Volume 6, No. 1, Art. 35 – Januar 2005
Sekundäranalyse qualitativer Daten aus Datenbanken: QUESSY als Schnittstelle zu QDA-Software-Systemen
Heiner Legewie, Nico de Abreu, Hans-Liudger Dienel, Dieter Münch,
Thomas Muhr & Thomas Ringmayr
Zusammenfassung: Datenbanken bzw. Datenbankmanagementsysteme (DBMS) bieten für die Speicherung qualitativer Daten in Archiven zur Sekundäranalyse und in größeren Forschungsprojekten große Vorteile gegenüber einer Speicherung der Daten in Dateiform. Die Nutzung von Datenbanken ist jedoch in der qualitativen Datenanalyse (QDA) bisher gering, weil die gebräuchlichen QDA-Programme nur den Aufruf von Dokumenten erlauben, die als Dateien gespeichert sind.
Um einen effizienteren Einsatz und die Vorzüge von Datenbanken bei Verwendung von QDA- Programmen zu ermöglichen, wurde von uns eine Schnittstelle zwischen den gängigsten Datenbankmanagementsystemen (u.a. MS SQL, Oracle, MySQL, MS ACCESS) und Anwendungsprogrammen konzipiert.
Der vorliegende Prototyp QUESSY.ti bietet eine solche Schnittstelle zum QDA-Programm ATLAS.ti. QUESSY.ti erlaubt die Formulierung einer Anfrage (Query) an einen Datensatz in einer Datenbank; die Datenbank-Attribute (Feldnamen) des Datensatzes können anschließend in einem Mapping-Verfahren in die "Sprache" von ATLAS.ti übersetzt und in das QDA-Programm importiert werden.
In diesem Beitrag wird nach Einführung in die Problematik die Arbeitsweise von QUESSY.ti beschrieben und es werden Ergebnisse einer internationalen online-Befragung von ATLAS.ti-Nutzern zum Bedarf und Einsatz von Datenbanken dargestellt. Abschließend werden potenzielle Anwendungsfelder der QUESSY-Technologie diskutiert.
Keywords: Datenbank-Speicherung qualitativer Daten, Metadaten, Sekundäranalyse, Schnittstelle zu QDA-Programmen, ATLAS.ti, Leserbriefe zum 11. September
Inhaltsverzeichnis
1. Problemstellung
2. Der Einsatz von Datenbanken in der qualitativen Forschung
2.1 Speicherung in Dateiform versus Datenbank
2.2 Aufbau einer Beispiel-Datenbank
3. Das Query Support System QUESSY
3.1 Arbeitsweise von QUESSY.ti
3.2 Betriebsmodi für QUESSY.ti
4. Ergebnisse einer Befragung von ATLAS.ti-Nutzern
5. Anwendungsperspektiven
Für die computerunterstützte Datenanalyse (QDA) ist es erforderlich, die zu analysierenden Ausgangs- oder Primärdokumente (Interviews, Beobachtungs- und Gesprächsprotokolle, bzw. allgemein: Text-, Bild- und Multimediadokumente) zunächst in geeigneter Form auf einem elektronischen Datenträger zu speichern. In der Regel werden als "Fälle" (Analyseeinheiten) nicht nur die betreffenden Primärdokumente gespeichert, sondern auch eine zu jedem einzelnen Dokument gehörige, mehr oder weniger große Zahl von Merkmalen oder Metadaten. Bei Interviews können z.B. folgende Metadaten von Interessen sein: Name des Interviewten (evtl. anonymisiert), Adresse, Geschlecht, Lebensalter, Schulabschluss, Sozialmilieu, Beruf des Interviewten, Ort des Interviews, Verlaufsprotokoll, transkribierter Text des Interviews, evtl. Audio- oder Videodatei des Interviews, Fotos, Merkmale zur Stichprobe und zum Inhalt des Interviews, Interviewprotokoll, Daten zum Interviewer und zur Transkription. [1]
In größeren Forschungsprojekten und vor allem in Archiven, die Datensätze aus unterschiedlichen qualitativen Studien für Sekundäranalysen zur Verfügung stellen, ist es zweckmäßig, die verschiedenen Datensätze mit ihren Primärdokumenten und Metadaten nicht einfach als Dateien auf Datenträgern abzuspeichern, sondern sich der Vorteile moderner Datenbankmanagementsysteme (DBMS) zu bedienen und die Primärdokumente und Metadaten in Projekt-Datenbanken und Archiv-Datenbanken für die Sekundärnutzung zu speichern. [2]
In Datenbanken archivierte Dokumente können allerdings nicht ohne weiteres in den verbreiteten QDA-Anwendungsprogrammen ausgewertet werden. QDA-Programme wie ATLAS.ti nutzen als Primärdokumente Dateien, die im Dateisystem eines Computer(netzwerk)s auf Festplatten, Memorysticks, CDs und DVDs gespeichert sind und per Dateinamen einem Auswertungsprojekt zugeordnet werden. In einer Datenbank gespeicherte Textdokumente müssen deshalb zunächst mit Hilfe von Suchanfragen an die Datenbank identifiziert und anschließend die für die Inhalte relevanten Datenfelder als Dateien auf dem Datenträger gespeichert werden, damit sie in das QDA-Programm importiert werden können. Eine weitere Schwierigkeit bereitet hierbei die Berücksichtigung der Metadaten, die zusätzlich zu den auszuwertenden Texten in weiteren Datenbankfeldern abgelegt sind. Aus diesen Gründen ist die Verbreitung von Projekt- und Archiv-Datenbanken in der qualitativen Forschung noch gering (s. die Befragungsergebnisse unter 4.). [3]
Um den Einsatz von Datenbanken bei Verwendung der QDA-Software ATLAS.ti zu ermöglichen, wurde in Zusammenarbeit des vom Bundesforschungsministerium geförderten Verbundprojektes Thinksupport mit der Firma ATLAS.ti Scientific Software Development GmbH das Programmsystem QUESSY.ti als Prototyp einer Schnittstelle zwischen Datenbanken und QDA-Programmen entwickelt, wobei QUESSY.ti zunächst nur für den Import von Daten in ATLAS.ti ausgelegt ist, allerdings als Schnittstelle für weitere QDA-Programme adaptiert werden kann. [4]
Im folgenden Beitrag wird zunächst die Speicherung qualitativer Daten in Dateiform der Speicherung in Datenbanken gegenübergestellt und es wird eine Beispieldatenbank vorgestellt (2.), anschließend werden die Arbeitsweise und die vorgesehenen Betriebsmodi von QUESSY.ti beschrieben (3.) und die Ergebnisse einer Befragung von ATLAS.ti-Nutzern zum Einsatz von Datenbanken dargestellt (4). Den Abschluss bilden Überlegungen zu künftigen Anwendungsfeldern der QUESSY-Technologie (5). [5]
2. Der Einsatz von Datenbanken in der qualitativen Forschung
2.1 Speicherung in Dateiform versus Datenbank
Zum Verständnis der angerissenen Problemstellung seien zunächst die beiden Strategien der Speicherung von Primärdokumenten und Metadaten erläutert. [6]
1. Qualitative Primärdokumente und ihre Metadaten werden unter geeigneten Dateinamen direkt auf dem Datenträger abgespeichert.
