntnis verdeutlicht, dass sich zwei oder mehr gelesene Begriffe (hier könnte es sich z.B. um "Tim" und "der Hund" handeln) auf dasselbe Objekt beziehen. <zurück>
3) Dabei ist allerdings zu berücksichtigen, dass LESSING-SATTARI und WIESER (2016) ebenso wie STARK (2017) selbst nicht mithilfe der qualitativen Inhaltsanalyse auswerten, sondern im ersten Fall anhand der dokumentarischen Methode, im zweiten im Rahmen der Grounded-Theory-Methodologie. <zurück>
4) Aus LOEST (1979), zit. n. STARK (2017, S.132f.). <zurück>
5) Das Zeichen "(.)" steht für eine einsekündige Pause, das Zeichen "/" für den Abbruch eines Wortes. <zurück>
6) Für die Genehmigung der Veröffentlichung des Bildes danken wir dem Gerstenberg-Verlag. <zurück>
7) Alternativ ließe sich auch der umgekehrte Weg wählen, bei dem KUCKARTZ' analytische Kategorien anhand von SCHREIERs weiter gefasstem Verständnis formaler Kategorien noch ausdifferenziert werden in thematisch-analytische und formal-analytische Kategorien. <zurück>
8) LUK steht für "Literarästhetische Urteilskompetenz". Mit dem LUK-Modell werden literarästhetische Textverstehenskompetenzen erfasst. <zurück>
Becker, Aaron (2015). Die Reise. Hildesheim: Gerstenberg.
Blyton, Enid (1954 [1944]). Fünf Freunde auf geheimnisvollen Spuren (übers. v. W. Lincke). Hamburg: Blüchert.
Braaksma, Martine; Janssen, Tanja & Rijlaarsdam, Gert (2006). Literary reading activities of good and weak students. A think aloud study. European Journal of Psychology of Education, 21(1), 35-52.
Bromme, Rainer & Stadtler, Marc (2014). The content-source integration model: A taxonomic de-scription of how readers comprehend conflicting scientific information. In David N. Rapp & Jason L. G. Braasch (Hrsg.), Processing inaccurate information. Theoretical and applied perspectives from cognitive science and the educational sciences (S.379-402). Cambridge, MA: MIT Press.
Bromme, Rainer; Scharrer, Lisa; Skodzik, Timo & Stadtler, Marc (2014). Comprehending multiple documents on scientific controversies: Effects of reading goals and signaling rhetorical relationships. Discourse Processes, 51(1-2), 93-116.
Carl, Mark-Oliver (2018). Stolpern oder jonglieren, staunen oder spielen? Eine kognitionspsychologische wie hermeneutische Kritik der ästhetischen Theorie analogischen Verstehens. In Daniel Scherf & Andrea Bertschi-Kaufmann (Hrsg.), Ästhetische Rezeptionsprozesse in didaktischer Perspektive (S.41-55). Weinheim: Beltz.
Carl, Mark-Oliver (in Vorbereitung). Vorwissen und Modellierung kommunikativer Kontexte beim Lesen literarischer Texte. Eine Laut-Denk-Studie mit Schüler*innen zehnter Klassen und Lehramts-Studierenden. Habilitationsschrift, Universität zu Köln.
Consten, Manfred & Schwarz-Friesel, Monika (2014). Einführung in die Textlinguistik. Darmstadt: Wiss. Buchgesellschaft.
Dannecker, Wiebke (2016). Lautes Denken. Leise lesen und laut denken. Eine Erhebungsmethode zur Rekonstruktion von "Lesespuren". In Jan Boelmann (Hrsg.), Empirische Erhebungs- und Auswertungsverfahren in der deutschdidaktischen Forschung (S.131-146). Baltmannsweiler: Schneider Hohengehren.
Dickhäuser, Oliver; Frederking, Volker; Meier, Christel & Stanat, Petra (2008). Ein Modell literarästhetischer Urteilskompetenz. Didaktik Deutsch, 13(2), 11-31.
Führer, Carolin (2013). Transformationen des Deutschunterrichtes. Interviewstudien zu Selbstkonzepten, Kultur- und Geschichtsbewusstsein in Ostdeutschland. Wiesbaden: Springer VS.
Gailberger, Steffen & Holle, Karl (2010). Modellierung von Lesekompetenz. In Anja Ballis & Cordula Löffler (Hrsg.), Lese- und Literaturunterricht (S.269-323). Baltmannsweiler: Schneider Hohengehren.
Garz, Detlef (2007). Qualitative und/oder/versus rekonstruktive Sozialforschung, das müsste heute die Frage sein. Erwägen – Wissen – Ethik, 18(2), 224-226.
Goer, Charis (2014). Fachdidaktik Deutsch. Grundzüge der Sprach- und Literaturdidaktik. Paderborn: Fink.
