Volume 6, No. 1, Art. 33 – January 2005
Structuring Audio Data with a "C-TOC". An Example for Analysing Raw Data1)
Stefan Hauptmann
Abstract: For the first time in the history of qualitative social research, currently available technology enables qualitative data to be analysed without the aid of transcriptions. In most cases software for Qualitative Data Analysis (QDA) is used to do this kind of research. This essay aims to show how to create a Clickable Table of Contents (C‑TOC) using Atlas.ti. On the one hand, a C‑TOC offers an overview of the qualitative material with the option of accessing single passages with a single click of the mouse. On the other hand, its elements serve as basic units for further analysis in Altas.ti. This step of transforming the raw material into a convenient structure may be a substitute for transcription in many areas of qualitative social research. The benefits are: digitalised audio data are easily accessible and always at hand (as MP3-files on a PC or Laptop, or on CD‑ROM or even on a PDA); the researcher works with the raw data, not with transcriptions; with a C‑TOC these data, unlike transcriptions, are already structured; individual segments can be accessed very easily; in the case of secondary analysis C‑TOCs help one to get back into old material by offering a table of contents together with instant access to the data themselves; working without transcriptions reduces costs.
Key words: audio data, CAQDAS, QDA-Software, Atlas.ti, Interviews, structuring of data, efficiency, research methods, secondary analysis, transcription, C‑TOC, secondary analysis
Table of Contents
1. Introduction
2. Using Digitalised Audio Data for Analysis
3. Generating a C‑TOC
3.1 Preparing the audio data
3.2 Segmenting an interview
3.3 Transfer to Altas.ti
3.4 Excursus: Working with mp3cutter and Winamp
3.5 Working with C‑TOC elements
4. Conclusion
Until now, transcribed data, or written data in general, have mostly been used to investigate social phenomena. However, given today’s information technology, the question arises as to whether alternative solutions exist. Since the technology of the past was unable to handle authentic audio data, it has been necessary to transcribe them. But transcription is only an intermediate step in qualitative social research in order to obtain a corpus of data that can be analysed, transferred etc. This intermediate process became, and still is today, an obvious step. But will it still be that obvious in future? This essay shows how using current IT in combination with an analysis method can render this step superfluous in many types of social research. [1]
As audio and video data are increasingly recorded digitally they can be treated very differently from analogue formats such as audio cassettes or video tapes. Copying, archiving, access and retrieval are much easier, and by using qualitative data analysis (QDA) software all qualitative analysis can be done with this kind of data—without the need to transfer it to text, but using the raw data themselves. [2]
Analysing such material requires breaking it down into convenient chunks. This can be done by creating a table of contents of the material. Such a "Clickable Table of Contents" (in the following: C-TOC) has two functions: first, it offers an overview of the material—in this essay interview data are used as an example—with the option of accessing the TOC chapters instantly with the click of a mouse. Second, these chapters are the source for all further analysis with QDA software. In that they are not further divisible, they represent the elementary parts of the interview—kind of "meaning unit[s]" (TESCH, 1992, p.46, citation follows KÜHN & WITZEL, 2000, [14]). Thus C‑TOCs enable a first glance at the data of research projects, and their elements provide the basis for coding, referring, and retrieval. [3]
Meaning units show elementary characteristics only if they do not exceed a certain length. Deciding the proper size is a matter for individual research projects.2) However, the whole procedure is an interpretation of the structure of the data in question. How this is done—e.g. whether segmentation is carried out according to available categories or open, or according to the layer of abstraction, etc.3) —depends on how they are to be used. [4]
In many research projects the two functions—overview of the research material with instant access on the one hand, and delivering elementary parts for analysis on the other—are sufficient reason to offer an alternative to transcription. In this essay, we show in detail how a C‑TOC is created and give an example of how its elements are used for analysis with the QDA software Atlas.ti. It is also possible to get only the overview function with freeware; how to do this will be discussed in a short excursus. [5]
2. Using Digitalised Audio Data for Analysis
A single transcribed interview has between 50 and 100 pages of text. The transcription itself does not provide any structure to the material whatsoever. As long as nobody has read through and made notes about the content, it is as unstructured as the raw audio data themselves. Furthermore, the transcription is already an analytical reduction and a first interpretation.4) When the raw data are recorded onto audio-cassettes or minidisks, they are no longer accessible, or only if time is spent on them. [6]