Eine einfache, aber begrenzte Möglichkeit der Speicherung besteht in der Verschlüsselung der wichtigsten Metadaten als Teil eines Dateinamens, z.B. für die Interviews einer Studie: Dateiname "001-AB-M-36" bedeutet "Interview 001, Stichprobe AB, männlich, 36 Jahre". Jede Analyseeinheit ist hier unter ihrem Dateinamen abgespeichert, wobei die Metadaten im Dateinamen verschlüsselt sind und die Datei das Primärdokument enthält. [7]
Für die Speicherung von Primärdokumenten mit einer größeren Zahl von Metadaten unter je einem Dateinamen pro Analyseeinheit wird jedes Primärdokument mit einem Header, d.h. einem überschriftartigen Vorspann versehen. Die folgende Übersicht veranschaulicht diese Strategie:

Übersicht 1: Verschlüsselung von Metadaten im Header (Kopf) einer Datei [Zeile 1-6], Transkription [Zeile 7-n], Verlaufsprotokoll
[Zeile n+1ff.] [8]
Eine weitere Möglichkeit besteht in der Speicherung mehrerer Dateien pro Analyseeinheit auf den Dateiträger, z. B. je einer Datei für das Primärdokument (a), für die Metadaten (b) und für ergänzende Text- und Bilddokumente (c). Hier ist es erforderlich, entweder die Einzeldateien pro Analyseeinheit durch einen gemeinsamen Namensteil kenntlich zu machen (z.B. für die Analyseeinheit 001 = Dateinamen 001a, 001b, 001c) oder die Einzeldateien zu verlinken. [9]
2. Primärdokumente und ihre Metadaten werden in einer Datenbank gespeichert.
In Datenbanken werden die Daten (Primärdokumente + Metadaten) in Form von Tabellen gespeichert, wobei pro Datensatz eine oder mehrere Tabellen angelegt werden. Eine Tabelle besteht aus m Spalten und n Zeilen, wodurch m x n Felder als separate Informationseinheiten definiert werden. Jede Zeile stellt eine Analyseeinheit dar, jede Spalte enthält eine für alle Analyseeinheiten erfasste Information. Die Primärdokumente und größere ergänzende Dateien können in einer Datenbanktabelle entweder direkt gespeichert werden oder es besteht die Möglichkeit, in den betreffenden Feldern lediglich Dateinamen zu speichern, unter denen die Dokumente zu finden sind. [10]
In der Praxis wird heute meist mit so genannten relationalen Datenbanken bzw. relationalen Datenbankmanagementsystemen (RDBMS) gearbeitet, wobei vermieden wird, zu viel Information in einer einzelnen Tabelle zu bündeln. Stattdessen wird die gesamte Information pro "Objekttyp" in möglichst kleinen Einheiten auf mehrere Tabellen verteilt, die sich über gemeinsame Spalten ("Schlüssel") miteinander verbinden lassen. Die Verwendung eigener Tabellen für verschiedene Objekttypen hat nicht nur den Vorteil einer effizienten Speicherung in der Datenbank sondern ermöglicht auch eine effiziente Wartung bei Änderungen einzelner Informationen. [11]
Die Auswahl einer der beiden beschriebenen Strategien ist abhängig von Umfang und Art der zu speichernden Daten und von den Zielsetzungen der beabsichtigten Analysen bzw. Nutzungen. In kleineren qualitativen Studien, d.h. Einzelprojekten lohnt sich der anfängliche Aufwand bei der Speicherung des Datensatzes in einer Datenbank vor Beginn der QDA gewöhnlich nicht, so dass sich eine Speicherung in Dateiform anbietet. Bei größeren Forschungsprojekten mit mehreren Datensätzen und umfangreichen Metadaten bietet sich auch für die Primäranalyse eine Speicherung der Daten in einer Projekt-Datenbank an. [12]
Der Einsatz von Datenbanken lohnt sich aber ganz besonders bei Archiven für die Sekundäranalyse qualitativer Daten, da Datenbanken speziell für die Archivpflege und -recherche entwickelt wurden. Die elektronische Archivierung und Aufbereitung von qualitativen Daten in Datenbanken wird sich aus diesen Gründen bei mittleren und großen Archiven in Zukunft durchsetzen. [13]
2.2 Aufbau einer Beispiel-Datenbank
Als Demonstrationsbeispiel für den Einsatz einer Datenbank für Sekundäranalysen dient uns eine Sammlung von je 100 deutschen und amerikanischen Leserbriefen zum 11. September 2001, die im Anschluss an die Primäranalyse (BRANDSTÄTTER 2002) in einer ACCESS- Datenbank ("9-11- ACCESS") archiviert wurde. [14]
Zur Primäranalyse wurden die Leserbriefe mit der QDA-Software ATLAS.ti ausgewertet, wobei neben Geschlecht und Wohnort der Briefschreiber auch die politische Orientierung und das Sozialniveau der jeweiligen Leserschaft der deutschen und amerikanischen Zeitungen als Metadaten berücksichtigt wurden. In der Datenbank wurden zu den Texten in vier verschiedenen Tabellen folgende Metadaten archiviert: Tabelle Leserbriefe: Leserbrief-Nr., Name, Geschlecht, Wohnort des Briefschreibers, Zeitung, Veröffentlichungsdatum und Text des Leserbriefs; Tabelle Zeitungen: Leserbrief-Nr., politische Orientierung und Sozialmilieu der Leserschaft; Kategorisierungen aus der Primäranalyse: Leserbrief-Nr., Inhalt, Emotion, Hauptakteur des jeweiligen Leserbriefs; Messdaten: Leserbrief-Nr., Zeitperiode der Veröffentlichung. [15]
Da die Informationen in einer relationalen Datenbank wie in unserem Beispiel gewöhnlich über mehrere Tabellen verteilt sind, müssen die Tabellen für die Gewinnung zusammenhängender Informationen in einer Anfrage verknüpft werden. Nehmen wir im obigen Beispiel aus der Tabelle "Leserbriefe" die Spalte Zeitung. Aus jeder der genannten Zeitungen stammen mehrere Leserbriefe. Für die Analyse ist es wichtig, demographische Angaben zur Leserschaft und zur politischen Orientierung der einzelnen Zeitungen zu kennen. In der Tabelle "Zeitungen" werden deshalb für jede der vorkommenden Zeitungen alle relevanten Informationen in je einer Zeile abgelegt. Für die Verknüpfung zweier Tabellen in einer Anfrage ist es erforderlich, dass beide Tabellen ein gemein-sames Feld ("Schlüssel") besitzen; in unserem Beispiel wurden alle Leserbriefe durchnummeriert. Die Leserbrief-Nr. wird in allen Tabellen mitgeführt und kann entsprechend bei der Verknüpfung der Tabellen als Schlüssel dienen. [16]
Die folgende Tab. 1 zeigt einen Auszug aus der (aus drei der vier Datenbank-Tabellen kombinierten) Gesamttabelle (aus Platzgründen nur 5 von 200 Zeilen und 7 von insgesamt 38 Spalten).