Goldman, Susan & McCarthy, Kathryn (2015). Comprehension of short stories. Effects of task instructions on literary interpretations. Discourse Processes, 52(7), 585-608.
Goldman, Susan R. & Van Oostendorp, Herre (1998). The construction of mental representations during reading. Mahwah, NJ: Erlbaum.
Groeben, Norbert & Rustemeyer, Ruth (2002). Inhaltsanalyse. In Eckard König & Peter Zedler (Hrsg.), Qualitative Forschung. Grundlagen und Methoden (S.233-258). Weinheim: Beltz.
Guggenmos, Josef (2001). Geschichte vom Wind. In Josef Guggenmos, Was denkt die Maus am Donnerstag? 121 Gedichte für Kinder (S.72-73). München: Deutscher Taschenbuchverlag.
Heins, Jochen (2017). Lenkungsgrade im Literaturunterricht. Zum Einfluss stark und gering lenkender Aufgabensets auf das Textverstehen. Wiesbaden: Springer VS.
Hoffmann, Jeanette (2013). "Vielleicht sehnt der sich nach Sonne ..." – Entfaltung von Perspektiven im Gespräch zum Bilder(buch)kino einer vielstimmigen Geschichte. In Christoph Jantzen & Stefanie Klenz (Hrsg.), Text und Bild – Bild und Text. Bilderbücher im Deutschunterricht (S.37-72). Stuttgart: Klett.
Holder, Friedemann (2019). Wege zum Metaphernverstehen. Ein zeichenübergreifender Ansatz zur Didaktik der Metapher mit empirischer Fundierung. Baltmannsweiler: Schneider Hohengehren.
Hsieh, Hsiu-Fang & Shannon, Sarah E. (2005). Three approaches to qualitative content analysis. Qualitative Health Research, 15(9), 1277-1288.
Johnson, Mark & Lakoff, George (2016). Why cognitive linguistics required embodied realism. In Masaaki Yamanashi (Hrsg.), Cognitive linguistics (Bd. 1, S.137-154). Thousand Oaks, CA: Sage.
Kintsch, Walther & Van Dijk, Teun A. (1983). Strategies in discourse comprehension. New York, NY: Academics.
Köppe, Tilmann & Winko, Simone (2013). Neuere Literaturtheorien. Eine Einführung (2., akt. und erw. Aufl.). Stuttgart: Metzler.
Krippendorff, Klaus (2004). Content analysis. An introduction to its methodology. Thousand Oaks, CA: Sage.
Kruse, Jan (2014). Qualitative Interviewforschung. Ein integrativer Ansatz. Weinheim: Beltz Juventa.
Kuckartz, Udo (2018). Qualitative Inhaltsanalyse. Methoden, Praxis, Computerunterstützung (4. Aufl.). Weinheim: Beltz Juventa.
Lessing-Sattari, Marie & Wieser, Dorothee (2016). Von der Schwierigkeit, sich irritieren zu lassen. Eine literaturdidaktische Herausforderung. Literatur im Unterricht, 16(2), 127-142.
Loest, Erich (1979). Haare. In Erich Loest, Pistole mit sechzehn (S.168-177). Hamburg: Hoffmann und Campe.
Mannheim, Karl (1980). Strukturen des Denkens. Frankfurt/M.: Suhrkamp.
Mayring, Philipp (2015). Qualitative Inhaltsanalyse. Grundlagen und Techniken (12., überarb. Aufl.). Weinheim: Beltz.
Odağ, Özen (2007). Wenn Männer von der Liebe lesen und Frauen von Abenteuern ... Eine empirische Rezeptionsstudie zur emotionalen Beteiligung von Frauen und Männern beim Lesen narrativer Texte. Lengerich: Pabst.
Peskin, Joan (1998). Constructing meaning when reading poetry: An expert-novice study. Cognition and Instruction, 16(3), 235-263.
Peskin, Joan (2007). The genre of poetry: Secondary school students' conventional expectations and interpretive operations. English in Education, 41(3), 20-36.
Pieper, Irene & Strutz, Bianca (2018). "und das Ganze soll ne Metapher darstellen, aber ich weiß nicht wozu" – Irritation und literarische Verstehenshandlungen. Vortrag, Tagung "Zur Rolle von Irritation und Staunen im Rahmen (literar-)ästhetischer Erfahrung. Theoretische Perspektiven, empiriebasierte Beobachtungen und praktische Implikationen", 15.-16. März 2018, Weingarten.
Pressley, Michael & Afflerbach, Peter (1995). Verbal protocols of reading. The nature of constructively responsive reading. Hillsdale, NJ: Erlbaum.
Rist, Katharina (2018). Literarästhetische Verstehensprozesse in Bilderbuchkinogesprächen zu narrativen textlosen Bilderbüchern mit LeseanfängerInnen. Eine qualitativ-empirische Studie. Vortrag, Nachwuchsworkshop des Symposiums Deutschdidaktik, 13.-14. März 2018, Weingarten.