Access to authentic material is only possible when using the digitalised raw data as the basis for investigation. This is possible using QDA software. The use of digitalised raw data presents further advantages. The data as well as the results of analysis can be stored on computers or servers without using much hard-disc space. Hence, they can be transferred, transported and shared, which is interesting for primary as well as for secondary analysis. Researchers from different projects can access these data at all times and places. [7]
An audio file in MP3-format can be played on many different devices such as almost all computers, many PDAs (Personal Digital Assistant) or even mobile phones, and, of course, on the currently popular MP3-Players. As an MP3-file, the audio data of one interview uses only a few megabytes of disc-space. Hence, on just one CD‑ROM there is enough space for up to 100 hours of audio data. This suffices for research projects of some researchers’ entire career. Such files can be played by many software players, e.g. with the audio player that comes with MS-Windows packages. Navigation within the file is easy. By using the mouse you can scroll through the timeline of the players and access any part of the data. This is very similar to any MP3 player software. [8]
However, using retrieval techniques such as qualitative analysis is not possible. For this you need QDA software. Besides text and pictures, Altas.ti can handle many different digitalised audio and video formats, such as the MP3 format. The creation of a Clickable Table of Contents (C‑TOC) is one example of how to use this programme in order to structure raw data. To do this the interview—or other kind of data—is divided into segmental meaning units that are named in a meaningful way to describe the segments. Just like looking into a book, the C‑TOC presents an overview of the interview, and by clicking on the mouse you can instantly listen to the unit’s audio content. [9]
Furthermore, the meaning segments are the basis for all further analysis. In Atlas.ti, for example, they can be treated like chapters or even single sentences of transcribed text files. As a result, within the software these segments can be coded, relations to other segments can be built, all kinds of data such as newspaper articles, own research notes etc. may even be integrated, as well as segments from other audio or video sources. [10]
Since generating a C‑TOC is a kind of coding it may vary according to the interests and the knowledge of the analyst.4). This is not as big a problem as first appears. The very process of naming the segments enables repeated recognition. Ongoing work with the material will equip the researcher with contextual knowledge about the individual segments, and just looking at their headers will trigger recognition. This helps to reduce the original complexity of the material. However, since this first stage of research is not crucial in terms of theorising, it is possible to outsource creation of C‑TOCs, as is done with transcriptions. But unlike transcription, creating a C‑TOC does not change the original data. Hence, working with C‑TOCs, unlike transcriptions, involves working with the original data, which means that there is no danger of losing information or even of working with distorted data. [11]
Digital formats may play a major role in future qualitative social research just as they do nowadays in everyday use. Reduction processes as offered by the MP3 format (MPEG 1 Layer 3), which has been developed in the Fraunhofer Institut, are important here. With a certain kind of information compression, audio files can be reduced to a fraction of their original size. This is helpful for use with computers and other devices. A large amount of data can be stored easily. With good quality recording of material, a rate of compression of no more than 14 Megabytes per hour (STOCKDALE, 2003, p.11) is adequate. Hence, transfer within the World Wide Web as well as with flash-storages such as USB sticks or burned CD-ROMS presents no problem. There are other compression formats that permit even smaller files, but the MP3 format is currently the most common. It might be advisable to stick with MP3 for the time being. The QDA software Atlas.ti can also handle this format. [12]
Even audio data that have been recorded with audio cassettes or minidisks can easily be transferred to MP3. Different recording software is available that transfers analogue data to digital data (cf. STOCKDALE, 2003). Data on minidisks are already digitalised, but the signal must be reconverted into analogue to be put onto the computer. For this, the audio output of the minidisk recorder, or the cassette recorder respectively, must be connected to the input port of the computer. The software rerecords this signal and encodes it instantly into MP3 format. [13]