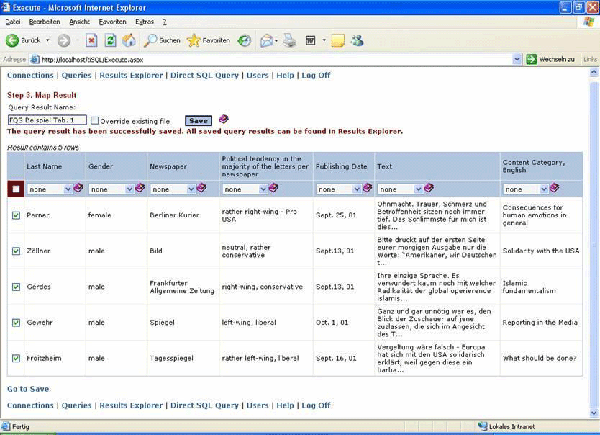
Tab. 1: Die Tabelle zeigt im oberen Teil die Benutzeroberfläche von QUESSY.ti. Darunter in Tabellenform das Ergebnis einer
Anfrage an die Datenbank 9-11-ACCESS mit 5 Leserbriefen zum 11. September aus deutschen Zeitungen (die letzte Spalte enthält
Kurzzusammenfassungen aus der Primäranalyse (BRANDSTÄTTER 2002). Bitte klicken Sie hier oder auf die Abbildung für eine Vergrößerung. [17]
Jede Zeile in Tab. 1 stellt einen Fall (Analyseeinheit) dar, jede Spalte enthält eine für alle Analyseeinheiten erfasste Information, wobei Spalte 6 den zu analysierenden Text (Leserbrief) enthält, während Spalte 1 – 5 und Spalte 7 Metadaten zu dem Text enthalten. [18]
Wichtig: An Stelle des Brieftextes selbst könnte in Spalte 6 Text auch eine File- oder URL-Adresse stehen, unter der das betreffende Textdokument entweder in einer Datei auf dem eigenen lokalen Dateisystem oder im Internet zu finden ist. [19]
3. Das Query Support System QUESSY
QUESSY ist ein Akronym für QUEry Support SYstem. Wir unterscheiden zwischen dem QUESSY-Server und dem von uns als Prototyp einer Schnittstelle zu ATLAS.ti entwickelten Programm QUESSY.ti. Der QUESSY-Server ermöglicht ganz generell die Formulierung von Suchanfragen für gängige Datenbanktypen (Datenbanken entsprechend dem SQL-Standard wie MySQL, MS Access, MS SQL, Oracle). Mit QUESSY können die Ergebnisse einer Suchanfrage durch ein so genanntes Mapping auf das Modell des Zielsystems (zurzeit ATLAS.ti) abgebildet werden. Das gemappte Resultat wird dann von QUESSY.ti im XML-Format zurückgeliefert und mit Hilfe der in ATLAS.ti integrierten Importfunktion in eine ATLAS.ti-Auswertung integriert. Mit der Entwicklung weiterer Mapping-Komponenten können auch andere Softwaresysteme in Zukunft das Resultat einer QUESSY Abfrage interpretieren. [20]
3.1 Arbeitsweise von QUESSY.ti
Im Folgenden wird die Arbeitsweise von QUESSY.ti in drei Schritten beschrieben:
1. Herstellung einer Verbindung zur Datenbank und Formulierung der Datenbank-Anfrage
QUESSY.ti ist eine Serverkomponente, auf die der Benutzer lediglich mit Hilfe eines Internet-Browsers (z.B. Internet-Explorer) zugreift. Auf dem lokalen Rechner muss also keine Installation vorgenommen werden. Je nachdem, wo der QUESSY-Server läuft (s. dazu 3. Betriebsmodi), wird zunächst entweder auf dem lokalen Rechner oder über eine URL (http://-Adresse) im Internet der Zugang (Login) zum Server hergestellt. Anschließend kann bei Vorliegen der Zugangsberechtigung eine Verbindung zur gewünschten Datenbank aufgebaut werden, wiederum entweder auf dem lokalen Rechner oder über das Internet. Hier ist anzumerken, dass sich der Ort der Datenbank und des QUESSY-Servers in der Regel unterscheiden werden. [21]
Die anschließende Formulierung einer Datenbank-Anfrage erfordert beim Nutzer Grundkenntnisse über den Aufbau der Datenbank, sowie ein allgemeines Verständnis der Funktion von RDBMS und der Anfragesprache SQL [=Structured Query Language] und ihrer semantischen Varianten. SQL stellt zwar einen Standard für die Kommunikation mit der Klasse der SQL-Datenbanken dar, es bestehen jedoch je nach Datenbank unterschiedliche SQL-Versionen bzw. "Dialekte". Mit Hilfe seines grafischen Benutzerinterface übersetzt der QUESSY-Server eine Standard-SQL-Anfrage in die SQL-Variante des jeweiligen DBMS. [22]
Zu Beginn der Anfrage werden eine oder mehrere Tabellen zum interessierenden Datensatz ausgewählt. Falls für die Abfrage mit Metadaten aus mehr als einer Tabelle gearbeitet werden soll, lässt sich vor Ausführung der Abfrage im Advanced Mode eine innere Verbindung ("Inner Join") zwischen den gewünschten Tabellen durch Definition des den gewünschten Tabellen gemeinsamen Feldes (Schlüssels) herstellen. [23]
In unserem Beispiel (Tab. 1) wählten wir aus der Datenbank 9-11-ACCESS drei Tabellen: Leserbriefe, Zeitungen, Kategorisierungen. Anschließend können wir entweder pro Tabelle alle Felder wählen (all fields) oder eine Auswahl aus den im Einzelnen aufgeführten Feldern treffen (z.B. aus der Tabelle Leserbriefe die Felder: Last Name, Gender, Newspaper, Publishing Date, Text; aus Zeitungen das Feld Political tendency ...; aus Kategorisierungen das Feld Content Category, English). [24]