Saldaña, Johnny (2016). The coding manual for qualitative researchers. London: Sage.
Scherer, Gabriele; Schröder, Klarissa & Volz, Steffen (2016). "Ja, jetzt versteh' ich die Handlung mal überhaupt." Das metafiktionale Spiel mit Erzählwelten in David Wiesners Die drei Schweine in der Aneignung durch Grundschulkinder. In Gabriele Scherer & Steffen Volz (Hrsg.), Im Bildungsfokus: Bilderbuchrezeptionsforschung (S.171-185). Trier: WVT.
Schreier, Margrit (1997). Das Erkennen sprachlicher Täuschung. Über Absichtlichkeitsindikatoren beim unintegren Argumentieren. Münster: Aschendorff.
Schreier, Margrit (2012). Qualitative content analysis in practice. London: Sage.
Schreier, Margrit (2014). Varianten qualitativer Inhaltsanalyse: Ein Wegweiser im Dickicht der Begrifflichkeiten. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 15(1), Art. 18, http://dx.doi.org/10.17169/fqs-15.1.2043 [Zugriff: 3. Juni 2019].
Seyler, Daniela (2016). Die Wirkung von Aufgaben zum Figurenverstehen in kooperativen Kleingruppensettings. Vortrag, 21. Symposion Deutschdidaktik, 18.-22. September 2016, Ludwigsburg.
Singer, Murray (2007). Inference processing in discourse comprehension. In M. Gareth Gaskell (Hrsg.), The Oxford handbook of psycholinguistics (S.343-360). Oxford: Oxford University Press.
Stamann, Christoph; Janssen, Markus & Schreier, Margrit (2016). Qualitative Inhaltsanalyse – Versuch einer Begriffsbestimmung und Systematisierung. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 17(3), Art. 16, http://dx.doi.org/10.17169/fqs-17.3.2581 [Zugriff: 3. Juni 2019].
Stark, Tobias (2017). Mentale Modellbildung zwischen Stabilität und Vorläufigkeit. Zur Rolle von Vermutungen beim literarischen Lesen. In Daniel Scherf (Hrsg.), Inszenierungen literalen Lernens. Kulturelle Anforderungen und individueller Kompetenzerwerb (S.126-144). Baltmannsweiler: Schneider Hohengehren.
Stiller, Tanja (2017). Literarästhetische Verstehenskompetenz in der Grundschule. Baltmannsweiler: Schneider Hohengehren.
Stolle, Angelika (2017). Deutungsmuster von Lehrpersonen im Literaturunterricht der Oberstufe. Eine qualitative Studie. Frankfurt/M.: Lang.
Talmy, Leonard (2000). Toward a cognitive semantics. Cambridge, MA: MIT Press.
Tomasello, Michael (1999). The cultural origins of human cognition. Cambridge, MA: Cambridge University Press.
Toulmin, Stephen (1958). The uses of argument. Cambridge, MA: Cambridge University Press.
Van der Meulen, Dirk (2015). Activities of secondary and semi-expert university students during the reading of literary-historical and modern texts. A think-aloud study. Vortrag, 10. IAIMTE-Konferenz, 3.-5. Juni 2015, Odense, Dänemark.
Van Dijk, Teun A. (1980). Textwissenschaft. Eine interdisziplinäre Einführung. München: Deutscher Taschenbuchverlag.
Mark-Oliver CARL ist Vertretungsprofessor am Institut für Deutsche Literatur und ihre Didaktik an der Goethe-Universität Frankfurt am Main. Er beschäftigt sich mit dem Zusammenspiel von Wissensstrukturen, Rezeptionsstrategien und mentalen Textrepräsentationen.
Kontakt:
Mark-Oliver Carl
Institut für Deutsche Literatur und Ihre Didaktik
Goethe-Universität Frankfurt am Main
Norbert-Wollheim-Platz 1
60323 Frankfurt/M.
Tel. +49-69 798 32727
E-Mail: carl@em.uni-frankfurt.de
Friedemann HOLDER ist Akademischer Rat an der Pädagogischen Hochschule Freiburg. Er beschäftigt sich mit Rezeptionsprozessen im Zusammenhang mit literaturdidaktischen Fragestellungen, besonders mit Metaphernverstehen.
Kontakt:
Friedemann Holder
Institut für deutsche Sprache und Literatur
Pädagogische Hochschule Freiburg
Kunzenweg 21
79177 Freiburg/Br.
Tel.: +49 761-682-536
E-Mail: friedemann.holder@ph-freiburg.de
Carl, Mark-Oliver & Holder, Friedemann (2020). Qualitative Inhaltsanalyse in der literaturdidaktischen Rezeptionsforschung: über die Herausforderung, Verstehensprozesse zu verstehen [58 Absätze]. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 21(1), Art. 1, http://dx.doi.org/10.17169/fqs-21.1.3428.

Creative Commons Attribution 4.0 International License