Currently, there are many devices available that can record instantly onto MP3, but in terms of microphone quality or operability under difficult circumstances, these devices are not yet as well developed as, for example, a minidisk recorder. They are mostly consumer devices and offer recording functions as additional gimmicks. However, in the near future many professional recording devices should become available. STOCKDALE (2003) shows some of those. Once recorded on these devices, the data can be transferred to a computer within seconds. [14]
Once the audio data are encoded as an MP3 file, they can be imported into Atlas.ti. However, it is not advisable to do segmentation with the software first. Rather, the structure of the interview should first be worked out on paper. To do this, the MP3 file can be played with the built-in audio player of Atlas.ti as well as with MP3-player software such as Winamp. It is crucial to have a time-counter in order to mark the important positions of the audio stream. I myself did this while playing the whole interview without major interruptions and made notes: notable changes in the narration (topics or narration-structure) according to the timeline of the software; ad-hoc naming of the parts between these changes which will become the meaning segments; while listening, some segments will create a sequential structure in which different levels are observable. There are topics that have subtopics, etc. These characteristics should be marked as different levels that, later on, will show a structure of different subdivisions as with a TOC of a book. After listening to the whole interview, the handwritten notes are the material with which the structure is built in Atlas.ti. Times should be noted fairly accurately so that the beginnings and endings of sequences can be easily located afterwards. [15]
With careful training it might be possible to structure an interview by reviewing it just two times, i.e. first listening and making notes on paper, then putting this structure into Atlas.ti. Depending on the precision required, the length of each segment, or on the recording quality of the audio material, a C‑TOC can be created by way of an initial analysis in a time span of about three or four times the length of the material itself. Compared with transcription this is a fairly short process. [16]
Although this procedure is more an interpretation than a transcription, any resultant mistakes are not as serious as with transcriptions. This is because the latter are the source on which the whole analysis depends, whereas the C‑TOC represents only a guide to the original data. If major mistakes occur in transcriptions, they may not even be recognised because the original is more or less lost. Analysis of digital audio data, on the other hand, always uses the original data. A C‑TOC is just the table of contents of these data, which does not reduce its importance; consider a heavy book without a TOC. It is true that transcription software such as Transcriber exists that can show text and play the original data as sound as the same time. But is it not even more time consuming for the research process if one has to worry about two kinds of sources? [17]
Interviews, at least ethnographical and narrative-biographical ones, have certain features that can help in the creation of C‑TOCs. A structural order of interviews can be found by referring to phenomena like openings, high peaks, narrative brackets, etc. In this respect the way in which interviews are conducted is crucial, as well as the ability of the interviewee to narrate. There are interview partners that can narrate in a very structural ways, others cannot. The C‑TOC will show the same characteristics as the person in question. In the one case it will show similarities to the TOC of a play, a drama or another form of literature. In the other case it will be very fragmented, have a sequence of meaning units that are poorly connected, be full of brackets etc. [18]
There are many ways of creating a C‑TOC. One can think of situations where those narrative structures should not be used, but the segments should rather show certain forms of content. In fields such as medicine or journalism, a structure in which the topic is clearly marked in advance and which delimits the interview’s structure may be welcome. The same goes for social research that works with already available categories5). [19]
However, in order to get a first feel of the material an openly created C‑TOC that is structured along the narration, or in which the narrator himself structures the content (SCHÜTZE, 1983), may be preferable—especially if this material is to be shared among a community of researchers that is concerned with rather different research projects. Ideally, a C‑TOC considers both the content of a narration as well as the intentions of the interviewee. However, more abstract kinds of structuring are also possible, for example for the needs of Objective Hermeneutics (ÖVERMANN, ALLERT, KONAU & KRAMBECK, 1979). [20]
In the following the text within the grey boxes shows a detailed manual of how to use the software-packages in order to create C-TOCs. These manuals are not important in order to read this essay, and can be ignored as long as the reader is not working with this software at the moment.