Zusätzlich zur Auswahl der im Resultat anzuzeigenden Felder (Spalten) lassen sich, falls erwünscht, Auswahl-Kriterien für die "Fälle" definieren. Die Definition eines geeigneten Auswahlkriteriums (nicht zu restriktiv und nicht zu weit) ist häufig von der Werteverteilung innerhalb der Felder eines Merkmals abhängig, so dass zunächst die Tabelle ohne Anwendung eines Auswahl-Kriteriums inspiziert werden muss, bevor in einem zweiten Durchgang die gewünschte Selektion vorgenommen werden kann. In Tab. 1 haben wir diese Funktion genutzt, um mit Hilfe des Namens je einen Leserbrief pro Zeitung auswählen zu können (Kriterium: "Last Name <equal to> Perner" OR "Last Name <equal to> Zöllner" etc.). [25]
QUESSY.ti sieht vor, dass die jeweilige Abfrage abgespeichert werden kann. Dies ist wichtig für wiederholte Abfragen bei Datenbank-Tabellen, die zwischenzeitlich durch neue Einträge aktualisiert wurden. [26]
Das Ergebnis der Abfrage wird von QUESSY.ti in einer übersichtlichen Tabelle präsentiert, die eine Sichtkontrolle der Ergebnisse und eine weitere Auswahl von für die Analyse geeigneten Fällen erlaubt. [27]
2. Mapping der Ergebnistabelle für die Auswertung in ATLAS.ti
Zum so genannten Mapping, der Übersetzung der Spalten-Information in Objekte des Anwendungsprogramms ATLAS.ti benötigt der Nutzer Kenntnisse über die Repräsentationsmöglichkeiten der Metadaten in der ATLAS.ti-Welt. Die Mapping-Zuordnungen werden vom Nutzer in Dropdown-Menus des Tabellenkopfes vorgenommen (s. Tab. 2).
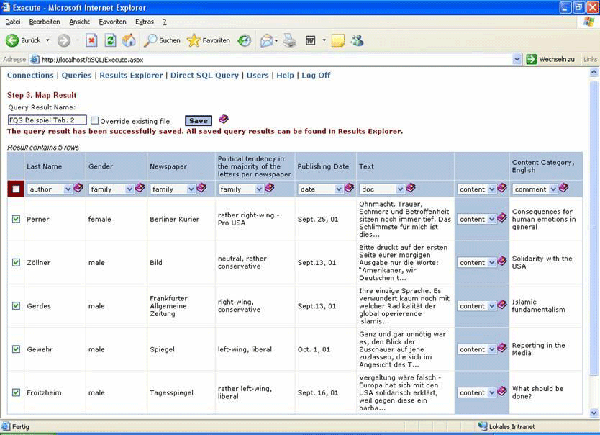
Tab. 2: QUESSY.ti Anfrage entsprechend Tab. 1. In der 2. Kopfzeile der Ergebnistabelle ist das Mapping für den Import in ATLAS.ti
ersichtlich: author, family, date, doc, content. Bitte klicken Sie hier oder auf die Abbildung für eine Vergrößerung. [28]
Der gespeicherte Text (Leserbriefe) soll in ATLAS.ti als Primärdokument analysiert werden. Entsprechend werden die Text-Einträge aus der Datenbank als "doc" (Primärdokumente) gemappt. In diesem Fall muss noch spezifiziert werden, wie das Zielsystem (ATLAS.ti) auf den Inhalt zugreifen kann. Im Beispiel ist der vollständige Inhalt im Datenbankfeld selbst gespeichert, hier wird der Mapping-Zusatz "Content" gewählt. Für große und insbesondere multimediale Inhalte wird man in entsprechenden Datenbankfeldern lediglich einen Verweis auf eine Datei im lokalen Rechnersystem (file) oder auch auf eine Internet-Adresse (url) vorfinden, was durch den Mapping-Zusatz "ref-file" bzw. "ref-url" gekennzeichnet wird. [29]
Objekte in ATLAS.ti, also auch Primärdokumente, können mit Author und Date gekennzeichnet werden. Entsprechend bietet sich an, den Namen des Briefschreibers (Last Name) als "author", das Veröffentlichungsdatum des Leserbriefes (Publishing Date) als "date" des Primärdokuments zu mappen. [30]
Da es für die QDA interessant sein kann, Leserbriefe nach Geschlecht, Zeitung und Politischer Tendenz der Leserschaft in verschiedenen Klassen (in ATLAS.ti = families) zusammenzufassen, bietet sich für die Spalten Gender, Newspaper, Political tendency das Mapping als "family" an. [31]
Zusätzlich kann jedes Primärdokument in ATLAS.ti mit einem Kommentar ("Comment") versehen werden. Hierfür bietet sich die Kurzzusammenfassung des Inhalts aus der Primäranalyse an (letzte Spalte in Tab. 2). [32]
Alle Metadaten aus Spalten, die nicht durch ein Mapping in ATLAS.ti-Objekte übersetzt werden – also auch numerische Daten – erscheinen in lesbarer Form als Header im oben erwähnten Kommentar zu den Primärdokumenten und sind damit für die QDA ebenfalls verfügbar. (Hiervon wurde in Tab. 2 nicht Gebrauch gemacht.) [33]
Nach dem Mapping wird das Ergebnis der Anfrage zunächst auf dem QUESSY-Server gespeichert und dann ins XML Format konvertiert per Download auf den lokalen Rechner übertragen, auf dem anschließend die QDA mit ATLAS.ti erfolgen soll. [34]
3. Import der Ergebnisse in ATLAS.ti
Zum Import der auf den lokalen Rechner transferierten Daten besitzt ATLAS.ti im Menu Tools den Menupunkt QUESSY.ti/Import Query Results. Seine Aktivierung in einem neu angelegten QDA-Auswertungsprojekt (= Hermeneutische Einheit) generiert anhand der QUESSY.ti-Ergebnisdatei aus den vorliegenden Leserbriefen ATLAS.ti-Primärdokumente, deren Autoren den Briefschreibern und deren Datum dem Veröffentlichungsdatum der Leserbriefe entsprechen. Gleichzeitig sind die Primärdokumente nach Geschlecht, Zeitung, Politische Tendenz in Primärdokument-Familien (d.h. nach dichotomen Attributen: male/female; Berliner Kurier/Bild; rather right wing-Pro USA/neutral, rather conservative) kategorisiert. Jedes Primärdokument enthält zudem einen Kommentar, in dessen Header die Informationen aus den nicht gemappten Spalten der Datenbank-Tabelle (bzw. Tabellen) und – in Tab. 2 – den Text aus der Spalte Content Category enthält. [35]
Die Handhabung von QUESSY.ti erscheint für den Ungeübten einigermaßen kompliziert, besonders für nicht mit der anfangs verwirrenden Tabellenstruktur von RDMBS vertraute Nutzer. Wir haben dieser Schwierigkeit durch die Entwicklung einer didaktischen Einführung Rechnung getragen, die das Arbeiten mit QUESSY.ti Schritt für Schritt in allen Einzelheiten erläutert (MÜNCH 2004). Unsere eigenen Erfahrungen zeigen zudem, dass die Handhabung der Benutzeroberfläche von QUESSY.ti nach relativ kurzer Einübung zügig und intuitiv erfolgt. [36]
3.2 Betriebsmodi für QUESSY.ti
QUESSY.ti ist ein Server-Programm, das in zwei unterschiedlichen Betriebsmodi genutzt werden kann:
1. QUESSY.ti als Internet-Angebot
QUESSY.ti kann auf einem im Internet befindlichen Server installiert werden und arbeitet dann vergleichbar einer spezialisierten Suchmaschine. Potenzielle Nutzer haben die Möglichkeit, sich per Account und Password einzuloggen und können dann Abfragen für beliebige per Internet-Adresse erreichbare Datenbanken formulieren, soweit 1) sie dem SQL-Standard entsprechen (fast alle modernen Datenbanken) und für das betreffende Datenbanksystem ein QUESSY-Zugriffsmodul existiert und soweit 2) für die Datenbank eine Zugangsberechtigung (z.B. per Account und Password) besteht. [37]
Gegenwärtig steht QUESSY.ti einschließlich eines Manuals (Schritt-für-Schritt-Anleitung, MÜNCH 2004) und der beschriebenen Demonstrations-Datenbank 9-11-ACCESS auf dem Server mit der Adresse http://quessy.atlasti.com/ allen Interessierten für einen Test zur Verfügung. Ein Aufruf von QUESSY.ti erfolgt unter dieser Adresse sowohl per Internet-Browser als auch aus ATLAS.ti 5.0 (Menu Tools/QUESSY.ti/Connect to Server). Die Zugangsdaten, mit denen Sie sich einloggen, lauten "Login: test, Passwort: test". (Achtung: Sie müssen ggfs. Cookies für diese URL zulassen!) [38]
Wir bitten alle FQS-Leser, die vom QUESSY-Test Gebrauch machen, uns über ihre Erfahrungen und evtl. Schwierigkeiten Rückmeldung zu geben. Darüber hinaus suchen wir Interessierte für einen ausführlichen ß-Test von QUESSY.ti mit eigenen Daten (Rückmeldung und Anfragen an das Projekt ThinkSupport, Christine von Blanckenburg). [39]
2. QUESSY.ti auf dem eigenen Rechner bzw. im lokalen Netz (Intranet)
Für Nutzer und Forschungsprojekte, die auf dem eigenen Rechner oder in einem lokalen Netz ein Datenbank-gestütztes eigenes Archiv für qualitative Daten betreiben oder aufbauen wollen, lässt sich QUESSY.ti unter der Adresse http://localhost/QUESSY installieren (Voraussetzung ist ein Server-fähiges Betriebssystem, z.B. Windows XP Professional, sowie ein installierter Microsoft Internet Information Server IIS). Die lokale Installation von QUESSY.ti erlaubt sowohl Anfragen an lokale Datenbanken als auch die Nutzung von Datenbanken via Internet. [40]
4. Ergebnisse einer Befragung von ATLAS.ti-Nutzern
Zur Bedarfsanalyse für eine Schnittstelle zwischen dem QDA-Programm ATLAS.ti und in Datenbanken gespeicherten qualitativen Daten wurde von uns ein interaktiver online-Fragebogen mit 38 Fragen (in englischer Sprache) entwickelt und im September an die ATLAS.ti Mailingliste (erreichbar unter http://www.atlasti.com/) verschickt. Die seit 1992 bestehende Mailingliste hat gegenwärtig weltweit ca. 1.000 User, von denen ca. 5% regelmäßig aktiv sind. Bisher erfolgte ein Rücklauf von 26 auswertbaren Fragebögen, was bei einer Mailingliste als gutes Ergebnis angesehen werden kann. Eine zweite Befragungswelle ist in Vorbereitung. [41]
Die durch die Befragung erreichten ATLAS.ti-Nutzer sind überwiegend tätig in Forschung und Entwicklung (16) und Ausbildung, Training und Beratung (7); weitere Tätigkeitsfelder (je 1 Befragter) sind Verwaltung, Klinische Psychologie, Kriminologie, qualitative Gesundheitsforschung, Archivierung, Kultur- und Umweltforschung. [42]
Im Folgenden werden die für unseren Zusammenhang wichtigen Ergebnisse referiert (trotzt geringer Fallzahlen Prozentwerte zur besseren Vergleichbarkeit). [43]
Abb. 1 dokumentiert das allgemeine Interesse der erreichten ATLAS.ti-Nutzer an einer Schnittstelle zu Datenbanken (entsprechend der Befragung englische Abbildungslegenden).