|
The MP3 files must be imported into Atlas.ti as with text files or other sources (see the Atlas.ti manual for this and all the other following descriptions of the software’s functions). Once the Primary Document (PD) is started in Atlas.ti, the integrated audio player plays the audio file. This audio player offers the function of delimiting the beginning and the end of single sequences during play (see the three buttons in Picture 1). After delimiting the beginning and end of a sequence, it is labelled as "Quotation". This quotation should be renamed with a meaningful expression, using the menu Quotations>Miscellaneous>Rename List Entry (as standard, each quotation of audio data is named after its PD). (There are about 30 characters available for this.) The PD must be sequenced in a linear manner from the beginning to the end, because it is not possible to sort audio files with Version 4.2. This also means when subdividing into more than one level, the higher level sequence must be done first. What this means is shown in Picture 1. The higher level segment, e.g. the segment "Contract betw. Rich and poor", must be created first, followed by the subdivisions. [21] |
After notes have been taken on paper while listening to the audio material, as shown in the grey box above, the whole interview is structured into segments. Picture 1 shows an interview with an overall length of about 7.5 minutes. It has 12 meaning segments (cf. the window "Quotations" on the bottom of the right hand side). Segments No. 2 and No 8 are both higher chapter-levels of No. 3, 4, 5, and 9, 10, 11, 12 respectively. Hence, these subdivisions further describe what is meant by "Contract betw. rich and poor" on the one hand, and "The Role of Science" on the other. In segment No. 10 ("Available Knowledge"), for example, Jeffrey Sachs speaks about available knowledge in science. This is part of segment No 8 ("The Role of Science"). The hyphens at the beginning indicate that these quotations are on level 2. A possible third chapter-level would be indicated with more hyphens at the beginning.6)
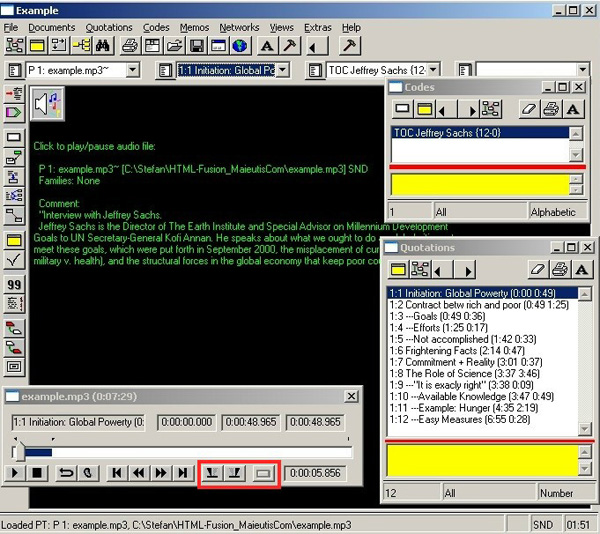
Picture 1: A C-TOC in Atlas.ti [22]
The chapter names give one an idea about the content of the interview. This is meant by open structuring, or structuring followed by the narration. An exception is segment No. 9 ("It is exactly right"). It is a noteworthy remark by the interview partner, but says nothing about the content. To use the narrator’s quotation was an ad hoc decision as often happens during segmentation—at least if one wants to do it rather quickly.7) This segment No. 9 could have been given a different name, e.g. "Indignation due to Inactivity" or similar, as the narrator is indignant in this moment. At this point it becomes clear what is meant by contextual knowledge, which the analyst applies all the time that he is working with audio data in conjunction with C‑TOCs. During analysis he may, time and again, be confronted with this passage. When he looks at the name of this chapter, he will become familiar with the fact that it is about the narrator’s indignation without listening to this passage again (even if it means just clicking on the mouse). [23]
Thus the segments can be played using the mouse. These segments, when sufficiently short and expressive, can be used for all future analyses.8) Depending on the research topic and precision requirements, new quotations (segments or chapters) might not need to be created in future. Those that have been created already may be indicative enough. Atlas.ti has many powerful functions for performing analysis. Quotations can be related to each other, or be described using notes. Longer notes can be created as memos, which may then refer to quotations (chapters) or other elements of the research project (quotations, codes, memos). Relations can be shown graphically in a network. They can be built not only within one document, but between very different documents, such as texts, pictures or video files, as long as they are imported into Atlas.ti. The relations of the whole research project can be saved in a single file that refers to very different document types. Hence, codes may refer to different documents within one project, possibly to all available data of a project. When a specific code is used for filtering, many quotations from different documents appear in a single window, and can be accessed just by clicking on the mouse. [24]
Coding is one of the main features in Atlas.ti. In Picture 1 one code is already created, which is an easy, but important one. The code "TOC Jeffrey Sachs" combines all the quotations (chapters) that have been created and designates them as parts of a table of contents of an interview with Jeffrey Sachs. This is important, because once many interviews are indexed you will have very many quotations in the quotation window; imagine that each interview might have hundreds of segments. Retrieval of the material is possible using filtering procedures. Double-clicking on the code "TOC Jeffrey Sachs" is one filtering option. Only those segments that are related to this code are shown in a pop-up window, in which they can be played.