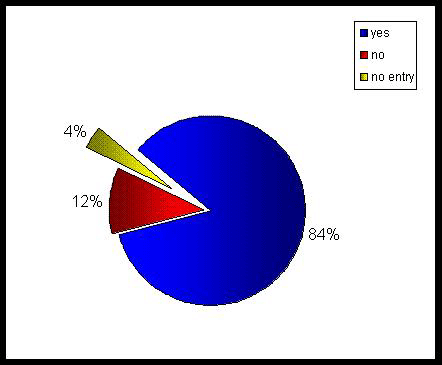
Abb. 1: Antworthäufigkeiten zur Frage: "Are you interested in an ATLAS.ti interface to import texts and description characteristics
from a database?" (N = 26) [44]
Entsprechend Abb. 2 nutzen ca. 1/3 der erreichten ATLAS.ti-Nutzer Datenbanken, um Textdokumente in ATLAS.ti zu importieren, wobei sie auf wenig komfortable Prozeduren zurückgreifen müssen. Diese hohe Zahl ist ein durchaus erstaunliches Ereignis.
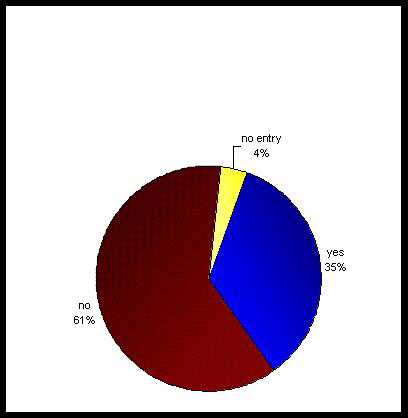
Abb. 2: Antworthäufigkeiten zur Frage: "Do you use data bases for your work with ATLAS.ti using the copy and paste functions
to import the query results or even import them 'by hand'?" (N = 26) [45]
Erstaunlich aber ist in diesem Zusammenhang ein weiteres Ergebnis: 72% der Befragten gaben an, dass sie Datenbanken einsetzen würden, wenn deren Handhabung einfacher wäre. Dazu bemerkt ein in der Ausbildung tätiger Befragter:
"Eine Anleitung, wie man einfach seine eigene Datenbank für den Einsatz mit QUESSY.ti einrichtet (z.B. auch geeignet für studentische Projekte) wäre, denke ich, sehr hilfreich." [46]
Nach Abb. 3 werden kostenpflichtige Suchdienste und Online-Archive von etwa 1/3 der Befragten genutzt.
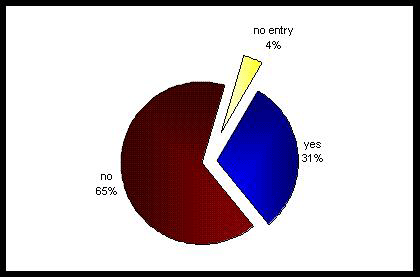
Abb. 3: Antworthäufigkeiten zur Frage: "Do you use paid search services or an online archive, that allows you to search in
several data bases?" (N = 26) [47]
Die bei Datenbank-Anfragen gesuchten bzw. gewünschten Datenarten sind aus Abb. 4 ersichtlich.
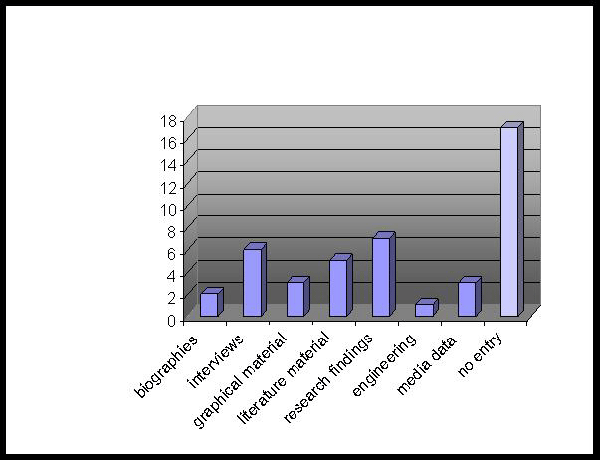
Abb. 4: Antworthäufigkeiten zur Frage: "What are the data that you would search for in the databases frequently?" (N = 26
– multiple selection possible) [48]
Von Interesse sind hier auch die offenen Antworten auf die Frage, wie die Dokumente und Metadaten aus Datenbanken genutzt werden bzw. werden sollten. [49]
Hier einige Beispiele:
"Wir haben demographische Daten zu unseren Primärdokumenten, auf die gegenwärtig nicht in ATLAS zugegriffen werden kann. Es wäre schön, wenn diese Daten direkt aus den Datenbanken übernommen werden könnten."
"Leichteres Einspielen interessanter Internet-Dokumente in ATLAS.ti (z.B. bei Diskursanalysen), Überspielen der Daten (z.B. bei Befragungen) in SPSS."
"Die Möglichkeit, bei Interviews Alter, Tätigkeiten und Typologien zu handhaben. Es gibt so viele denkbare Anwendungen."
"Ich möchte die Ergebnisse von Internet-Recherchen in Datenbanken direkt als Primärdokumente in ATLAS integrieren. Es wäre großartig, wenn man dynamische Informationen aus dem Internet handhaben könnte."
"Ich beginne gerade ein Projekt zur Analyse von Lehrbüchern für die Grundschule in Venezuela und Costa Rica (etwa 100 Bücher, die jeweils als ein Dokument gelten), wobei relevante Metadaten auftreten wie: Land, Jahr, Schulklasse und Fach."
"Für Sekundäranalysen."
"Ich wünsche mir die Möglichkeit, jedes oder alle Primärdokumente mit jeder oder allen Variablen in einer quantitativen Datenbank zu verbinden." [50]
Diese ersten Ergebnisse zeigen deutlich das Interesse an einer handhabungsfreundlichen Schnittstelle für Datenbanken. [51]
QUESSY.ti ist der Prototyp einer Schnittstelle zwischen Datenbanken und QDA-Anwendungsprogrammen, für den es unseres Wissens bisher kein Vorbild gibt. Die künftigen Anwendungsfelder für die QUESSY-Technologie sind vielfältig, wobei unterschieden werden muss zwischen dem QUESSY-Server als Recherche-Interface für SQL-Datenbanken und QUESSY.ti als Datenbank-Interface für ATLAS.ti-Anwendungen. [52]
Im Folgenden seien einige Anwendungsmöglichkeiten für die QUESSY-Technologie kurz skizziert:
Der QUESSY-Server bietet für zahlreiche SQL-Datenbanken eine gegenüber deren eigenen Abfragesprachen übersichtlichere und nutzerfreundlichere Alternative zur Datenbankrecherche, deren XML-kodierte Ergebnisse durch entsprechende Style Sheets für unterschiedliche Anwendungen – d.h. nicht nur für QDA-Programme – nutzbar sind. Für den anspruchsvollen Nutzer besteht die Möglichkeit des Direktzugriffs auf die Query in SQL Notation.
Für größere qualitative Studien und besonders für Untersuchungen, in denen pro Fall sowohl qualitative wie quantitative Daten erhoben werden, bietet sich die Speicherung der Daten in einer Datenbank an. Der QUESSY-Server kann hier eingesetzt werden, um die Daten für die Primäranalyse wie für spätere Sekundäranalysen aus der Datenbank in qualitative wie quantitative Anwendungsprogramme zu importieren.
Qualitative Datenarchive, in denen über Internet Daten für Sekundäranalysen zur Verfügung gestellt werden, können ihren Nutzern den Zugang zu ihren Datenbeständen über einen QUESSY-Server ermöglichen. Der Prototyp QUESSY.ti ermöglicht einen Direktimport der Daten in ATLAS.ti-Anwendungen.
Durch Entwicklung weiterer Mapping Module analog zu QUESSY.ti lässt sich der Einsatz des QUESSY-Servers auf alle gängigen QDA-Programme ausdehnen.
Der Einsatz des QUESSY-Servers bietet für die Internet- und Intranet-Forschung weitreichende neue Möglichkeiten. Neben Datenbank-Recherchen sind hier qualitative und qualitativ-quantitative Online-Befragungen zu nennen. Die Antworten bei interaktiven Internet- oder Intranet-Befragungen mit teilweise offenen Fragen lassen sich pro "Fall" automatisch in einer Datenbank sammeln und nach einem Screening durch QUESSY zur detaillierten Analyse in ein QDA-Programm importieren. Die gleiche Technik kann in Organisationen zum betriebsinternen qualitativen Wissensmanagement eingesetzt werden (BERKENHAGEN, DIENEL & LEGEWIE 2001).
Datenbanken mit Textdokumenten bilden die Grundlage für virtuelle Bibliotheken. Künftige Arbeitsplätze für Wissenschaftler sollten sowohl standardmäßig über Werkzeuge zum Zugang zu solchen Datenbanken verfügen wie über Tools zur Arbeit mit Texten und Multimedia-Dokumenten, d.h. mit qualitativen Daten. QDA-Programme in Verbindung mit einer Datenbank-Abfrage entsprechend der QUESSY-Technologie sind deshalb über die qualitative Sozialforschung hinaus für die Bibliothek der Zukunft und für individuelle Arbeitsplätze im Studium und in Forschung und Entwicklung gleichermaßen erforderlich.
In kleinen und mittleren Forschungsprojekten bietet der QUESSY-Server in Kombination mit einer Literatur- und Dokumentenverwaltungssoftware auf Datenbank-Basis eine einfache und komfortable Möglichkeit des integrierten Literatur- und Projektmanagements. So könnten beispielsweise mit Hilfe des Literatur- und Dokumentenverwaltungssystems Visual Composer alle projektrelevanten Daten von der Literatur bis zu qualitativen Forschungsdaten (wie Interviews oder Audio-, Bild- und Videodokumente) gemeinsam in einer ACCESS-Datenbank gespeichert und verwaltet und in Verbindung mit dem QUESSY-Server für QDA-Anwendungen genutzt werden. Ein integriertes System für die gemeinsame Archivierung von Literatur und qualitativen Daten als wissenschaftlicher Arbeitsplatz bietet den zusätzlichen Vorteil, dass auch die Literatur (Abstracts und ganze Artikel) mit QDA-Tools bearbeitet werden können.
In großen Textarchiven mit Tausenden von qualitativen Dokumenten, z.B. in virtuellen Bibliotheken, Medienarchiven oder großen Datensätzen unter Einschluss qualitativer Daten zur Verbrechens- und Terrorismusbekämpfung ist die QUESSY-Technologie in einem zweistufigen Selektionsverfahren einsetzbar: Zunächst wird anhand von Metadaten und Text-Mininig-Verfahren eine automatische Vorselektion einer kleinen Stichprobe von "Fällen" vorgenommen, die dann vom QUESSY-Server für die detaillierte "Fallanalyse" in ein QDA-Programm importiert werden kann. [53]
Die Autoren danken Dipl. Psych. Sabina BRANDSTÄTTER für die Überlassung der Datenbank 9-11-ACCESS für Test- und Demonstrationszwecke und Stud. Soz. Joscha LEGEWIE für die Erprobung des Einsatzes von QUESSY.ti als Schnittstelle zu dem Literatur- und Dokumentenverwaltungssystem Visual Composer.
Berkenhagen, Jörg; Dienel, Hans-Liudger & Legewie, Heiner (2001). Qualitatives Wissensmanagement. Forschungsüberblick und -ausblick. Sozialwissenschaften und Berufspraxis, 24, 319-341.
Brandstätter, Sabina (2002). Der 11. September: Ein qualitativer Vergleich von Leserbriefen in amerikanischen und deutschen Zeitungen. Diplomarbeit Institut für Psychologie, Technische Universität Berlin.
Münch, Dieter (2004). Guide to the Query support system QUESSY.ti. nexus Institut für Kooperationsmanagement und Interdisziplinäre Forschung Berlin (Projekt Thinksupport), http://quessy.atlasti.com/quessy/.