|
In order to show only those quotations that belong to a TOC of one audio document, they need to be filtered according to the corresponding code. After segmenting the whole document this code is created as follows: Codes>Coding>Link Code to: >Quotations. Here, all those quotations are to be selected (using the mouse and shift key). The filter option can now be used to filter according to the code. Alternatively, double-clicking the code within the code-window opens another window in which you can play individual segments with one click of the mouse. [25] |
Winding through audio-cassettes to relevant parts of the documents, or merely searching huge shelves of files full of transcribed material, seems rather antiquated compared to this. In the present example, the whole project, possibly with all the field-notes, manuscripts and other research materials, is stored on a computer or a laptop, without using much space and is always available wherever you are (if using a laptop). This will even work with a rather old machine such as a Pentium II. [26]
The new version 5 of Atlas.ti allows further search options within the research material that has been created, such as notes and memos etc., which can become a huge pile of files in paper format. However, it is useful to have them as paper files as well. Atlas.ti offers some output and export formats for this. One of its new features is the ability to export XML files, which is also a universal format and may itself have many different possible uses in the near future. It might be possible, for example, to publish TOCs on the World Wide Web or on intranets. The segments are shown as a table of contents as in ordinary HTML pages of internet browsers, and the audio content can be accessed simply by clicking the mouse, just as in Atlas.ti. This would be an ideal format for sharing raw data among research communities. [27]
The files shown in Picture 1 can be downloaded at http://www.maieutis.com/, and the procedures explained above can be tried out with the Demo Version of Atlas.ti (available at http://www.atlasti.com/). [28]
3.4 Excursus: Working with mp3cutter and Winamp
If the C‑TOC’s function of giving an overview of material with the option of instant accessing the relevant passages is sufficient, it might not be necessary to use QDA software. The combination of the freely available software packages mp3cutter and Winamp may offer an alternative for those who do not want to spend much time or money to get into Atlas.ti, or those who do not run any differentiated analyses. There are, for example, professional fields that deal less with social sciences than with medicine, journalism, etc. While interviews are also important in these fields, they are not analysed in detail but serve as the source of information. Some disadvantages need to be taken into account, however, e.g. the need for more space on the hard drive. This is because the programme mp3cutter also splits the audio data "physically". This means that the more complex the structure is, i.e. the more subdivisions a document has, the more space is needed on the hard drive, as the single files are doubled, at least partly. The many different files that are cut by the software can be shown and played in the playlist of Winamp.
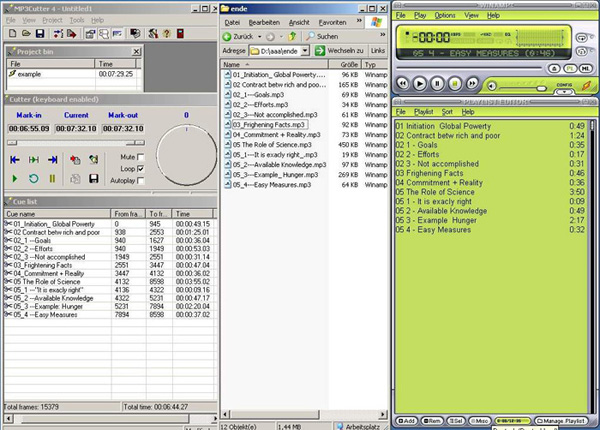
Picture 2: A C-TOC in Mp3cutter, Windows Explorer, and Winamp [29]
Picture 2 shows three different programmes. On the left hand side we have mp3cutter. The MP3 file that was used in Atlas.ti has been split into different smaller files that represent the meaning sequences and have the same name (cf. the "Cue List" on the bottom).