Heiner LEGEWIE, geb. 1937, Studium der Medizin und Psychologie. Forschungstätigkeiten an der Psychiatrischen Universitätsklinik Hamburg, dem Psychologischen Institut der Universität Düsseldorf und am Max-Planck-Institut für Psychiatrie in München. 1977-2002 Lehrstuhl für Klinische Psychologie an der Technischen Universität Berlin. Seit der Emeritierung 2002 Forschungstätigkeit am Zentrum Technik und Gesellschaft der Technischen Universität Berlin.
Arbeitsschwerpunkte: Gemeindepsychologie und Gesundheitsförderung in Stadt, Umwelt, Technik und Institutionen; Methoden der qualitativen Sozialforschung und des qualitativen Wissensmanagements
Kontakt:
Prof. em. Dr. Dr. Heiner Legewie
Zentrum Technik und Gesellschaft
Hardenbergstr. 36 A (Sek. P2-2)
D-10623 Berlin
E-Mail: Legewie@ztg.tu-berlin.de
URL: http://www.tu-berlin.de/fak8/ifg/psychologie/legewie/
Nico de ABREU, geb. 1971, Studium der Anglistik und Kunstgeschichte an der Freien Universität Berlin. Seit 2000 Mitarbeit an EU-geförderten Projekten in den Bereichen Wissensmanagement und Wissensvermittlung.
Arbeitsschwerpunkte: Computerunterstützes Lernen und Forschen, multimediale, interaktive Wissensvermittlung, Wissensmanagement.
Kontakt:
Nico de Abreu, M.A.
nexus-Institut für Kooperationsmanagement und interdisziplinäre Forschung
Hardenbergstr. 4-5
D-10623 Berlin
E-Mail: deabreu@nexus.tu-berlin.de
Hans-Liudger DIENEL, geb. 1961, Studium der Geschichte, Philosophie, Soziologie und des Maschinenbaus, MA, Dipl.-Ing., Dr.-phil., 1989-95 TU München (Zentralinstitut für Geschichte der Technik und Deutsches Museum München). Leitet seit 1996 als wissenschaftlicher Geschäftsführer das Zentrum Technik und Gesellschaft der TU Berlin und seit 1999 zusätzlich das nexus Institut für Kooperationsmanagement und interdisziplinäre Forschung Berlin.
Arbeitsschwerpunkte: Technik und Gesellschaft, Technikgeschichte, Wissens- und Kooperationsmanagement
Kontakt:
Dr. Hans-Liudger Dienel, Dipl.-Ing.
Zentrum Technik und Gesellschaft
Hardenbergstr. 36 A (Sek. P2-2)
D-10623 Berlin
nexus-Institut für Kooperationsmanagement und interdisziplinäre Forschung
Hardenbergstr. 4-5
D-10623 Berlin
E-Mail: Dienel@ztg.tu-berlin.de
URL: http://www.ztg.tu-berlin.de/
Dieter MÜNCH, geb. 1955.: Magister Artium in Freiburg im Breisgau, Promotion in Bochum, Research Fellow in Manchester und Berkeley, Habilitation in Würzburg, Privatdozent an der TU Berlin, Vertretungen an den Universitäten in Rostock und Chemnitz, seit 2001 apl. Professor am Institut für Philosophie an der TU Berlin.
Arbeitsschwerpunkte: Grundlagen der Kognitionswissenschaft, Semiotik, Philosophie der Artefakte, Anthropologie, Mediendidaktik.
Veröffentlichungen:
Intention und Zeichen. Untersuchungen zu Franz Brentano und zu Edmund Husserls Frühwerk. Frankfurt/M.: Suhrkamp 1993
(Hrsg.), Kognitionswissenschaft: Grundlagen, Probleme, Perspektiven. Frankfurt/M.: Suhrkamp 2. Auflage: 2000 (stw 989)
Rund 100 weitere Veröffentlichungen, einige davon sind ins Englische, Französische, Italienische oder Russische übersetzt
Kontakt:
Prof. Dr. Dieter Münch
nexus-Institut für Kooperationsmanagement und interdisziplinäre Forschung
Hardenbergstr. 4-5
D-10623 Berlin
E-Mail: dieter.muench@tu-berlin.de
URL: http://www.tu-berlin.de/fb1/kogwiss/
Thomas MUHR, geb. 1952, Studium der Psychologie und der Informatik an der Technischen Universität Berlin mit Schwerpunkten Kognitive Psychologie, Künstliche Intelligenz und Benutzerschnittstellen. Wissenschaftlicher Mitarbeiter im Projekt ATLAS von 1989 bis 1992. Autor des qualitativen Datenanalysesystems ATLAS.ti. Mitarbeit im Projekt A4. Ab 1994 Weiterentwicklung von ATLAS.ti zu einem der international führenden QDA-Systeme. Im Jahr 2004 Gründung der ATLAS.ti Scientific Software Development GmbH.
Kontakt:
Thomas Muhr, Dipl.-Psych. Dipl.-Inform.
ATLAS.ti Scientific Software Development GmbH
Nassauische Str. 58
D-10717 Berlin
E-Mail: thomas.muhr@atlasti.com
URL: http://www.atlasti.com/
Thomas G. RINGMAYR, erwarb seinen PhD. in Sprachwissenschaften an der University of Washington (USA). Lehrtätigkeit an verschiedenen Universitäten in den USA und an der American University in Bulgarien: Sprachen, Literatur und Cultural Studies. Gegenwärtige Tätigkeit als selbständiger Software-Entwickler und IT-Berater mit den Schwerpunkten Markup Sprachen, Web-Anwendungen und Wissensverarbeitung. Als Projektmanager war er hauptverantwortlich für Konzept, Design und Entwicklung von QUESSY. Seine Firma bietet Beratung und Kundendienste für ATLAS.ti.
Kontakt:
Dr. Thomas Ringmayr
ringmayr IT services
Bundesallee 53
D-10715 Berlin
E-Mail: mail@e.bility.com
oder thomas.ringmayr@atlasti.de
Legewie, Heiner, Abreu, Nico de, Dienel, Hans-Liudger, Münch, Dieter, Muhr, Thomas & Ringmayr, Thomas (2005). Sekundäranalyse qualitativer Daten aus Datenbanken: QUESSY als Schnittstelle zu QDA-Software-Systemen [53 Absätze]. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 6(1), Art. 35, http://nbn-resolving.de/urn:nbn:de:0114-fqs0501350.
Revised 6/2008

Creative Commons Attribution 4.0 International License