|
These files can be exported as MP3 files (highlight all files in the list and start the export function; for a more detailed description of mp3cutter see the programme manual) into a separate folder which should be named with the interviewee or another appropriate designation. The single files should be named so that they can be shown in the right order (see the Windows Explorer in the middle of Picture 2). The naming style shown here is only an example; other naming styles can be used, but must follow the sort function of Windows Explorer. Within the Windows Explorer highlight all files (<String> + <A>) and transfer them to Winamp (use the right hand button of the mouse and look for this function). If the structure shown is not the same as in Windows Explorer, go to <Sort> <Path and File Name (or similar)> which will sort the files correctly. [30] |
You will see the files in the playlist of Winamp. You can now click on the files and start them as in Atlas.ti. You can also navigate along the timeline of Winamp in order to wind back and forwards, using the (left hand button of) the mouse. [31]
The playlist can be printed and saved in order to open it from within Winamp. This, however, only works if the MP3 files are not moved because the playlist-function needs to find them at the original place. This procedure is rather neat in that it also offers a good overview on the structure of audio content, and easy access to its parts. However, using this option, further analyses must be carried out with means other than those offered by these software packages. It may suffice in many cases that use the applications of audio data. [32]
The programmes can be downloaded here: mp3cutter; Winamp. [33]
3.5 Working with C‑TOC elements
Beyond giving an overview of the documents, the sequences that build a C‑TOC can be reused as basic elements of many forms of analysis with Atlas.ti. Picture 3 shows an example of such an analysis within Atlas.ti. Sequences of many different interviews on the topic "neighbourhood" are correlated with an item of a quantitative survey that also asks questions about neighbourhood. In Atlas.ti a code of this survey item ("018-020 Nachbarschaft") has been built. It represents questions No 18 to 20 of a questionnaire. The questions themselves are written into the yellow field as a note (cf. the yellow field within the code window in Picture 1). Clicking on the item within the network view (Picture 3) displays these questions. The related audio sequences can also be played by clicking on them (the first number in brackets indicates the interview, and the second the sequence within the interview).
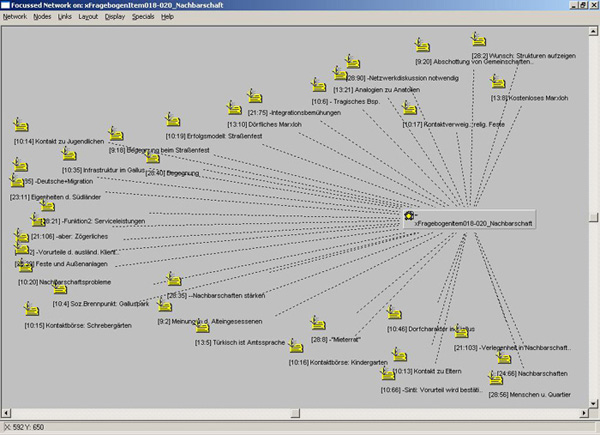
Picture 3: Network view in Atlas.ti. A Code and its Occurrences [34]
Here, direct comparison between qualitative and quantitative data is possible. Thus in the above example conclusions of a representative survey can be compared with opinions of individual persons. This does not take as long as first seems, because it is not necessary to listen to all the interviews through, nor do transcriptions need to be reread. It is sufficient to look through the C-TOCs in order to find the relevant sequences about topics which match a survey question.9) In case of doubt, when the chapter titles are not meaningful enough, those sequences can be played instantly by double clicking on the mouse. [35]
Thus once a C‑TOC is created, the data structure is shown and the data themselves can be accessed quickly and easily. Unlike a transcription, a C‑TOC is just a guide through the data—though an important one. The basic data do not change. Even if a C‑TOC offers an interpretation that differs from the ideas of the researcher, it nevertheless provides a good guide through the data. Since the sequences, and especially their names, act as reminders, a C‑TOC, by representing an order to these reminders, does its job. It creates contextual knowledge about the data. However, if the researcher does not like its designations he can easily change them. [36]
This edition of FQS deals with the topic of secondary analysis. The usefulness of C‑TOCs here is fairly obvious. They can deliver quick reminders of the data from past projects. The content of interviews which were carried out years ago can be reviewed very quickly. Another and even more useful function may be their use in shared projects. When audio data are shared among researchers—with file sharing software or through access to central servers—TOCs may help to decide whether an interview, or whatever, can be useful or not. Hence, C‑TOCS could serve as a part of an infrastructure for sharing materials. There are some portals which offer access to research material (for example SozioNet or the UK Data Archive), but much work remains to be done (cf. the dream of FIELDING, 2000, [25]). However, raw audio data in combination with C‑TOCs could play an important role in future social research, even if many obstacles must still be overcome, e.g. handling anonymity (cf. PÄTZOLD, in this volume). [37]
By introducing the use of "Clickable Table of Contents" (C‑TOC) this essay has shown how to reduce the complexity of qualitative audio data to a level where they can be analysed without the need for transcription. Thus analysis of authentic research data is possible with current IT, and offers many advantages. Missing out transcription removes one source of mistakes. Retrieving authentic data means having a much greater amount of information about the phenomena in question. C‑TOCs show the way to relevant passages of the material. Its elements may be used as the basic sources for all necessary analysis procedures using QDA software. Since creating a C‑TOC is less time consuming than transcribing the material, this method is even more cost effective. [38]
Given changing attitudes towards analysing raw data, arguments and questions about the usefulness of QDA software and about the dangers of using it (cf. for instance COFFEY, HOLBROOK & ATKINSON, 1996; CAVAJAL, 2002) seem inadequate. Views should change. It is doubtful whether we can reject it if we want to carry out analysis on authentic research data. Another matter arises when we think about this kind of analysis: new kinds of profession. Just as tape recording enabled the transcription of research material, which led to the establishment of transcription as a profession, professional procedures for preparing digitalised audio material are needed. Professional in these terms means specialisation, which, on the other hand, means the possibility of outsourcing. In describing the preparation of a C‑TOC in this essay, an example was presented of this professional, essentially non-scientific activity. [39]
First, I want to thank Mr. Benito BERMEJO from Madrid who advised me some years ago to build a table of contents in Atlas.ti with the combination of quotations and codes. However, in those days this was for transcribed interviews and not raw data. Above all I want to thank Dr. Fridrik HALLSON, the then-leader of the research project Mehrdimensionale Fremdfiguren und Einstellungsfigurationen: Qualitative Analyse der Integrationsbereitschaft in der allochthonen und der autochthonen Bevölkerung at the University of Bielefeld/Germany. He gave me the freedom to experiment with QDA software in order to handle narrative biographical interviews. He also drew my attention to the publication of this thematic issue and encouraged me to contribute to the forum with this essay.
1) This is the English translation from a German text, published in FQS in January 2005. FQS thanks the author for providing the English version and Louise CORTI for copy-editing, May 2007. <back>
2) Experience shows that a sequence should be between 20 and 90 seconds. <back>
3) We may think of the narrative content, i.e. the story, on the one hand, and of the motivation of narrating in a certain manner on the other. <back>
4) The authenticity of transcribed data is especially doubtful when transcription is not carried out professionally or is carried out in a time-pressured environment. Passages that are difficult to understand are left out or over-interpreted rather than listened to several times, or even improved in terms of its audio quality, which is possible with digitalised audio material. Transcription may cause loss of information, or even worse: it may produce wrong information. <back>
5) The creation of a C‑TOC is not actually a coding procedure. One might think of open coding according to STRAUSS (1998) or, alternatively, categorising according to KÜHN and WITZEL (2000) who relate available categories to research data in order to create a database. But a C‑TOC, as used here, is less complex with respect to scientific standards. At this stage of research, it is sufficient to give each segment a meaningful name, but necessary to segment the interview without gaps. This gives the passages the characteristics of being singular, which looks more like indexing than coding, since codes are created according to common characteristics of different passages within the research material. The question of how abstract this procedure should be depends on how C‑TOCs are to be used. However, it should be borne in mind that this procedure need not to be a scientific activity, and only then is it cost effective. Thus it might prove useful for finding the content of the material rather than analytical abstractions. Only then can a C‑TOC be created in a shortish time. But nevertheless, the material’s complexity will be reduced as the researchers’ contextual knowledge and recollection come into play. <back>
6) One could also use a number structure. However, as Altas.ti always puts numbers at the beginning of each quotation—the first indicates the PD number, the second the quotation number—this would cause a confusion of different numbers. <back>
7) It is also possible to avoid ad hoc processing. But if a C‑TOC is to be no more than a pre-analysis, spending too much time with this procedure would not be advisable (cf. also Note 4). <back>
8) However, the duration of 20 to 90 seconds may be advisable for expert and narrative interviews, but with linguistic research or with conversation analysis this time span may even be too long. <back>
9) This happens in the "Quotations" window (cf. Picture 1). <back>
Carvajal, Diógenes (2002). The artisan's tools. Critical issues when teaching and learning CAQDAS [46 paragraphs]. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 3(2), Art. 14, http://www.qualitative-research.net/fqs-texte/2-02/2-02carvajal-e.htm [Date of Access: 22.08.2003].
Coffey, Amanda; Beverley Holbrook & Paul Atkinson (1996). Qualitative data analysis: Technologies and representations. Sociological Research Online, 1(1), http://www.socresonline.org.uk/socresonline/1/1/4.html [Date of Access: 16.08.2003].
Fielding, Nigel (2000). The shared fate of two innovations in qualitative methodology: The relationship of qualitative software and secondary analysis of archived qualitative data [43 paragraphs]. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 1(3), Art. 22, http://www.qualitative-research.net/fqs-texte/3-00/3-00fielding-e.htm [Date of Access: 16.10.2004].
Kühn, Thomas & Andreas Witzel (2000). Using a text databank in the evaluation of problem-centered interviews [117 paragraphs]. Forum Qualitative Sozialforschung/Forum Qualitative Social Research, 1(3), Art. 18, http://www.qualitative-research.net/fqs-texte/3-00/3-00kuehnwitzel-e.htm [Date of Access: 15.12.2004].
Oevermann, Ulrich; Tilmann Allert; Elisabeth Konau & Jürgen Krambeck (1979). Die Methodologie einer "objektiven Hermeneutik" und ihre allgemeine forschungspraktische Bedeutung in den Sozialwissenschaften. In Hans-Georg Soeffner (Ed.), Interpretative Verfahren in den Sozial- und Textwissenschaften (pp.352-433). Stuttgart: Metzler.
Schütze, Fritz (1983). Biographieforschung und narratives Interview. Neue Praxis, 13, 283-293.
Stockdale, Alan (2003). An approach to recording, transcribing, and preparing audio date for qualitative analysis, http://www2.edc.org/CAEPP/audio.html [Date of Access: 15.10.2003].
Strauss, Anselm L. (1998). Grundlagen qualitativer Sozialforschung. Datenanalyse und Theoriebildung in der empirischen soziologischen Forschung. Munich: Fink. [orig.: Qualitative analysis for social scientists]
Tesch, Renate (1992). Verfahren der computerunterstützten qualitativen Analyse. In Günter L. Huber (Ed.), Qualitative Analyse. Computereinsatz in der Sozialforschung (pp.43-69). Munich: Oldenbourg.
Stefan HAUPTMANN, Research Fellow at the Chemnitz University of Technology, currently investigating processes of introducing knowledge management instruments in German SMEs.
Contact:
Dipl.-Soc. / M.Sc. Stefan Hauptmann
Chemnitz University of Technology
Faculty of Economics and Business Administration
Institute for Personnel Management & Leadership Studies
09107 Chemnitz, Germany
Tel.: +49(0)371-531 34231
Fax: +49(0)371-531 26259
E-mail: stefan.hauptmann@wirtschaft.tu-chemnitz.de
URL: http://www.tu-chemnitz.de/wirtschaft/bwl6/mitarbeiter/stefan_hauptmann_en.php
Hauptmann, Stefan (2007). Structuring Audio Data with a "C-TOC". An Example for Analysing Raw Data [39 paragraphs]. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 6(1), Art. 33, http://nbn-resolving.de/urn:nbn:de:0114-fqs0501331.

Creative Commons Attribution 4.0 International License